记录python加excel的操作 初识pandas
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
第一步 给电脑下载了一个anaconda
第二步 更改PyCharm的解释器选择anaconda
选中系统解释器做更改 更改为目标解释器
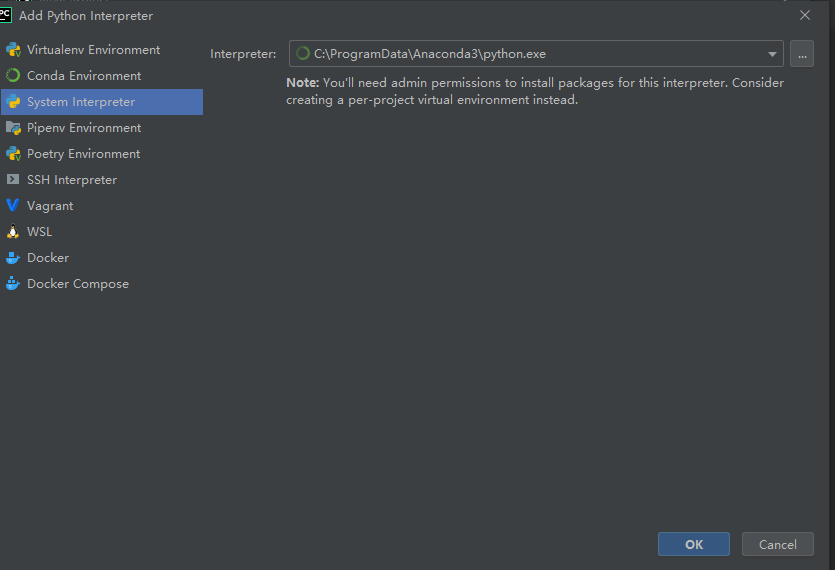
第三步 执行一个demo 提取文件内全部文件的名称
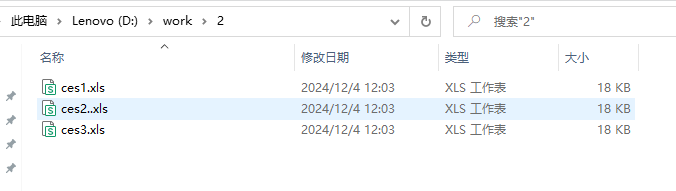
文件夹2里ces1.xls,ces2.xls,ces3.xls文件夹
python代码如下
from pathlib import Path # 导入pathlib模块中的Path 类
folder_path = Path('D:\\work\\2') # 给出要操作的文件夹路径
file_list = folder_path.glob('*.xls*')
# 获取文件夹下所有工作簿的文件路径 .glob 匹配 如果* 说明匹配所有
lists = [] # 创建一个空列表
for i in file_list: # 遍历获取的文件路径
file_name = i.name # 提取工作簿的文件名
lists.append(file_name) # 将提取的文件名添加到列表中
print(lists) # 输出提取结果
输出结果
['ces1.xls', 'ces2..xls', 'ces3.xls']
第四步 demo2 对表做排序后将数据写入新表
提示报错了


说需要安装openpyxl 库
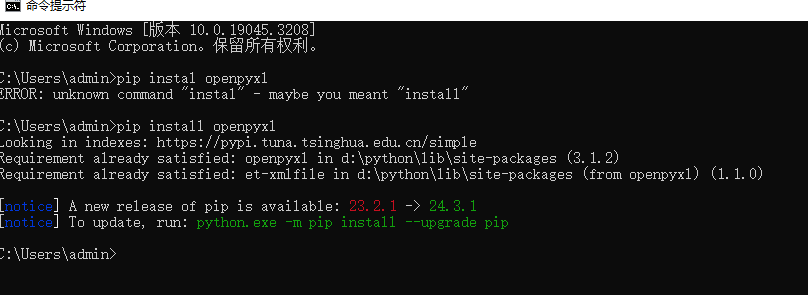
安装成功了
依旧报错

安装成功了
依旧报错
说明不能直接开始对表做分析需要先对表做操作 比如新增 修改 删除之类的 第三步卡住开始第四步
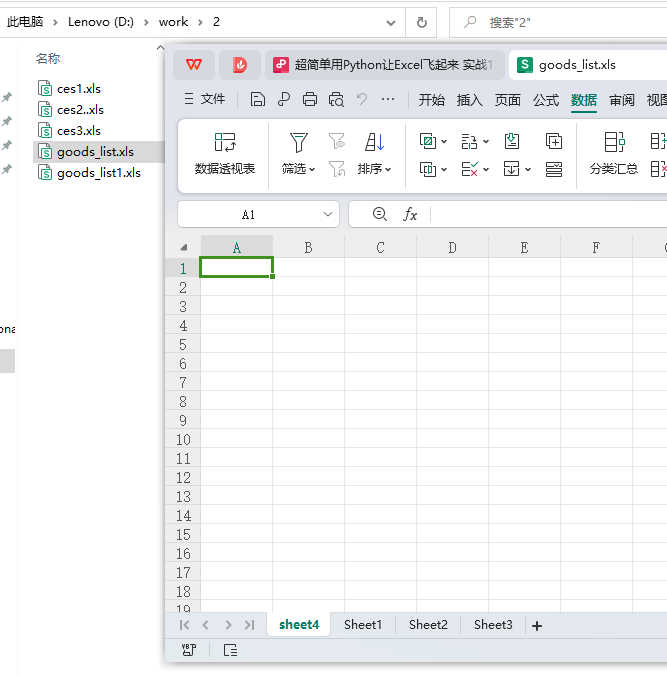
第四步 在一个.xls文件中新增一个sheet4
import xlwings as xw # 导入xlwing模块
app=xw.App(visible=False,add_book=False) # 启动Excel程序
workbook=app.books.open('D:\\work\\2\\goods_list.xls') # 打开要新增的工作表
worksheet=workbook.sheets # 获取全部工作表
new_sheet_name='sheet4'
lists=[] #创建一个空列表
for i in worksheet: # 遍历工作表
sheet_name=i.name # 获取工作簿中的工作表名称
lists.append(sheet_name) #将工作薄名称添加到列表中
if new_sheet_name not in lists: #如果工作簿中不存在名为sheet4的工作表
worksheet.add(name=new_sheet_name) #新增工作表
workbook.save()#保存工作薄
workbook.close()#关闭工作薄
app.quit() #退出excel程序
隔了多天解决了,必须后缀是xlsx 如果写入的是不存在的文件 会自动新建
import pandas as pd # 导入pandas模块 熊猫库好可爱 data = pd.read_excel('D:\\work\\1\\1.xlsx', sheet_name='Sheet1') # 读取要排序的工作表数据 data = data.sort_values(by='差异金额',ascending=False) # 按差异金额排序 降序 data.to_excel('D:\\work\\1\\1.xlsx',sheet_name='Sheet2',index=False) # 新数据写入新表中 1.xlsx 会覆盖sheet1 仅显示sheet2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号