最佳实践 缓存穿透,瞬间并发,缓存雪崩的解决方法
一.缓存穿透:
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
解决办法:
1.布隆过滤
对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃。还有最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
补充:
Bloom filter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。添加时增加计数器,删除时减少计数器。
2. 缓存空对象. 将 null 变成一个值.
也可以采用一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存空对象会有两个问题:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
二.缓存雪崩
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
解决方法
1. 加锁排队. 限流-- 限流算法. 1.计数 2.滑动窗口 3. 令牌桶Token Bucket 4.漏桶 leaky bucket [1]
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
2.数据预热
可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
3.做二级缓存,或者双缓存策略。
A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
4.缓存永远不过期
这里的“永远不过期”包含两层意思:
(1) 从缓存上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
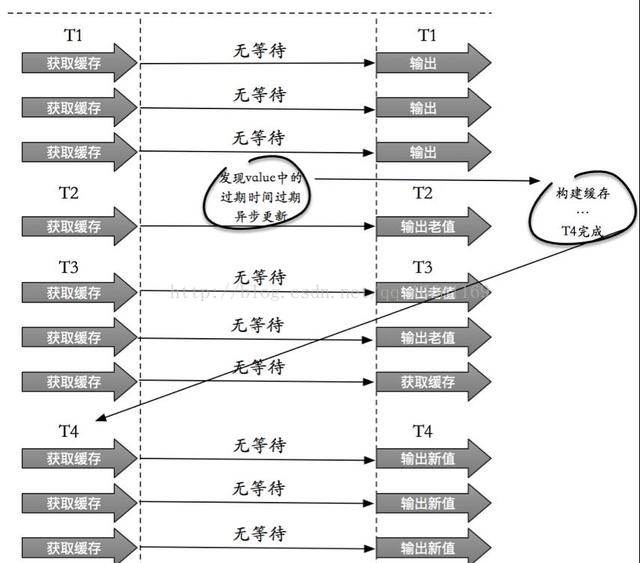
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期.
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
posted on 2018-08-25 20:50 hadley2012 阅读(2679) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号