
验证码2 成功了一半
第一步
导入第一个库 OCR 识别图像上文字的库 pytesseract ;它是Google的Tesseract-OCR引擎的Python封装
导入前需要先安装


方便理解:这个词由python中的py开头;tesseract是立方体,延伸将二维变成立方体
"tesseract"方便记忆:将单词分解为音节,例如 "tes-ser-act"。
"tes" 与 "test"(测试)联系起来,
"ser" 与 "search"(搜索)联系起来,
"act" 与 "action"(行动)联系起来。
第二步 导入处理照片的库 PIL Python Imaging Library
包括图像的打开、保存、剪裁、缩放、旋转等操作。通过导入Image模块,我们可以使用PIL库中提供的各种图像处理函数和方法来处理图像数据
python自带的库

第三步 下载下载Tesseract-OCR引擎 否则无法OCR识别
如何下载安装,参照大佬的博客园(https://blog.csdn.net/weixin_51571728/article/details/120384909)
https://digi.bib.uni-mannheim.de/tesseract/ 下载 tesseract-ocr-w64-setup-v5.0.0.20190623这个版本
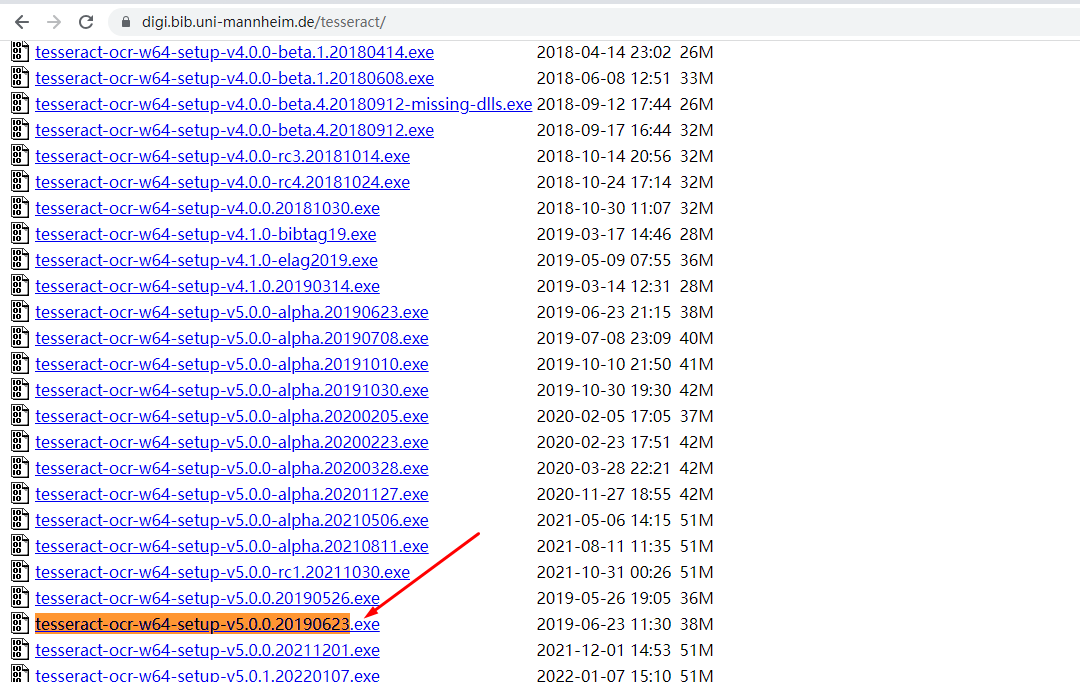
耗时比较久
下载后双击安装并添加环境变量
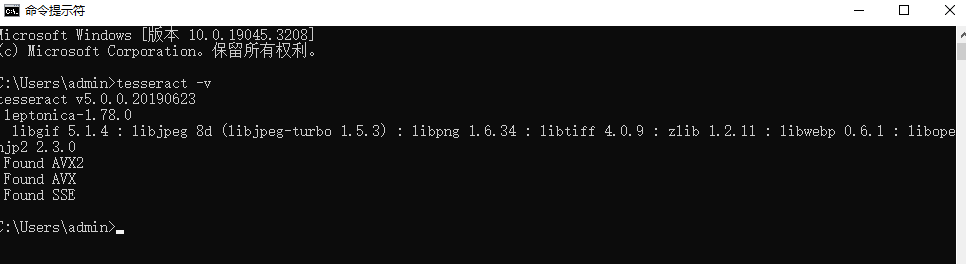
下载语言包
https://gitcode.net/mirrors/tesseract-ocr/tessdata/-/blob/master/chi_sim.traineddata
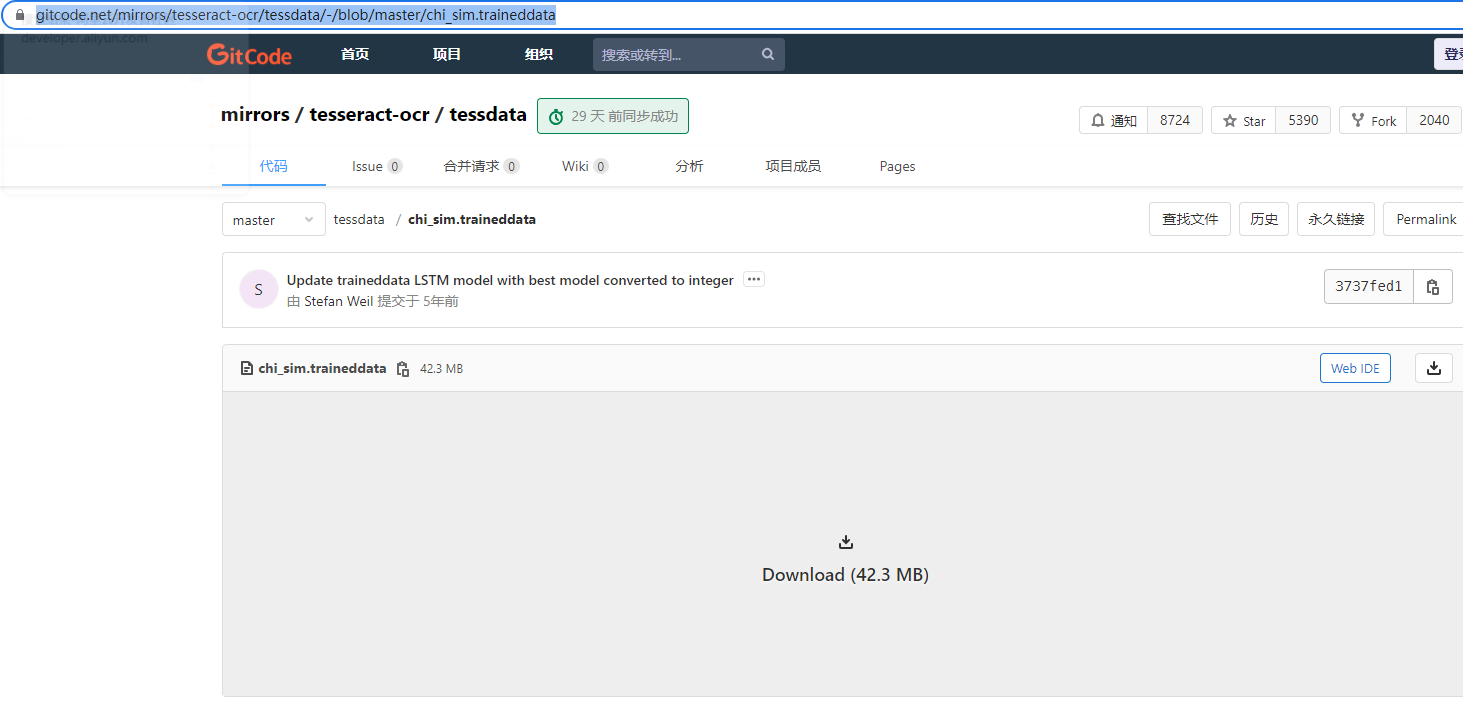
之前下载时选择了中文简体语言包,但因为墙,取消了,所以单独下载了包后直接替换就可以
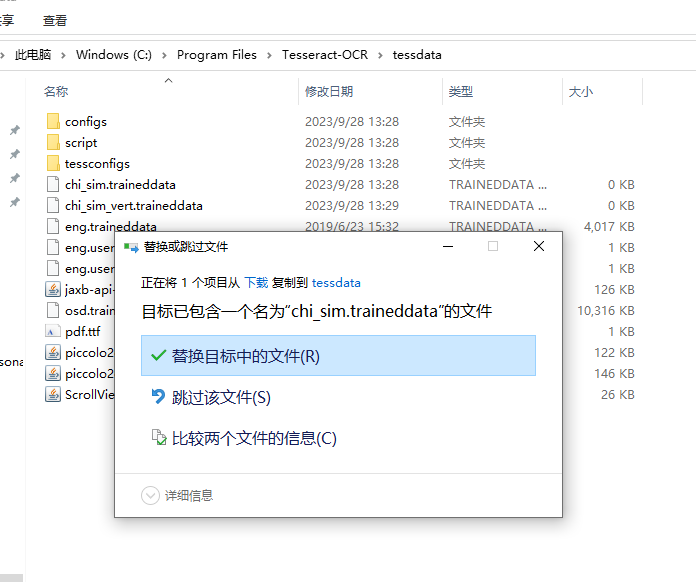
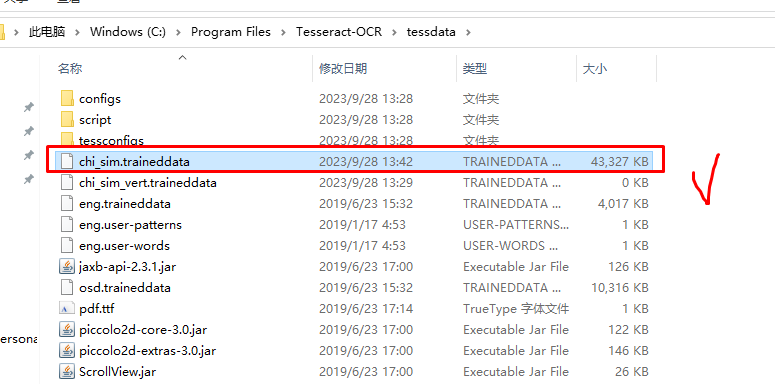
验证效果
代码
将照片中文字识别出来


import cv2 import pytesseract # 加载图片 image = cv2.imread('2.png') # 将图片转换为灰度图像 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 使用Tesseract进行文本识别 result = pytesseract.image_to_string(gray) # 打印识别结果 print(result)
结果
VP\Administrator
--------------------------------------
代码
实现对整个截屏截取验证码
# 从全屏截图中剪裁出验证码的照片 from PIL import Image def crop_image(image_path, top, bottom, left, right,output_path): # 打开图片 image = Image.open(image_path) # 裁剪图片 cropped_image = image.crop((left, top, right, bottom)) # 显示裁剪后的图片 cropped_image.show() # 保存裁剪后的图片 cropped_image.save(output_path) # 示例用法 image_path = "screenshot.png" # 替换为你的图片路径 ''' left=234 top=503 right=334 bottom=533 ''' top = 503 # 上边界的坐标 bottom = 533 # 下边界的坐标 left = 234 # 左边界的坐标 right = 334 # 右边界的坐标 output_path = "screenshot.png" # 要保存的路径和文件名 crop_image(image_path, top, bottom, left, right,output_path)
最终效果
图片仅裁剪为二维码
---------------------------------------------------------------------------------------------------------------------
代码 获取上下左右的坐标和整个页面的截屏照片
# 导包 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ES from time import sleep import pytesseract # 导入ocr库 from PIL import Image # 导入图像处理库 # 定义类 class FindEle: def __init__(self,driver): self.driver=driver def get_cap(self,loc): sleep(3) ele_cap=driver.find_element(By.CSS_SELECTOR,loc) # ele_cap.send_keys("hello") # 获取元素的位置和大小 location=ele_cap.location size=ele_cap.size print(f"location:{location},size:{size}") # 获取整个页面截图 driver.save_screenshot("screenshot.png") sleep(5) # 打开照片 captcha_image=Image.open("screenshot.png") # 获取验证码的上下左右坐标 left=int(location['x']) top=int(location['y']) right=int(location['x']+size['width']) bottom=int(location['y']+size['height']) print(f"left:{left},top:{top},right:{right},bottom:{bottom}") # 对图片做裁剪 captcha_image=captcha_image.crop((left,top,right,bottom)) # OCR识别 ele_value=pytesseract.image_to_string(captcha_image) print(ele_value) pass # 调用 if __name__ == '__main__': # 调用类 driver=webdriver.Chrome() # 打开浏览器 driver.get('http://XXX/member.php?mod=register') # 调用类 test_loc="img[src*='misc.php?mod=']" captcha=FindEle(driver) captcha.get_cap(test_loc) sleep(3) driver.quit()
----------------------------
遗留问题 验证码字体大小不一致不能识别 ,正常的可以识别,估计需要导入字体吧


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?