Docker Playgrounds
上级:https://www.cnblogs.com/hackerxiaoyon/p/12747387.html
Flink Operations Playground
flink的操作场地,从这一小节,会学习到flink如何的去部署和监控应用,作业失败以后去恢复,执行日常作业任务像升级和重新调整。
Anatomy of this Playground
看一下这个环境场所的构造,由一个长期活跃的flink会话集群和一个kafka集群组成。一个flink集群是由一个flink master节点和一个或多个flink taskmanagers 组成。Flink master的主要任务就是管理任务job的提交,监督任务还有资源的管理。Taskmanager 就是实际的工作者处理我们提交的具体作业任务。在这次你会启动一个单个taskmanager,不过稍后会扩展到多个。此外,这个环境是由我们的一个客户端容器来创建的,之后我们的一些提交任务和执行各种操作都会在此客户端容器。客户端并不是由flink 集群所必须提供的,只是了容易上手使用。
kafka集群是包含了zk集群和kafka的各个节点broker。

当我们提交一个作业到master的时候,才外还有kafka的主题和消费者也同样会被创建。
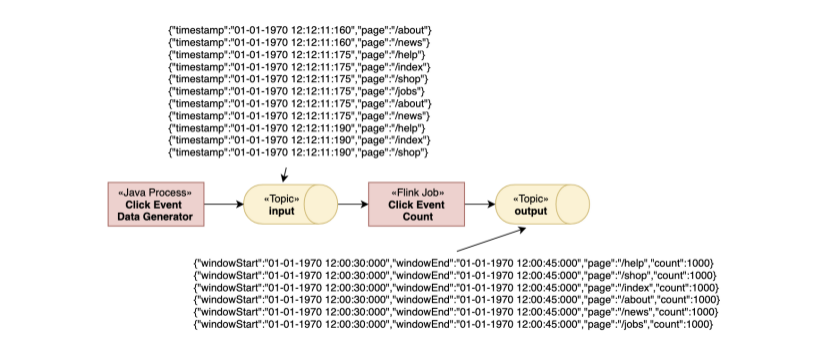
作业消费中的点击事件 来自与主题的输入,每一条信息中都有一个timestamp 时间戳 和 page 页面信息字段。之后是痛殴page去做为key分组,并且统计在15秒的窗口。之后结果会被写到输出的主题中。
Starting the Playground
我们要开始启动我们的环境了,只需要及步骤就可以搞定。这里会介绍几个必要的命令,通过这些命令个能够让我们的作业运行的很正常。
假设我们已经安装了docker (1.12+)的版本和docker-compose(2.1+) 版本,说实话我的电脑没有装,之前的电脑自玩的时候用过docker,工作中我现在没有自己用,部署后台api的时候,也是jenkins自动部署, docker都是运维已经给集成好的,不过这些不影响我们学习,好的我们继续。
接下来我们安装一下docker
https://download.docker.com/mac/stable/Docker.dmg 确实挺费力气的,下载了好久。
环境安装好了以后我们进行官网的环境搭建
下载代码从git然后docker编译运行。docker我不是很熟悉,暂且我们按照官网走。
git clone --branch release-1.10 https://github.com/apache/flink-playgrounds.gitcd flink-playgrounds/operations-playground
docker-compose build
docker-compose up -d
之后我们就可以通过命令查看到运行docker 环境了。
docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------------------------
operations-playground_clickevent-generator_1 /docker-entrypoint.sh java ... Up 6123/tcp, 8081/tcp
operations-playground_client_1 /docker-entrypoint.sh flin ... Exit 0
operations-playground_jobmanager_1 /docker-entrypoint.sh jobm ... Up 6123/tcp, 0.0.0.0:8081->8081/tcp
operations-playground_kafka_1 start-kafka.sh Up 0.0.0.0:9094->9094/tcp
operations-playground_taskmanager_1 /docker-entrypoint.sh task ... Up 6123/tcp, 8081/tcp
operations-playground_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
出现这种情况就是表明客户端容器已经成功提交到flin的作业和所有的集群组建,同时数据也生成在运行中。我们可以通过停止环境命令结束环境。
Docker-compose down -v
Entering the Playground
Flink WebUI
Flink 的ui界面默认是 http://localhost:8081.运行正常的话你会看到一个taskManager 和一个叫做Click Event Count的执行作业。

webui包含了很多有用的有趣的信息想作业图,指标,检查点,taskmanager的状态等等 ,我们能够从这儿看到task中的日志记录利于我们排查问题,如果日志大了可能就页面打不开了。但是我们可以通过yarn 把作业日志打印到文件中,通过tail 查看后面的信息来排查问题。
Logs
查看日志
jobManager
docker-compose logs -f jobmanager
TaskManager
docker-compose logs -f taskmanager
Flink CLI
https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/cli.html
客户端的命令很有用,我们可以用来查看作业信息等操作。比如我们可以打印一下有用的信息:
docker-compose run --no-deps client flink --help
Flink REST API
https://ci.apache.org/projects/flink/flink-docs-release-1.10/monitoring/rest_api.html#api
flink的一些接口信息,通过接口我们可以做我们自己的监控任务。比如查看所有作业信息
curl localhost:8081/jobs
Kafka Topics
查看kafka写入数据
//input topic (1000 records/s)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic input
//output topic (24 records/min)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
Time to Play
我们已经学习了如何与flink,docker容器交互,接下来我们再看一下一些通常的操作任务。所有的作业任务都是独立,我们可以不按照顺序执行执行他们,想执行哪个就执行哪个。大多数的任务可以通过客户端和rest api执行。
Listing Running Jobs
cli
Command
docker-compose run --no-deps client flink list
Expected Output
Waiting for response...
------------------ Running/Restarting Jobs -------------------
16.07.2019 16:37:55 : <job-id> : Click Event Count (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
REST API
Request
curl localhost:8081/jobs
Expected Response (pretty-printed)
{
"jobs": [
{
"id": "<job-id>",
"status": "RUNNING"
}
]}
Observing Failure & Recovery
观察任务失败与恢复,flink在失败的情况下保证了精准一次。我们通过这个环境来验证这个行为。
Step 1: Observing the Output
基于上面的描述,这个事件再每一个窗口包含了精确的1000条数据。因此,为了验证taskmanager失败以后数据丢失或者重复成功的恢复你可以跟踪输出的主题和检查在恢复之后所有的窗口是现在的和数量是正确的。
读取输出的主题信息直到恢复之后离开(step 3)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
Step 2: Introducing a Fault
为了模拟部分失败可以kill掉一个TaskManager。同时TaskManager进程也会丢失,TaskManager 机制或者简单的异常通过代码或者框架会跑出来。
docker-compose kill taskmanager
经过几秒后,master会发现有taskmanager挂了取消受影响的作业并且立即重新提交恢复作业。当作业重新启动后,任务在规划的状态中,这一部分是在紫色的区域中记录。
Note:尽管作业中的任务在规划状态中还没有运行,但是作业的整体状态已经是RUNNING
此时,作业中的任务不能从SCHEDDULED状态移动到RUNNING状态,因为这里没有资源由TaskManagers提供的TaskSlots,给这些任务。直到一个有一个新的TaskManager成为可用的,这个作业将会经历从取消到重新提交的生命周期。与此同时,数据生成器会将ClickEevents 事件的数据推到输入的主题中。这个类似于一个真实的生产步骤,数据从生产到落地。
Step 3: Recovery
一旦重新启动TaskManager,它将会重新链接master
docker-compose up -d taskmanager
当master注意到了新的Taskmanager,它规划一下资源将可用的TaskSlots分配给作业用来恢复。重启过程,任务恢复他们的状态从最近一次成功的检查点也就是在转换状态时候失败的那次。
作业将会很快的处理挤压的日志从输入的事件中并且处理输出在一个很高的处理速度(> 24 条/分钟),直到处理完毕。在输出结果中我们会看到 关键字也就是我们的page字段是当前的时间窗口的并且每个统计量是精确的1000.因为我们使用了 FlinkKafkaProducer 最少一次的模式,所以会存在一个问题就是我们会看到有重复的数据输出。
Node:大多的生产环境我们都是用资源调度集群来自动处理重启失败的程序的,像:k8s,yarn,mesos这种。我们项目组用的yarn。
Upgrading & Rescaling a Job
升级一个flink作业设计到两个步骤:第一,采用保存点优雅的停止一个作业。保存点是一个在完成一个应用状态的一个一致性数据定义的快照机制,类似于检查点,保存点是用户自己定义的。第二,升级的作业从保存点开始,在这个上下文中“升级”可以标示不同的事情,包括如下:
对于配置文件的升级;
作业拓扑的升级添加或者移除一个操作;
作业中用户定义的一个方法升级
在你开始升级之前你可能需要去跟踪一下输出的主题topic,为了避免数据的丢失。
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
Step 1: Stopping the Job
我们可以优雅的停止掉任务,通过获取job的id来停止。我们有两种方式cli和rest api。
Cli
Command
docker-compose run --no-deps client flink stop <job-id>
Expected Output
Suspending job "<job-id>" with a savepoint.
Suspended job "<job-id>" with a savepoint.
保存点被保存在state.savepoint.dir 这个路径下面,是通过flink-conf.yaml来配置的,这个被挂载在/tmp/flink-savepoints-directory/ 路径在我们的本地机器。接下来的步骤不要这个保存点的路径,如果rest api 相应的已经是这个路径,那么我们直接查看就可以。
command
ls -lia /tmp/flink-savepoints-directory
Expected Output
total 0
17 drwxr-xr-x 3 root root 60 17 jul 17:05 .
2 drwxrwxrwt 135 root root 3420 17 jul 17:09 ..
1002 drwxr-xr-x 2 root root 140 17 jul 17:05 savepoint-<short-job-id>-<uuid>
REST API
Request
# triggering stop
curl -X POST localhost:8081/jobs/<job-id>/stop -d '{"drain": false}'
Expected Response (pretty-printed)
{
"request-id": "<trigger-id>"}
Request
# check status of stop action and retrieve savepoint path
curl localhost:8081/jobs/<job-id>/savepoints/<trigger-id>
Expected Response (pretty-printed)
{
"status": {
"id": "COMPLETED"
},
"operation": {
"location": "<savepoint-path>"
}
Step 2a: Restart Job without Changes
我们可以升级一个作业不做任何改变
Cli
Command
docker-compose run --no-deps client flink run -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time
Expected Output
Starting execution of program
Job has been submitted with JobID <job-id>
REST API
Command
docker-compose run --no-deps client flink run -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time
Expected Output
Starting execution of program
Job has been submitted with JobID <job-id>
一旦作业再次运行状态,你将会看到输出的主题topic数据被产生。此外,你也会看到数据没有丢失在这次升级。
Step 2b: Restart Job with a Different Parallelism (Rescaling)
此外,你可能对于重新提交的作业需要改变它的并行度
Cli
Command
docker-compose run --no-deps client flink run -p 3 -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time
Expected Output
Starting execution of program
Job has been submitted with JobID <job-id>
REST API
Request
# Uploading the JAR from the Client container
docker-compose run --no-deps client curl -X POST -H "Expect:" \
-F "jarfile=@/opt/ClickCountJob.jar" http://jobmanager:8081/jars/upload
Expected Response (pretty-printed)
{
"filename": "/tmp/flink-web-<uuid>/flink-web-upload/<jar-id>",
"status": "success"}
Request
# Submitting the Job
curl -X POST http://localhost:8081/jars/<jar-id>/run \
-d '{"parallelism": 3, "programArgs": "--bootstrap.servers kafka:9092 --checkpointing --event-time", "savepointPath": "<savepoint-path>"}'
Expected Response (pretty-printed
{
"jobid": "<job-id>"}
作业被重新提交,但是不是3 个并行度 因为没有足够的任务槽给它只有两个有效。
docker-compose scale taskmanager=2
你可能添加第二个TaskManager 用两个任务槽。添加完以后作业再次运行起来。一旦作业再次是“RUNNING”,我们就能从输出的那个主题topic看到数据,同时数据也没有丢失。
Querying the Metrics of a Job
https://ci.apache.org/projects/flink/flink-docs-release-1.10/monitoring/metrics.html
Flink master对外提供了系统和用户指标通过REST API的方式。我们可以通过api获取作业的指标信息。接口不只是提供了查询指标的信息,同时可以通过查看更加信息的信息关于运行作业的状态,我们更好的去监控我们的作业。
https://ci.apache.org/projects/flink/flink-docs-release-1.10/monitoring/rest_api.html#api
Variants
你可能已经注意到了 Click Event Count 应用总是开始携带着 检查点 和 事件时间程序参数。在docker-compose.yaml客户端容器命令中可以省略这些,你可以改变作业的行为。
--checkpointing 参数开启 checkpoint 机制(https://ci.apache.org/projects/flink/flink-docs-release-1.10/internals/stream_checkpointing.html) flink的一种失败恢复机制。如果你重启作业没有这个机制,那么很可能你会看到数据的丢失。
--event-time 开启作业的事件时间机制(https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/event_time.html).当没有启用的时候,作业会按照实际的达到的时间替换ClickEvent的时间戳。 因此这样窗口的每个事件的数量就不再是精准的1000.点击事件数量应用也有其他的选项,默认关闭,你也可以开启去探测这些作业的行为在反压下。你可以在docker-compose。yaml所在的客户端容器添加这个选项用命令。
--backpressure 添加额外的操作在作业的中间引起服务反压的情况在偶数分钟期间例如:10:12期间,而不是10:13期间。这个可以通过检测网络指标来观察 像:outputQueueLength 和 outPoolUsage。并且或者通过flink 的webui中可用的反压监控来观察。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号