selenium爬虫学习1
简介
Selenium是广泛使用的模拟浏览器运行的库,它是一个用于Web应用程序测试的工具。 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,并且支持大多数现代 Web 浏览器。
函数介绍
重点方法
1.find_element方法是 Selenium WebDriver 提供的一种用于查找页面上某个符合条件的元素的方法。
2.find_elements 方法是 Selenium WebDriver 提供的一种用于查找页面上所有符合条件的元素的方法。与 find_element 不同,find_elements 返回的是一个列表,其中包含所有匹配的元素。如果没有找到任何元素,则返回一个空列表。
以下是 find_element(s) 方法的一些常见用法:
By.ID:通过元素的 ID 查找。
By.NAME:通过元素的 name 属性查找。
By.CLASS_NAME:通过元素的类名查找。
By.TAG_NAME:通过元素的标签名查找。
By.LINK_TEXT:通过链接文本查找。
By.PARTIAL_LINK_TEXT:通过部分链接文本查找。
By.CSS_SELECTOR:通过 CSS 选择器查找。
By.XPATH:通过 XPath 表达式查找。
driver.find_element对象具有.click()方法,就是点击这个元素
3.driver.window_handles获取当前所有窗口句柄
4.driver.switch_to.window()跳转到某个窗口
练习代码
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 初始化浏览器驱动
driver = webdriver.Chrome()
# 打开阿里云漏洞库首页
driver.get("https://avd.aliyun.com/")
time.sleep(2)
# 定位输入框并输入关键字
search_box = driver.find_element(By.XPATH, "/html/body/header/nav/div/form/input")
search_box.send_keys("MySQL")
# 点击搜索按钮
search_button = driver.find_element(By.XPATH, '/html/body/header/nav/div/form/button')
search_button.click()
# 等待2秒
time.sleep(2)
res_header=driver.find_element(By.ID,'itl-header')
print(res_header.text)
tr_elements = driver.find_elements(By.XPATH,"/html/body/main/div[2]/div/div[2]/table/tbody")
for tr in tr_elements:
# 在这里对每个tr元素进行操作,例如提取文本内容
print(tr.text)
link = driver.find_element(By.PARTIAL_LINK_TEXT, "AVD-2024-21177")
link.click()
all_windows = driver.window_handles
driver.switch_to.window(all_windows[-1])
searchclass=driver.find_elements(By.CSS_SELECTOR, '.border-bottom.border-gray.pb-2.mb-0')
for search in searchclass:
print(search.text)
time.sleep(3)
driver.close()
driver.switch_to.window(all_windows[0])# 切回原来的窗口
input("Press Enter to close the browser...")
# 关闭浏览器
driver.quit()
运行效果
运行过程
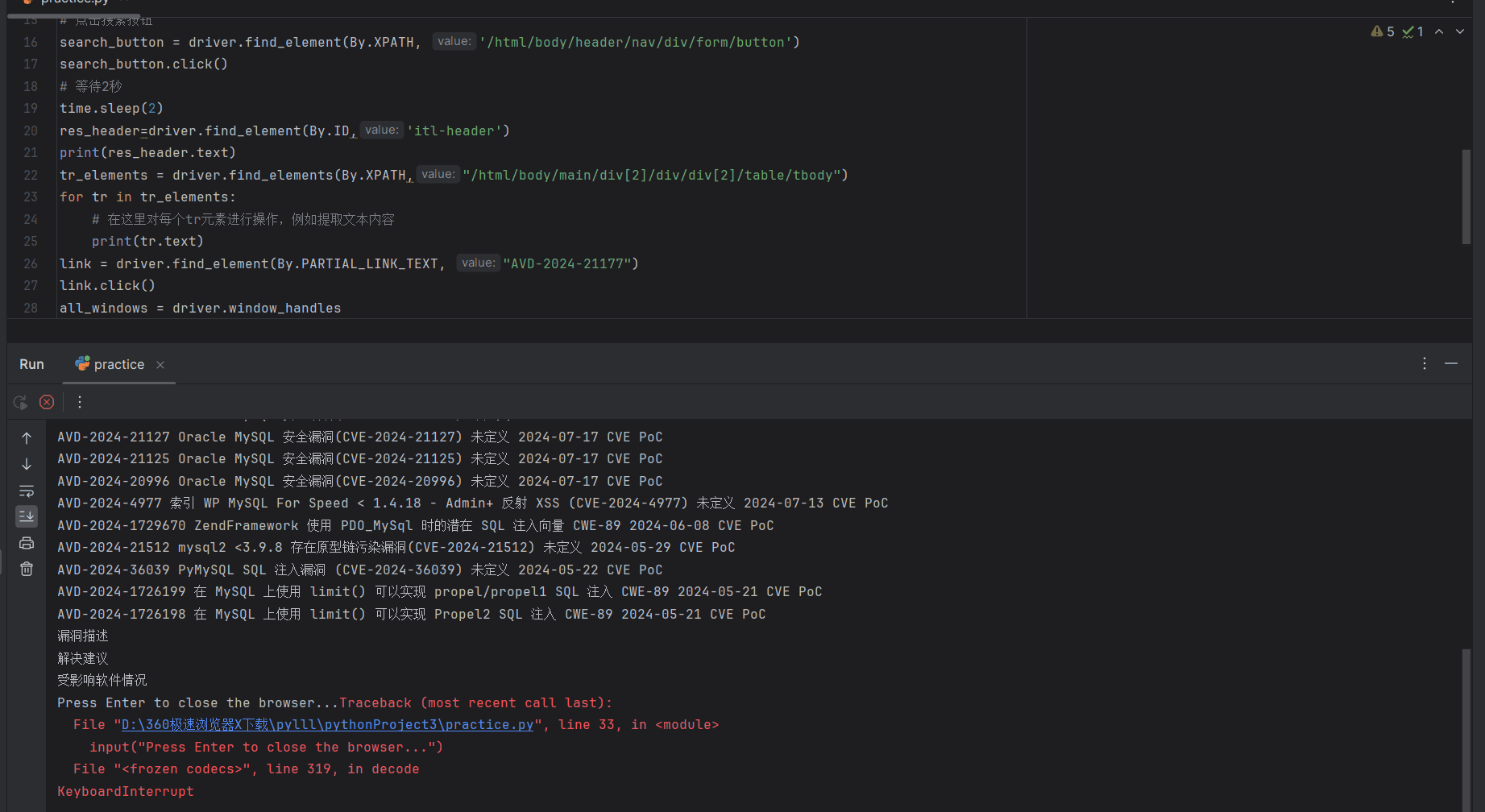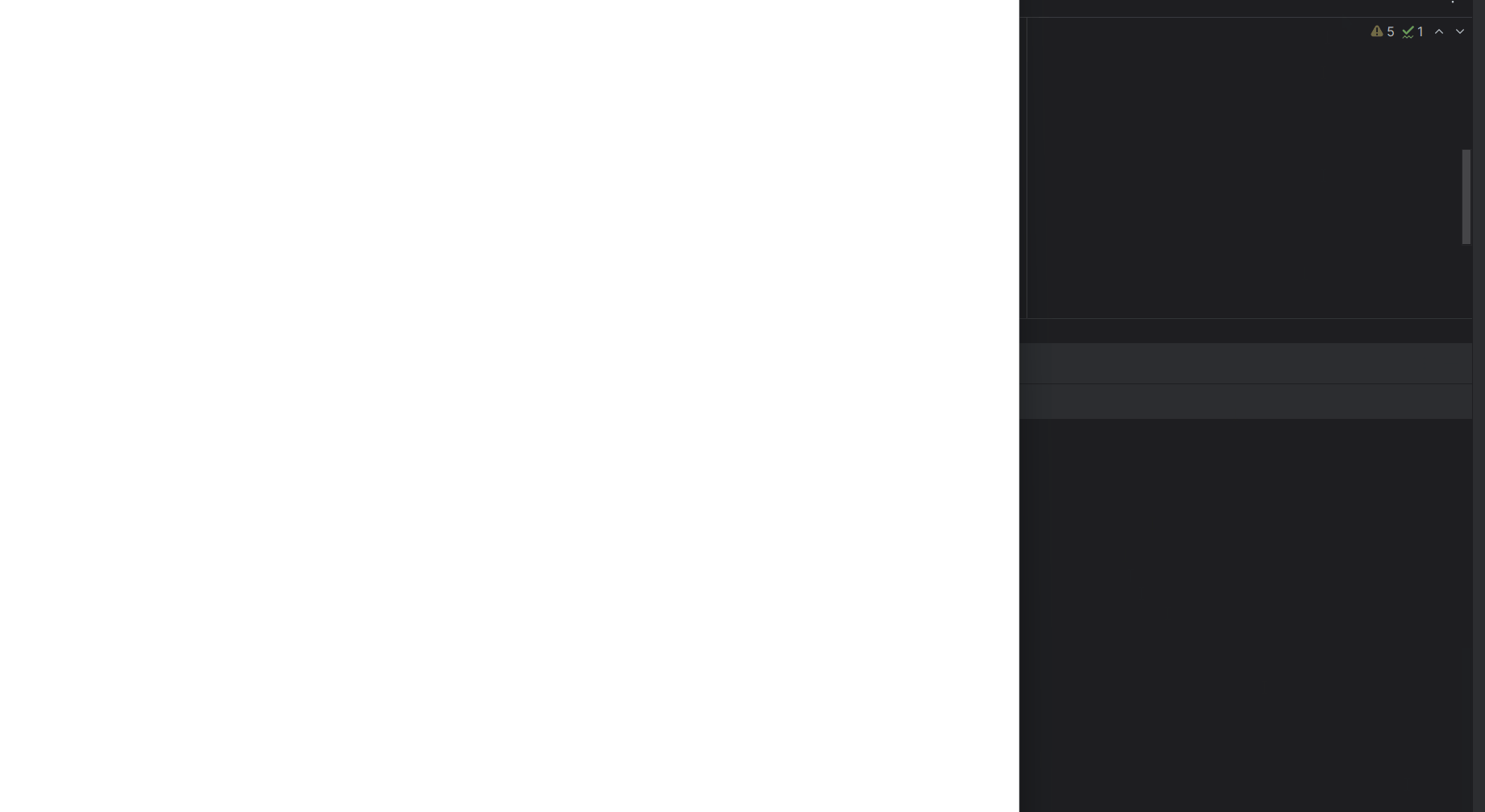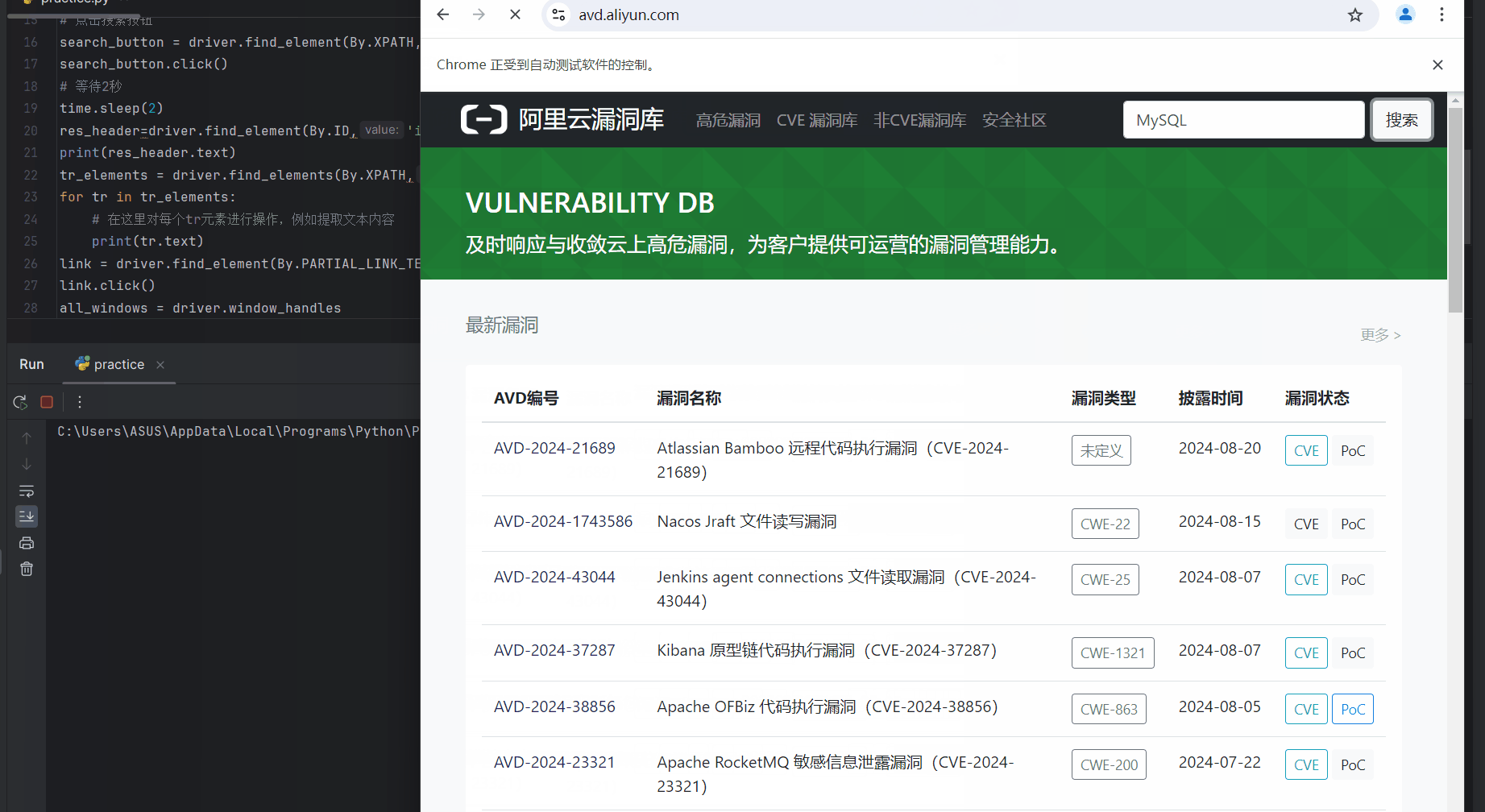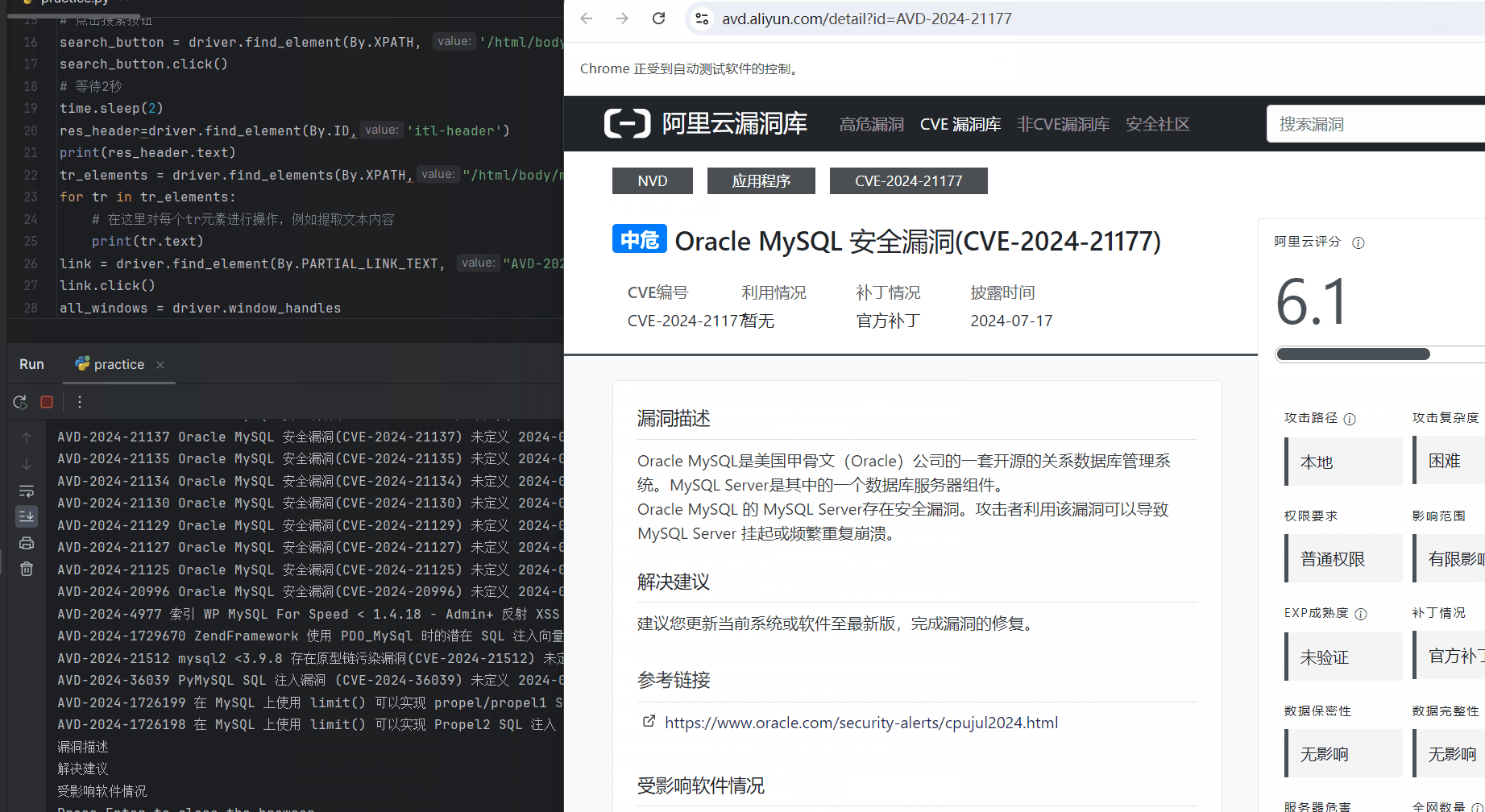
运行后先是打开浏览器进入阿里云漏洞库,紧接着搜索MYSQL相关漏洞,结果如下
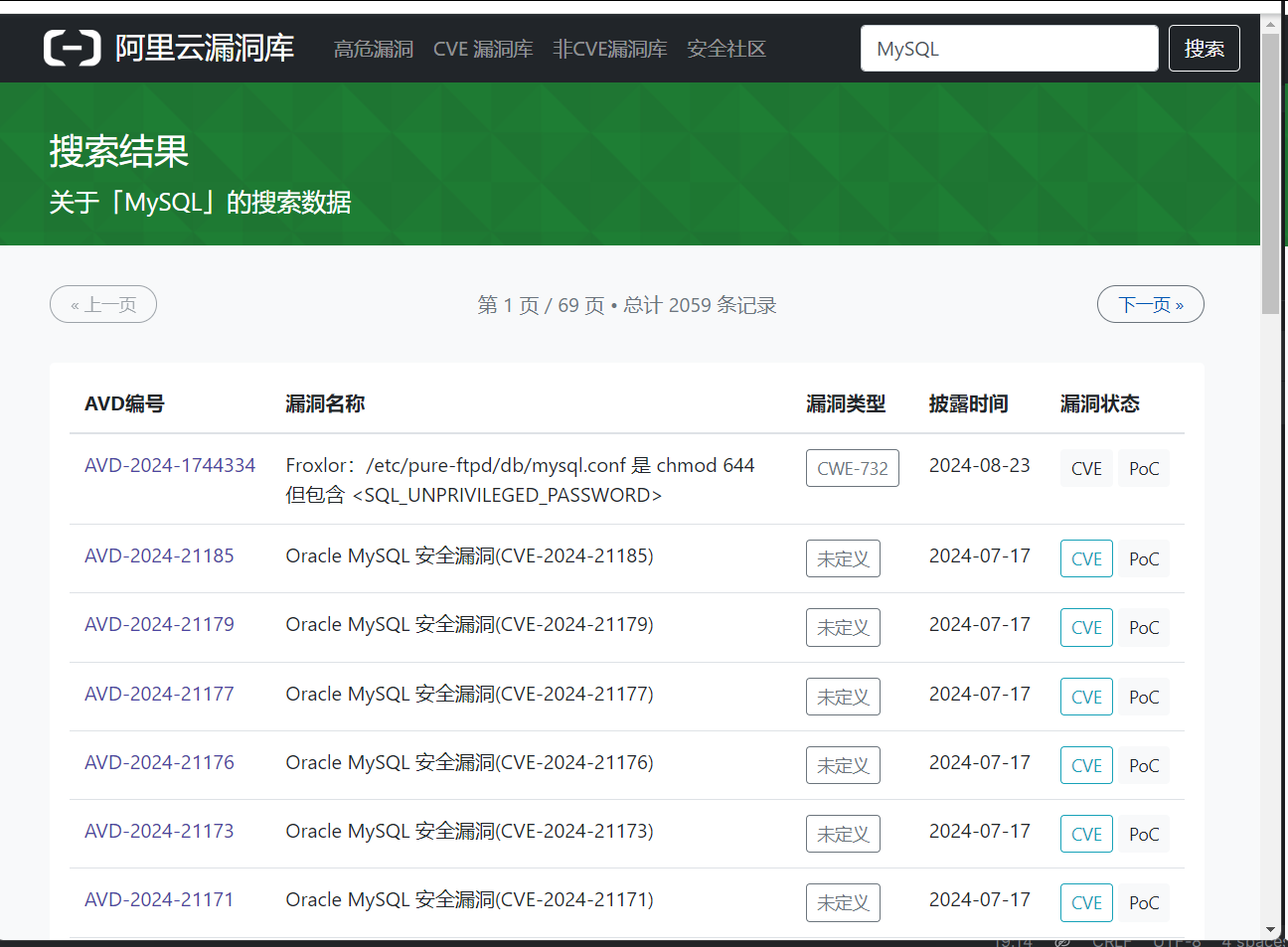
通过html的id属性找到“搜索结果 关于[mysql]的搜索数据”这几个字打印出来
tr_elements = driver.find_elements(By.XPATH,"/html/body/main/div[2]/div/div[2]/table/tbody")
res_header=driver.find_element(By.ID,'itl-header')
print(res_header.text)
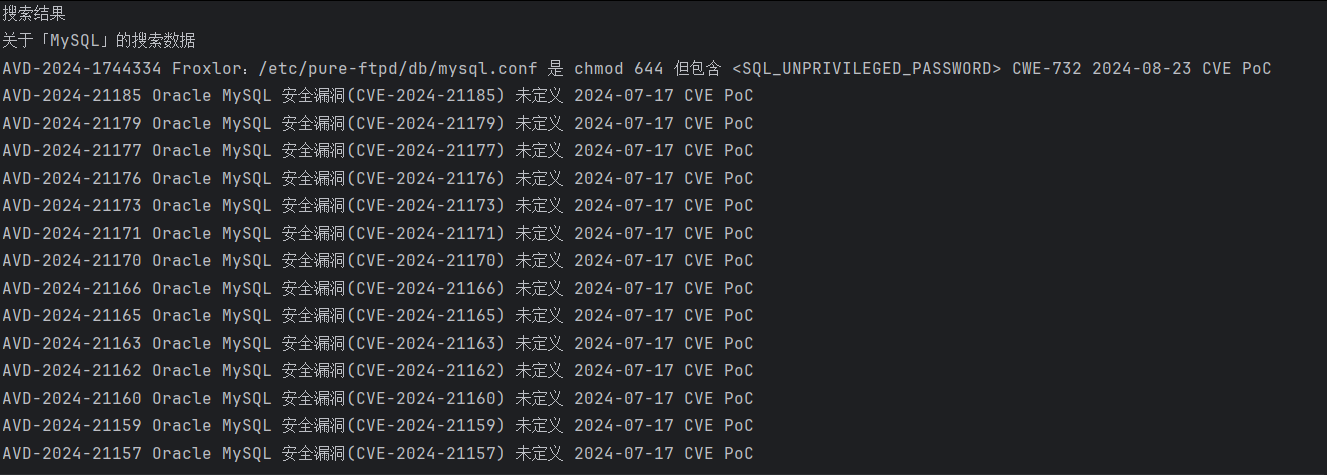
通过xpath找到tbody里面所有行,遍历并打印内容
tr_elements = driver.find_elements(By.XPATH,"/html/body/main/div[2]/div/div[2]/table/tbody")
for tr in tr_elements:
# 在这里对每个tr元素进行操作,例如提取文本内容
print(tr.text)
随便定位一个漏洞介绍的链接点进去:
link = driver.find_element(By.PARTIAL_LINK_TEXT, "AVD-2024-21177")
link.click()
all_windows = driver.window_handles # 获取所有窗口的句柄
driver.switch_to.window(all_windows[-1])#有的浏览器并不会自动跳转到点开的标签页,所以可以获取当前所有标签页再利用函数跳转
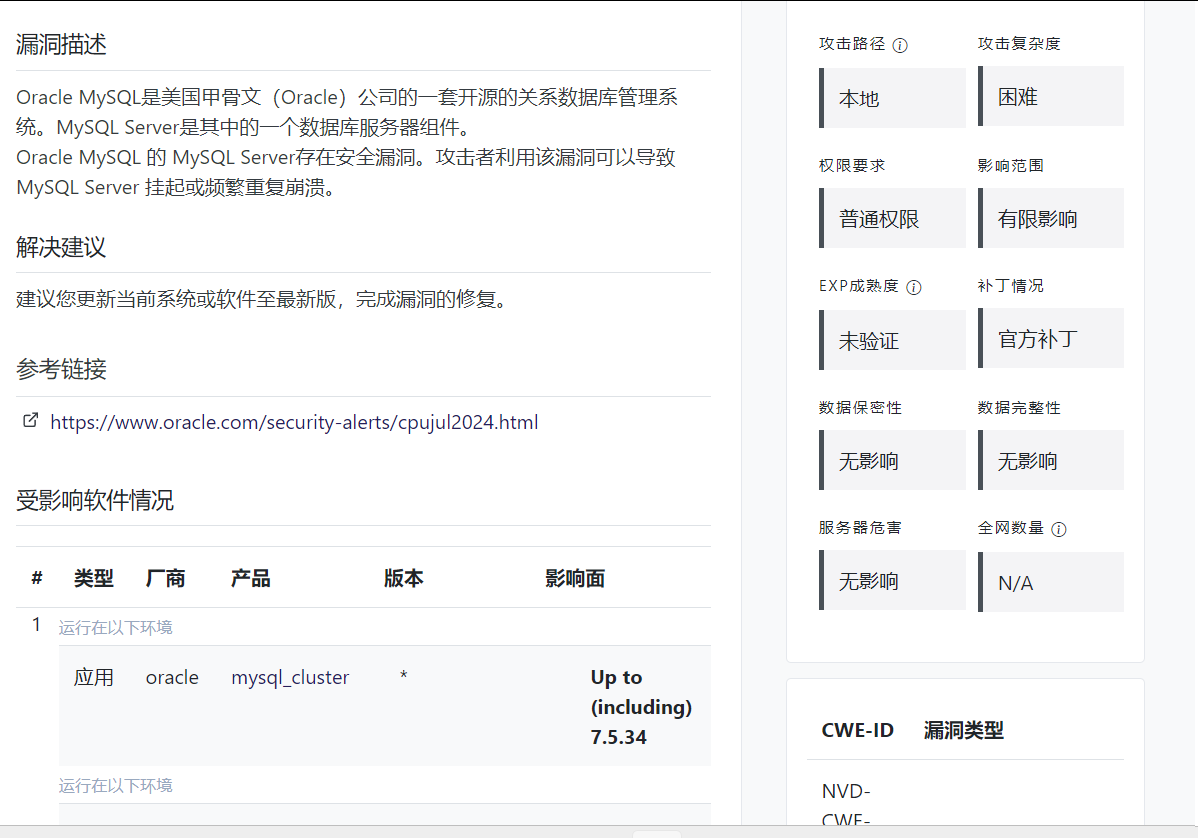
打印所有class="border-bottom border-gray pb-2 mb-0"的元素

searchclass=driver.find_elements(By.CSS_SELECTOR, '.border-bottom.border-gray.pb-2.mb-0')
for search in searchclass:
print(search.text)
因为class的值包含空格所以不能直接By.CLASS寻找,用By.CSS_SELECTOR,每个值用点号分隔
关闭浏览器
本文来自博客园,作者:积分别忘C,转载请注明原文链接:https://www.cnblogs.com/hackzz/p/18386310

 浙公网安备 33010602011771号
浙公网安备 33010602011771号