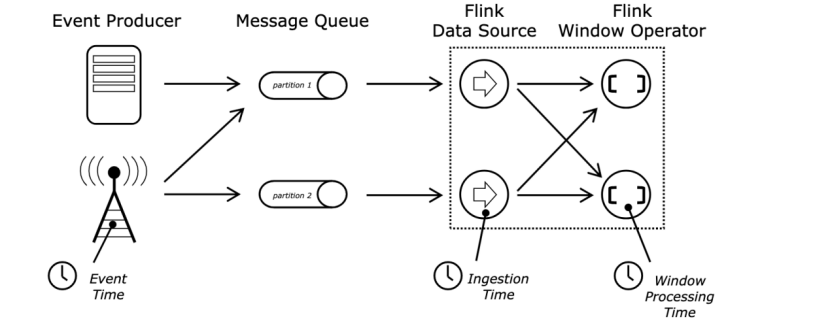
Event Time
上游:https://www.cnblogs.com/hackerxiaoyon/p/12747387.html
事件时间、处理时间、摄入时间
处理时间:处理时间引用来自执行相应操作机器系统时间。
当一个流程序运行在处理时间,那么所有的操作都是基于机器的系统时间。一个小时窗口处理时间包括所有的数据就是说在这个系统时钟一个小时内操作算子的所有数据。举例子:如果一个程序在上午9:15开始启动,那么第一个小时窗口就是从此刻到上午的10:00.下一个窗口就是10点到11点。
处理时间是最简单的概念不需要流和机器之间进行协调。它提供了最好的性能和最低的延迟。无论怎样,在分布式和异步环境处理时间不能保证时间的准确性,因为这个容易收到到达系统速度,系统内部的算子数据之间传输速度和中断(计划,或者其他)的影响。
事件时间:事件时间就是在我们触发事件时候的业务时间。就是每条数据在没有进入flink之前就存在的。在事件时间,时间的处理过程依赖于数据。事件时间必须要指定如何生产事件时间的水印,水印就是在事件时间中标示处理过程的机制。水印机制被描述为在一个延迟的场景,如下。
在一个完美世界,事件时间处理是会确保完成一致性和确定的结果,考虑到当事件到达或者他们的顺序。除非事件知道达到在顺序内,事件时间处理会导致一些延迟当在等待一些无序事件时候。由于只能等待有限的时间,这就是限制了事件时间应用程序的确定性。
假设所有的数据已经到达,事件时间操作算子将会按照期望运行,然后生产正确一致性的结果即使当事件是无序的或者延迟的,或者在加工历史数据。举例:一个小时的窗口包含的所有数据携带一个事件时间戳落地在这一个小时内,不会考虑他们到达时间,或者他们处理时间。延迟场景可以产看更多内容(https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/event_time.html#late-elements)
注意:有时候在处理实时数据时候,会用处理时间为了保证程序的及时性。
摄入时间:这个时间就是事件进入flink的时间。就是在source算子每一条记录会获取数据源当前时间作为一个时间戳,时间基于算子引用。
摄入时间从概念上介于事件时间和处理时间之间。对比处理时间,显得贵重了一些,但是提供了预测的结果。因为输入时间使用稳定的时间戳,不同的窗口算子会引用相同的时间戳,然后处理时间每个窗口算子可能分配记录到不同的窗口。
对比事件窗口,摄入时间程序不能控制无序或者延迟数据,但是程序就不需要去指定产生水印。
摄入时间更加的被处理看待为事件时间,但是时间戳是自动分配的,水印也是自动生成的。
设置一个时间特征
Flink 数据流程序第一部分通常设置基础时间特征。这个设置定义数据流源行为。举例:是否分配时间戳。时间的概念是通过窗口算子来实现,如:KeyedStream.timeWindow(Time.seconds(30)).
下面的例子展示了flink程序一个小时的聚合操作。窗口的行为通过设置时间来体现。
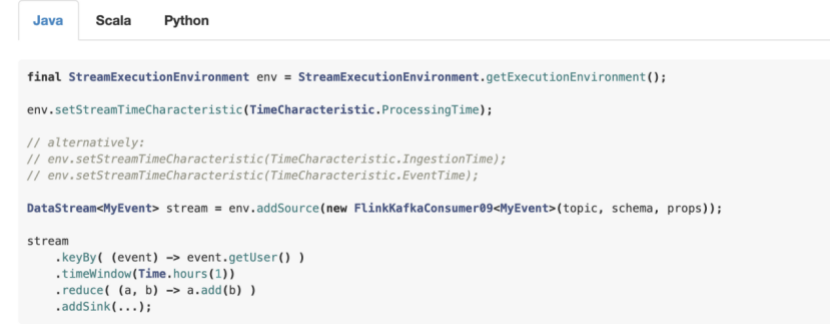
为了跑这个例子用事件时间,程序需要使用数据源直接定义事件事件和发送水印,或者是注入一个时间戳分配器和水印生产器在数据源之后。这些方法描述了如何去接入事件时间戳,这个事件流的无序程度。
下面的场景描述了时间戳和水印背后的生成机制。作为一个向导怎么去使用时间戳分配和水印生成在flink 数据流api中,请引用 https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/event_timestamps_watermarks.html
事件时间和水印
如下两片文章很好的介绍数据流模式中的事件时间和水印。
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
https://research.google.com/pubs/archive/43864.pdf
一个流处理过程需要支持测量的事件时间的能力,例如:在一个小时级别的窗口,如果数据时间超过了一个小时最后时间需要提醒然后关闭窗口。
事件时间独立于处理时间运行。举例:一个程序当前操作可以在处理时间之后稍微延迟。一方面,其他的流程序可能处理通过周期的事件时间在极短的时间内,在kafka主题中的缓存中。也就是说topic中会有buffer存储的数据,我们可以快速的从buffer中取出数据进行处理。
flink中事件时间的处理机制叫做水印。水印作为数据流的一部分并携带了一个时间戳t。水印声明事件时间到达时间t,意味着数据元素都是小于t这个时间的元素。
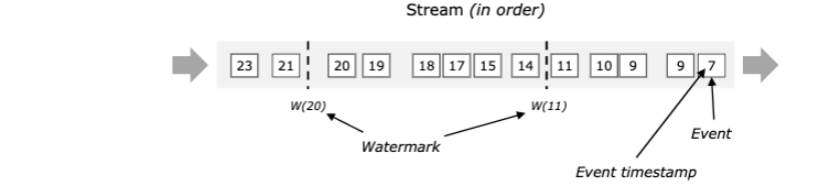
下图展示了事件携带时间戳和水印。这个demo是按照顺序,水印会周期性的产生。
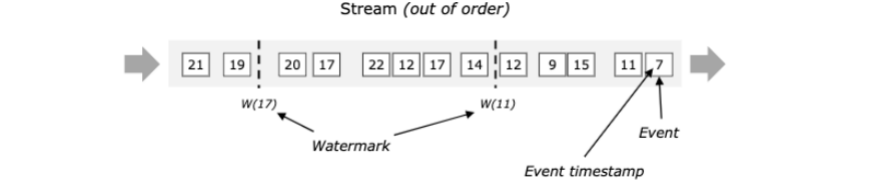
水印对于无序流是比较重要的,下列说明,事件没有按照时间戳顺序。通常一个水印是一个声明在一个流中,所有的事件都应该到达某个时间点。一旦一个水印达到一个算子,这个算子可以将内部事件时间时钟提前到水印值。
注意:事件时间被继承了通过一个新创建的流元素来自事件,这个事件生产他们或者来自水印触发生产这些元素。
并行流中的水印
水印产生在source 函数处或者之后。每个源函数并行子任务通常独立生产他自己的水印。这些水印定义了事件时间在特定的并行源中。
水印在流程序经过,他们会提前达到算子的事件时间。当一个算子完成了他的这一批事件时间后就会生成一个新的水印给下游标示他本次的完成操作。
一些算子消费多个输入流,一个合并举例:或者是算子通过keyby()或者partition()。这样的算子的当前事件时间是最小输入流的事件时间。作为他的输入流更新他们的事件时间。
如下展示了事件和水印通过并行流的demo,算子追踪事件时间。

注意:kafka源支持每个分区水印,可以通过阅读查看https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/event_timestamps_watermarks.html#timestamps-per-kafka-partition
延迟元素
这是很有可能的某个元素将会违反水印条件,意思就是事件在水印之后被捕获到了,更多的元素小于 水印时间。实际上,在很多真实的世界里步骤,某个元素可以允许延迟。更多的,即使延迟有限度,但是延期的太多也不是我们所期望的。
基于这个原因,流程序可能会期望一些延迟的数据。所以可以设置一些最后元素的到达时间。具体看https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/windows.html#allowed-lateness
闲置源
目前,纯事件时间水印生成器,水印不会处理如果没有数据产生。意思就是在来的数据间隙,事件时间不会处理举例:窗口算子不能触发并且这样存在的窗口将不会有能力生成任何输出数据。
规避这个问题可以用定期的水印触发器不是仅仅基于元素时间戳分配。一个解决方案例子,可以是一个触发器,这个触发器可以交换使用当前的处理时间作为时间在没有新事件进来的时候。
可以把源闲置通过SourceFunction.SourceContext#markAsTemporarilyIdle.更加具体的引用可以参考对应的Javadoc和StreamStatus。
调试水印
https://ci.apache.org/projects/flink/flink-docs-release-1.10/monitoring/debugging_event_time.html
算子如何处理水印
作为一个生产规则算子需要完整的处理一个给定的水印在发往下游。举例:WindowOperator 将首先评估哪个窗口应该被释放解雇,就是所有数据再下个水印生成才会发送到下游。
相同规则应用于TwoInputStreamOperator。
更详细通过OneInputStreamOperator#processWatermark, TwoInputStreamOperator#processWatermark1 和TwoInputStreamOperator#processWatermark2 方法来实现
翻译来源:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/event_time.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号