xpath 搭配id 强调 //a[contains(text(),'Selenium Official')]" 查找页面文字元素好用的很
第一种 属性
xpath根据属性id 查找元素

xpath 公式
//*[@id='fname']
//全局找
* 标签写*,代表全部的标签匹配 因为id 是唯一值所以可以使用*
[]表达式 里面@属性和属性对应的值
# 导包 import time from selenium import webdriver from selenium.webdriver.common.by import By from time import sleep # 引用谷歌驱动 driver=webdriver.Chrome() driver.get(r"D:\python-pro\baseapitest\xpath\html.html") # xpath 根据id查找元素 driver.find_element(By.XPATH,"//*[@id='fname']").clear() driver.find_element(By.XPATH,"//*[@id='fname']").send_keys("Fan") time.sleep(5) driver.quit()
最终效果
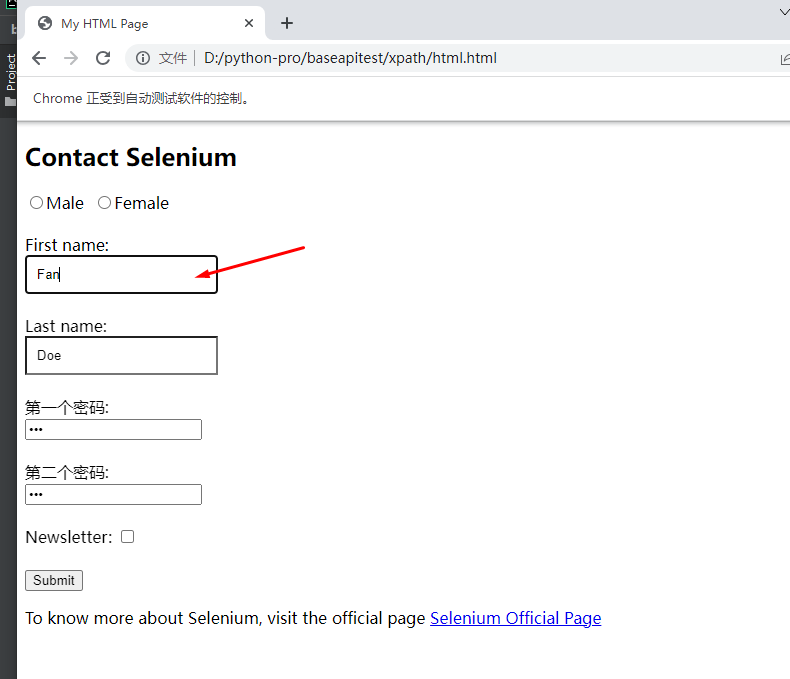
第二种 函数
(1)

# xpath 根据id查找元素 函数 以id开始[starts-with(@id,''psw)]
# xpath 根据id查找元素 函数 以。。。开始 driver.find_element(By.XPATH,"//*[starts-with(@id,'psw')]").clear() driver.find_element(By.XPATH,"//*[starts-with(@id,'psw')]").send_keys("Fan123")
(2)
# xpath 根据id查找元素 函数 contains包含 XX
# xpath 根据id查找元素 函数 contains包含 XX driver.find_element(By.XPATH,"//*[contains(@id,'ps')]").clear() driver.find_element(By.XPATH,"//*[contains(@id,'ps')]").send_keys("Fan123")
(3)

查找包含
Selenium Official文本的整个文本
# XPath表达式将匹配任何包含文本"Selenium Official"的<a>标签元素 # contains() 是XPath中的一个函数,包含 # text() 是XPath中的一个函数。它用于获取节点的文本内容 t=driver.find_element(By.XPATH,"//a[contains(text(),'Selenium Official')]").text print(t)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号