SCRAPY入门学习(待完善)
Scrapy介绍
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
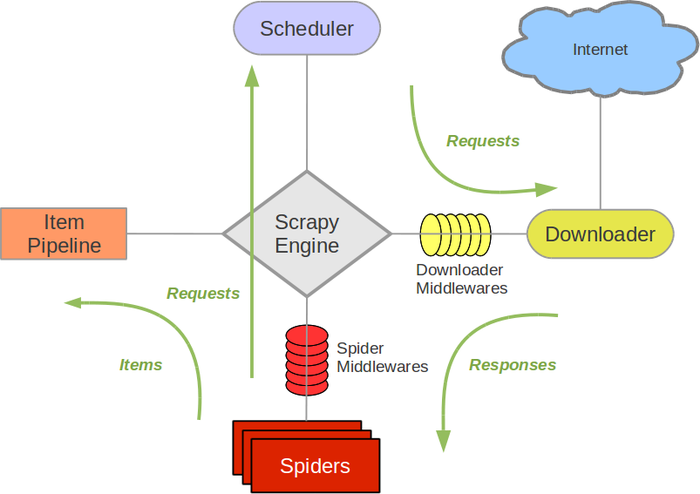
Scrapy的运作流程
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
触发时段:
初始化阶段:当Scrapy启动时,引擎会初始化调度器。
请求入队:每当有新的请求生成(例如在start_requests方法或在parse方法中生成新的请求),这些请求都会被发送到调度器。
请求出队:当下载器空闲并准备处理新的请求时,调度器会将下一个请求出队并发送给下载器。
去重处理:调度器会检查新请求是否已经存在于队列中,以避免重复处理。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
安装教程略
练习
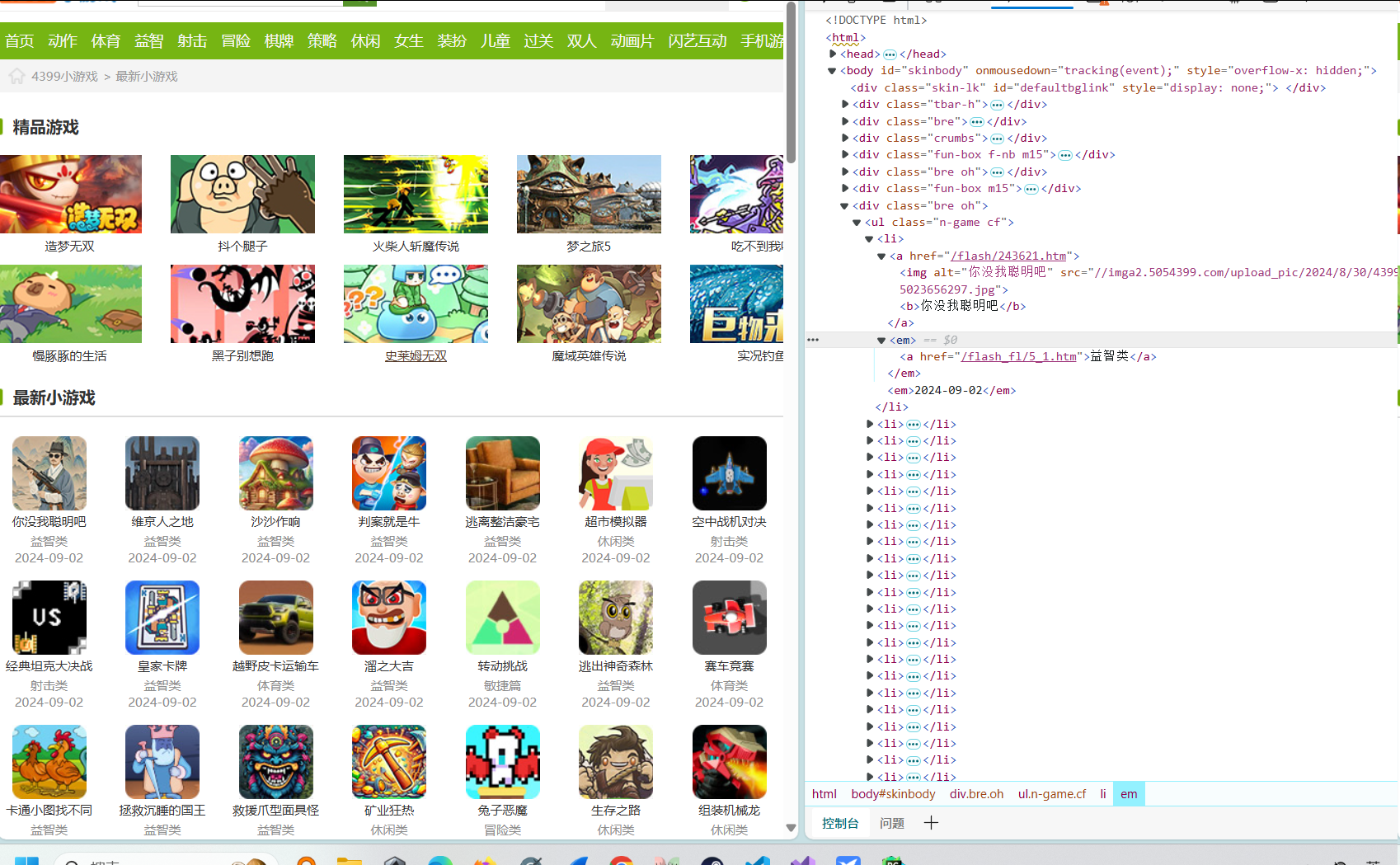
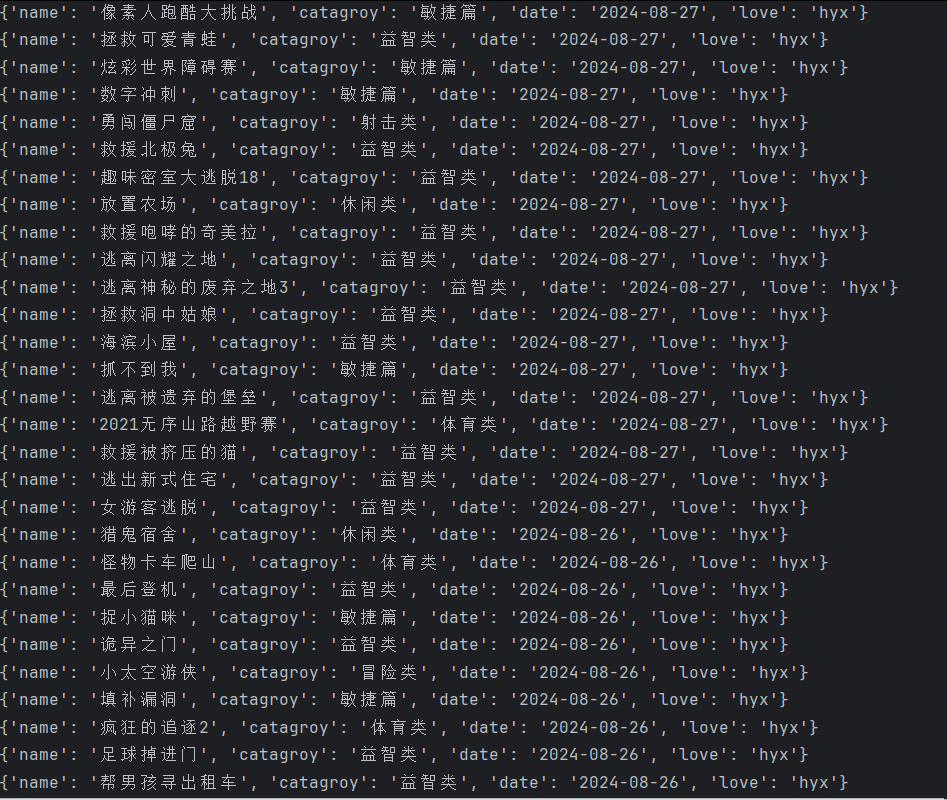
以爬取https://www.4399.com/flash/的游戏名、日期、分类为例:
查看html结构(只爬取最新小游戏信息)
创建好爬虫项目:scrapy startproject pj1
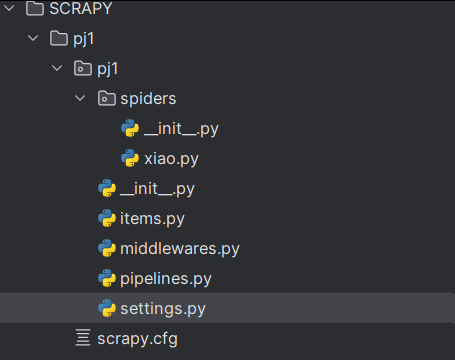
xiao.py
import scrapy
class XiaoSpider(scrapy.Spider):
name = "xiao"
allowed_domains = ["4399.com"]
start_urls = ["https://www.4399.com/flash/"]#可以添加多个url
def parse(self, response):
# txt=response.xpath('/html/body/div[8]/ul/li/a/b/text()').extract()
l=response.xpath('/html/body/div[8]/ul/li')
lst=[]
for i in l:
name=i.xpath('./a/b/text()').extract_first()
catagroy=i.xpath('./em/a/text()').extract_first()
date=i.xpath('./em/text()').extract_first()
dic={"name":name,"catagroy":catagroy,"date":date}
yield dic # 传给管道的item变量
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class Pj1Pipeline:
def process_item(self, item, spider):
print(item)#管道处理方式可以自定义,如写入文件,存入数据库等
return item
class rPipeline: #除了初始管道,还可以自定义新管道
def process_item(self, item, spider):
item['love']='hyx'
return item
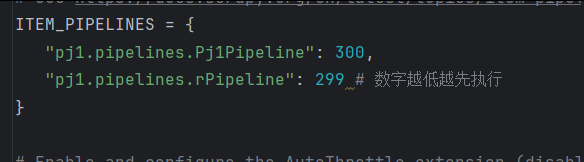
设置管道优先级(先传入哪个管道处理数据,处理完再传入哪个管道)
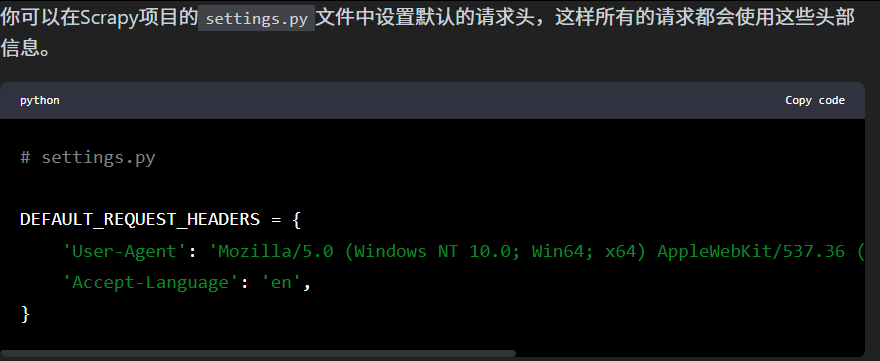
请求头添加方法
1.setting.py里面添加
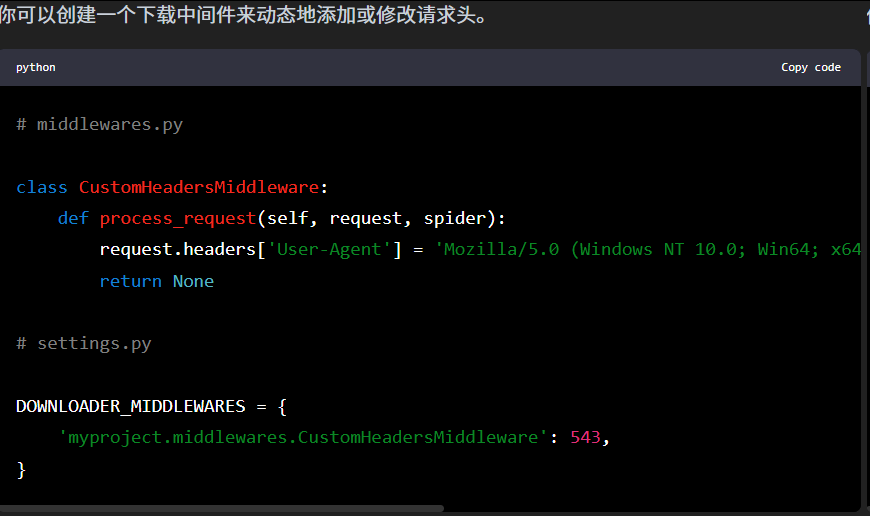
2.中间件添加
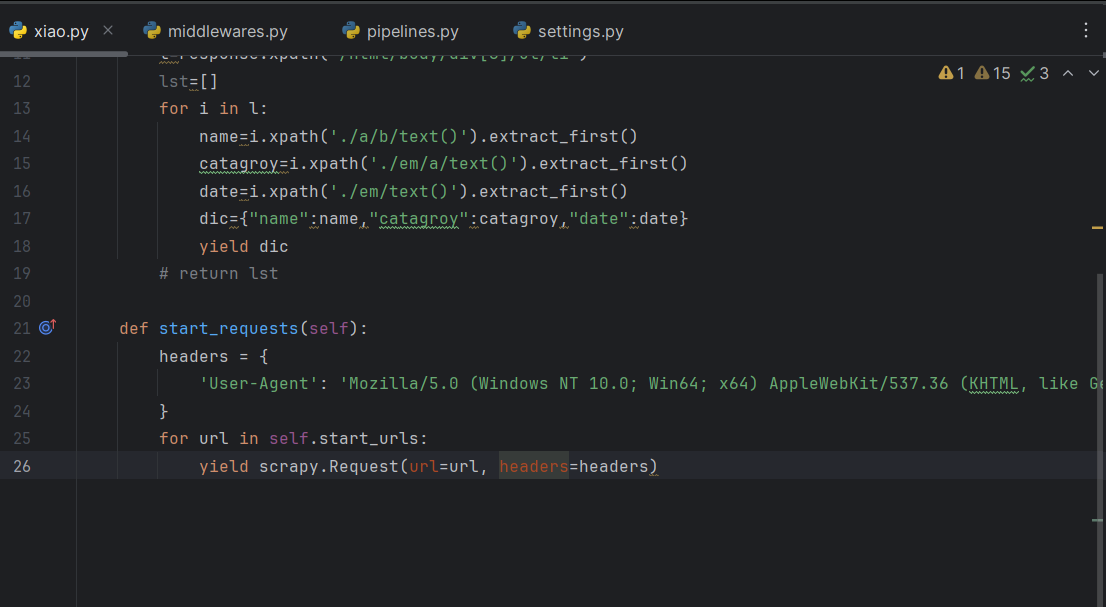
3.spider里面添加
在你创建的spider里面写个start_requests方法
本文来自博客园,作者:积分别忘C,转载请注明原文链接:https://www.cnblogs.com/hackzz/p/18393643

 浙公网安备 33010602011771号
浙公网安备 33010602011771号