Python爬虫入门教程:下载企鹅动漫视频
好看的动漫当然要一口气看完,但是他又有广告,为了节约时间,我直接就把它们爬下来了~

本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
基本开发环境
-
Python 3.8
-
Pycharm
相关模块的使用
-
import requests
-
import re
安装Python并添加到环境变量,pip安装需要的相关模块即可。
需求数据来源分析
其实深圳腾家的视频还是比较好下载的,就是m3u8的视频格式而已,和之前爬取A站视频是一样的。



通过开发者工具这些数据内容都是可以一一抓包分析出来的,不过需要注意的是post请求的。
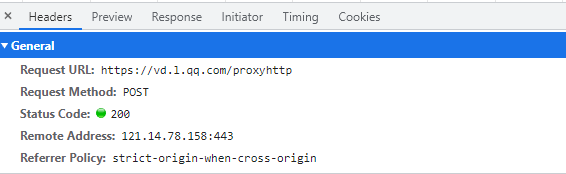

如果想要爬取多个视频的呀,他的参数主要变化的是url地址,每一集的url地址。

是通过URL编码的,通过解码可以发现其实就url地址的变化就可以爬取多个视频内容了。
兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。
那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及视频源的源代码!
还会有大佬解答!
都在这个群里了,【点我立即进裙领取】
欢迎加入,一起讨论 一起学习!
代码实现
import requests import re from tqdm import tqdm url = 'https://vd.l.qq.com/proxyhttp' data = {"buid":"vinfoad","adparam":"pf=in&ad_type=LD%7CKB%7CPVL&pf_ex=pc&url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fm441e3rjq9kwpsc.html&refer=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fm441e3rjq9kwpsc.html&ty=web&plugin=1.0.0&v=3.5.57&coverid=m441e3rjq9kwpsc&vid=m00253deqqo&pt=&flowid=6ee7a12b36edccc1298ca3c4a1279361_10201&vptag=www_baidu_com%7Cx&pu=2&chid=0&adaptor=2&dtype=1&live=0&resp_type=json&guid=4b4e192e83f4abaf8b68df3e4f5be769&req_type=1&from=0&appversion=1.0.166&uid=522810848&tkn=PZiKadvwBqjt1VRYEWFcLw..<=qq&platform=10201&opid=5FE180427A4C883F69CADDED665CE99B&atkn=49C1A486316C8D269AC65AAC080CFB29&appid=101483052&tpid=3","vinfoparam":"spsrt=1&charge=0&defaultfmt=auto&otype=ojson&guid=4b4e192e83f4abaf8b68df3e4f5be769&flowid=6ee7a12b36edccc1298ca3c4a1279361_10201&platform=10201&sdtfrom=v1010&defnpayver=1&appVer=3.5.57&host=v.qq.com&ehost=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fm441e3rjq9kwpsc.html&refer=v.qq.com&sphttps=1&tm=1633760593&spwm=4&logintoken=%7B%22main_login%22%3A%22qq%22%2C%22openid%22%3A%225FE180427A4C883F69CADDED665CE99B%22%2C%22appid%22%3A%22101483052%22%2C%22access_token%22%3A%2249C1A486316C8D269AC65AAC080CFB29%22%2C%22vuserid%22%3A%22522810848%22%2C%22vusession%22%3A%22PZiKadvwBqjt1VRYEWFcLw..%22%7D&vid=m00253deqqo&defn=&fhdswitch=0&show1080p=1&isHLS=1&dtype=3&sphls=2&spgzip=1&dlver=2&drm=32&hdcp=0&spau=1&spaudio=15&defsrc=1&encryptVer=9.1&cKey=5DdFIhZoCTh6L5EItZs_lpJX5WB4a2CdS8kEIuoKVaqtHEZQ1c_W6myJ8hQAnmDDGMN6HtSKNTvj2vPBr-xE-uhvZyEMY131vUh1H4pgCXe2Op9Lrzb_fbB32kFt6bl1q30sVBkIXYfWkOdABnbLUo4RgzSXkBHF3N3K7dNKPg_56X9JO3gwBMyBeAex05x8SbbQKY5AXaDVSM7hsBQ8XEeHzIEGJzlCt94OJgnPQjUjJKF82JUds1R0-cHhfOLSlSKkRfXJvCgPorVuLVB8vGkZ9SUNglJgQYGpVikdTUgXRIOHHObmqSLLKn4jYCmTQKXhvP_ARCxg07_d7CuHkmkZ3RplMNDtdQRyXVHoQHKn5vzNKGxIiW5AhdIEBAQEW_tymg&fp2p=1&spadseg=3"} headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36' } response = requests.post(url=url, json=data, headers=headers) html_data = response.json()['vinfo'] m3u8_url = re.findall("url(.*?),", html_data)[3].split('"')[2] m3u8_data = requests.get(url=m3u8_url).text m3u8_data = re.sub('#EXTM3U', '', m3u8_data) m3u8_data = re.sub('#EXT-X-VERSION:\d', '', m3u8_data) m3u8_data = re.sub('#EXT-X-MEDIA-SEQUENCE:\d', '', m3u8_data) m3u8_data = re.sub('#EXT-X-TARGETDURATION:\d+', '', m3u8_data) m3u8_data = re.sub('#EXT-X-PLAYLIST-TYPE:VOD', '', m3u8_data) m3u8_data = re.sub('#EXTINF:\d+\.\d+,', '', m3u8_data) m3u8_data = re.sub('#EXT-X-ENDLIST', '', m3u8_data).split() for ts in tqdm(m3u8_data): ts_url = 'https://apd-565555bc66fc61b759c9b3d174974007.v.smtcdns.com/moviets.tc.qq.com/AljnQkp9aX_s0xghcGyUDvSrsDw-60Juazgu71dVgpw8/uwMROfz2r5xgoaQXGdGnC2df645GziNP4fCTXzcc9dfItw5M/MwE4f2JnwaJD4DIrFImz_B51hCanEvH3_a3pTvopgHoqDuCXu22oHCXO-_aZh79YTmXQ-8fQX66xUs9NEzpkLfyLY5Wbes8W1mnPl983JuGgWWPVLlyh-76C2rGHa1COTMDOMc58Y6-fWzZkbfboxyd3NUyMe6tpaPBkhz2gFABB1Vjqii_6nQ/' + ts ts_content = requests.get(url=ts_url).content with open('斗罗001.mp4', mode='ab') as f: f.write(ts_content) print('下载完成')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号