
通用网络信息采集器(爬虫)设计方案
一、引言
Heritrix3.X与1.X版本变化比较大,基于此带来的Extractor定向扩展方法也受到影响,自定义扩展方面因为接口的变化受阻,从而萌生了通用网络信息采集器设计的想法。一直没有一个好的网络信息采集器,必须能够适应下载对象的多样性和下载内容的复杂性。比如需要同时下载100多家主流媒体的新闻信息,并解析入库等。本文围绕通用网络信息采集器的设计展开。
二、需求分析
一个好的网络爬虫必须满足通用性、多任务、定向性和可扩展性。
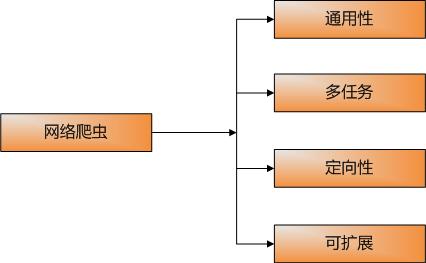
通用性是指可以满足不同格式下载对象的下载,如HTML、JS、PDF等等;多任务是指同时可以执行多个下载任务,即不同的网络站点;定向性是指可以根据自己的业务需求定向下载,即只下载自己关注的网页,其他无关页面自动过滤掉。比较好的是开源社区有很多可用的资源,比较不好的是能同时满足以上需求的软件非常少,好在Heritrix3.X就是能够满足的之一,不过需要自己编写代码,扩展Extrator,实现其定向下载。
三、架构设计
以下部分是期待中网络信息采集器的逻辑架构。如下图所示:
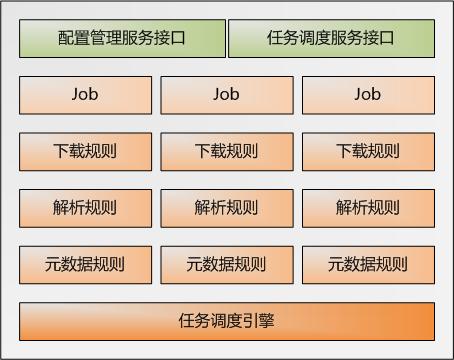
每一个目标任务代表一个下载渠道,比如sina、sohu等,下载规则负责URL过滤,只下载满足规则的内容,比如新闻;解析规则负责已经下载下来的内容的过滤,只选择我想要的东西,比如新闻标题、内容、评论等;元数据规则定义数据入库规则,任务与元数据规则关联实现自动入库。
四、成果展现
博客园躺着中枪了,以我个人的技术博客作为下载目标,以下部分展现的是我通过定向扩展后的下载结果:
P文件夹中的内容,代表具体的网页:
五、遗留问题
1.URL发现是否有必要独立,单独做成工具,根据入口网址+过滤规则,输出待下载对象的URL地址?当前采用的模式是复合式,逻辑上分离,物理上耦合。
2.如何实现增量下载和循环运行,当前任务启停是通过人工干预。需要改进。
作者:张子良
出处:http://www.cnblogs.com/hadoopdev
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号