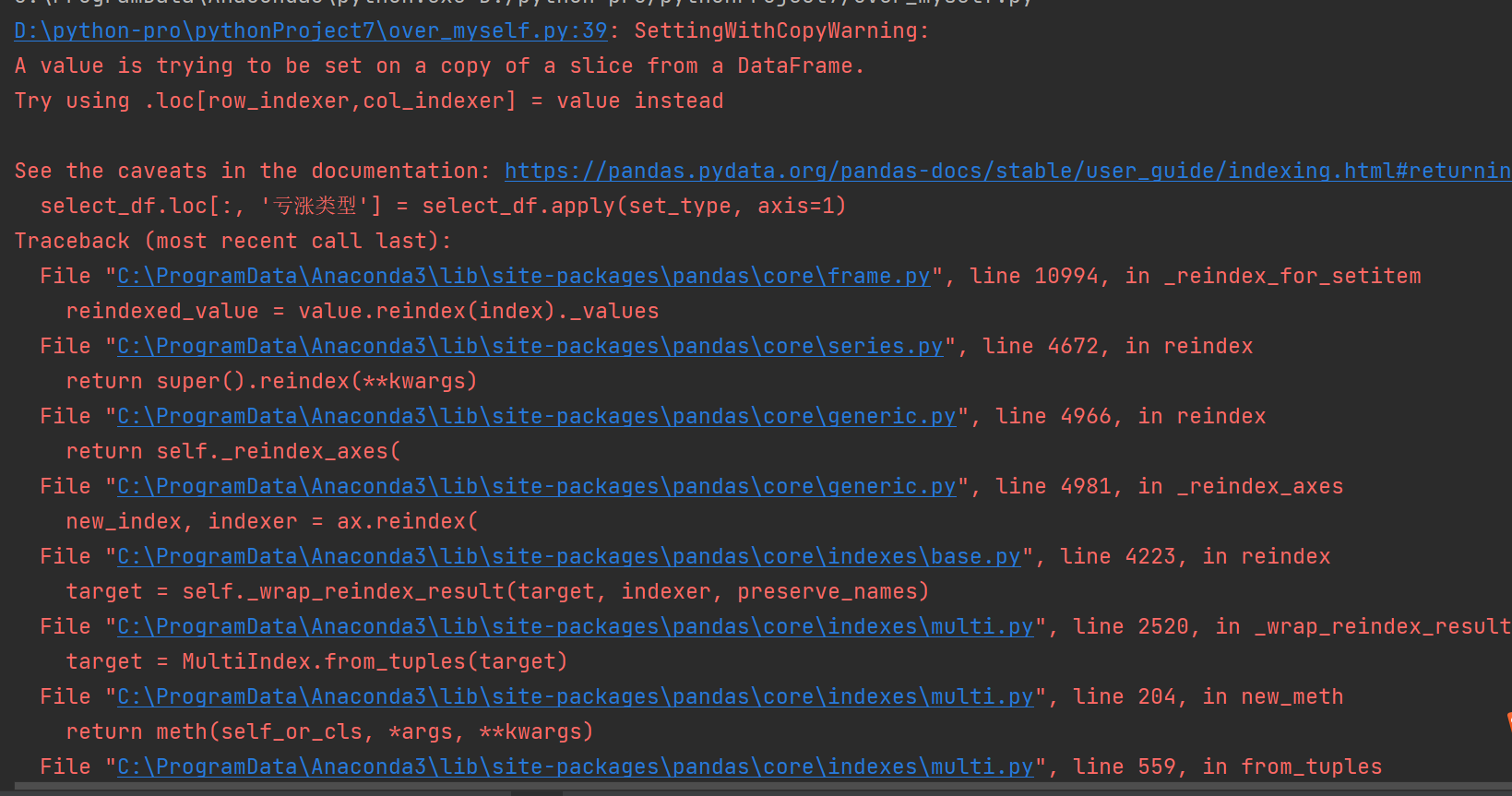
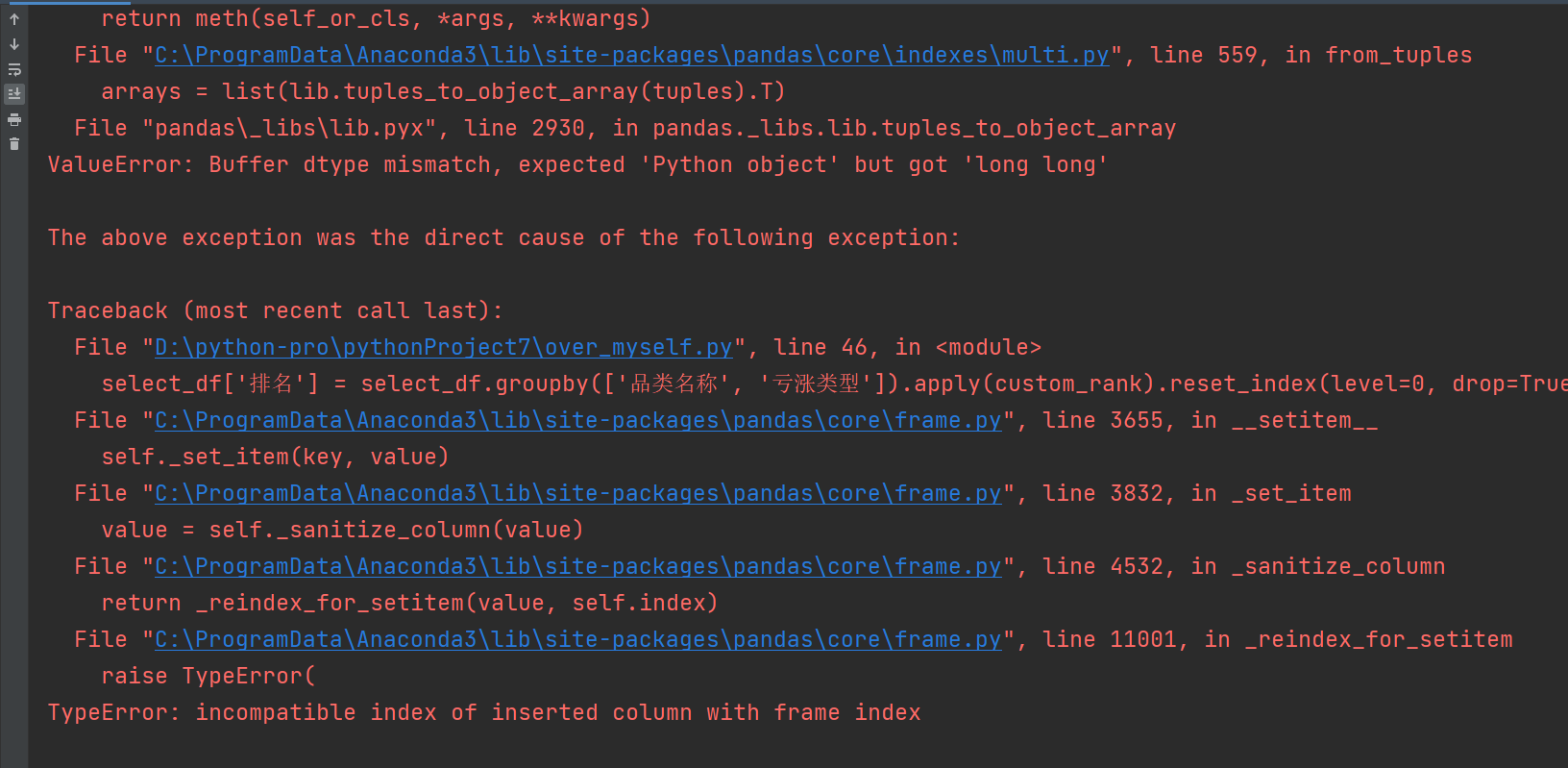
可以添加亏损和涨出 但亏损或涨出排序时报错
缺少添加新列 加上 前三的序号 和亏损盈亏
第一步 去掉多余的列 保留目标列
左边是有多余的列的效果 右边是去掉多余列的效果
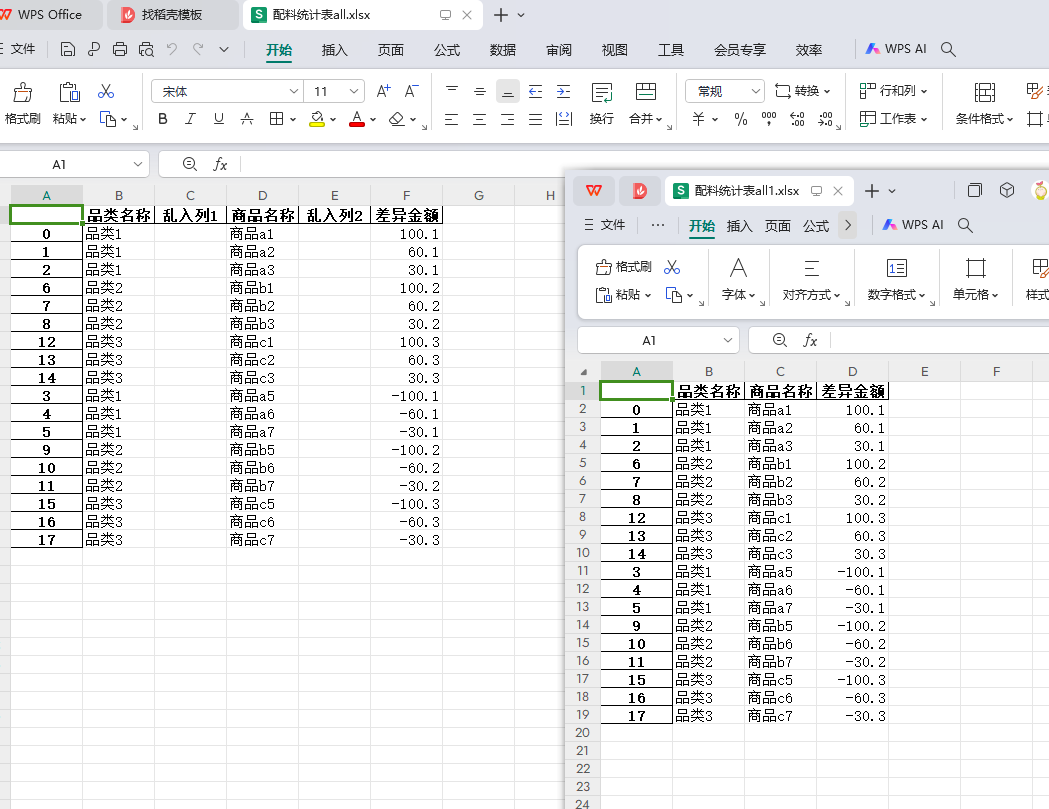
import pandas as pd # 本次过滤掉不需要的列 # 读取原始表 简化为仅求涨出和亏损前三的 # 路径需要双斜杠 data = pd.read_excel('D:\\work\\2\\配料统计表.xlsx',sheet_name='Sheet1') # 对数据做处理 # 亏损的 #第一步 找到亏损类和涨出类 如果金额大于0 是亏损;否则是涨出 data_loss= data[data['差异金额']>0] #第二步 根据品类再次分组 根据差异金额做分组groupby # 找到每个品类中亏损前三的 调用需要.head(3) 小括号不能丢 groupbyed_data_loss = data_loss.groupby('品类名称').head(3) # 盈余的 #第一步 金额小于0 涨出 data_gain= data[data['差异金额']<0] #第二步 根据品类再次分组 根据差异金额做分组groupby # 找到每个品类中亏损前三的 调用需要.head(3) 小括号不能丢 groupbyed_data_gain = data_gain.groupby('品类名称').head(3) # 合并涨出和亏损的数据 必须加上([数据1,数据2]) data_all=pd.concat([groupbyed_data_loss,groupbyed_data_gain]) # 过滤掉不需要的列 仅保留目标列 引用DateFrame df=pd.DataFrame(data_all) select_df=df[['品类名称','商品名称','差异金额']] # 将新数据写入新的表 select_df.to_excel('D:\\work\\2\\配料统计表all1.xlsx',sheet_name='Sheet1')
第二步 添加新列 亏损和涨出
import pandas as pd # 本次过滤掉不需要的列 # 读取原始表 简化为仅求涨出和亏损前三的 # 路径需要双斜杠 data = pd.read_excel('D:\\work\\2\\配料统计表.xlsx',sheet_name='Sheet1') # 对数据做处理 # 亏损的 #第一步 找到亏损类和涨出类 如果金额大于0 是亏损;否则是涨出 # data_loss= data[data['差异金额']>0] data_loss = data.loc[data['差异金额'] > 0, :] #第二步 根据品类再次分组 根据差异金额做分组groupby # 找到每个品类中亏损前三的 调用需要.head(3) 小括号不能丢 groupbyed_data_loss = data_loss.groupby('品类名称').head(3) # 使用.loc明确筛选操作基于原始data的行,列取全部(:表示全部列) # 后续其他操作类似地用.loc来确保操作基于原始数据进行 # 盈余的 #第一步 金额小于0 涨出 # data_gain= data[data['差异金额']<0] data_gain = data.loc[data['差异金额'] < 0, :] #第二步 根据品类再次分组 根据差异金额做分组groupby # 找到每个品类中亏损前三的 调用需要.head(3) 小括号不能丢 groupbyed_data_gain = data_gain.groupby('品类名称').head(3) # 合并涨出和亏损的数据 必须加上([数据1,数据2]) data_all=pd.concat([groupbyed_data_loss,groupbyed_data_gain]) # 过滤掉不需要的列 保留需要的列 df=pd.DataFrame(data_all) select_df=df[['品类名称','商品名称','差异金额']] # 根据亏损和涨出 添加1个列亏涨类型 并按对应数据标出 亏损 涨出 # 使用apply函数结合条件判断来添加亏涨类型列 def set_type(row): if row['差异金额'] > 0: return "亏损" return "涨出" # 新增一列名称是 亏涨类型 axis 按照行来调用set_type函数求亏还是涨 # select_df.loc[:, '亏涨类型'] 定位到 select_df 的所有行(: 表示全部行索引)以及 亏涨类型 这一列, # 然后将应用函数得到的值赋给对应的位置,这样能明确操作是基于原始 select_df 进行的,避免副本相关的歧义。 # select_df['亏涨类型'] = select_df.apply(set_type, axis=1) select_df.loc[:, '亏涨类型'] = select_df.apply(set_type, axis=1) # 再新增一列名称是 亏损里的第一第二第三 或者涨出里的第一第二第三 # 新增一列标记每个品类下是亏损或涨出里的排名 def custom_rank(group): if group.name[1] == "亏损": return group['差异金额'].rank(method='min', ascending=False) return group['差异金额'].rank(method='min', ascending=True) select_df['排名'] = select_df.groupby(['品类名称', '亏涨类型']).apply(custom_rank).reset_index(level=0, drop=True) # 将新数据写入新的表 去掉索引 index=False select_df.to_excel('D:\\work\\2\\配料统计表all6.xlsx',sheet_name='Sheet1',index=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号