Code Walkthroughs Table API
上级:https://www.cnblogs.com/hackerxiaoyon/p/12747387.html
Table API
Table api 有批量的api和流实时的api。通常很容易进行数据分析、批量数据导入 和 做一些数据清洗的工作。
What Will You Be Building? 案例说明
此案例需要构建一个数据清洗的通道用来随时间跟踪金融交易,构建一个夜间的批量作业然后集成到流通道中。
Prerequisites 前提
需要你具备java 或 scala的知识,当然你有其他语言也是可以的,同时这方面也是需要具备一定的sql 的知识。
Help,I’m Stuck! 寻求帮助
如果你卡住了,可以 求助 https://flink.apache.org/gettinghelp.html 。
https://flink.apache.org/community.html#mailing-lists 用户邮件列表是一个活跃快速提供帮助的地方。
How To Follow Along 如何跟进
环境
l Java 8 or 11
l Maven
构建java 程序demo
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-table-java \
-DarchetypeVersion=1.10.0 \
-DgroupId=spend-report \
-DartifactId=spend-report \
-Dversion=0.1 \
-Dpackage=spendreport \
-DinteractiveMode=false
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
tEnv.registerTableSource("transactions", new BoundedTransactionTableSource());
tEnv.registerTableSink("spend_report", new SpendReportTableSink());
tEnv.registerFunction("truncateDateToHour", new TruncateDateToHour());
tEnv.scan("transactions").insertInto("spend_report");
env.execute("Spend Report");
Breaking Down The Code分解一下代码
执行环境
java语言
这是个批量的环境,也就是你在接source的时候,可以是流还是批量。这是批量的Table api方式。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
Registering Tables
然后我们可以注册一个表方式在执行环境中,同时可以接内部系统读写批流数据。一个表数据源提供把数据写到内部系统中,像:数据库,key-value的存储redis,消息队列,或者是文件系统。基本就是接数据源source,中间业务处理,最后sink落地。
tEnv.registerTableSource("transactions", new BoundedTransactionTableSource());
tEnv.registerTableSink("spend_report", new SpendReportTableSink());
这里我们注册了两个表,一个输入table,一个输出table。 transactions表让我们读取信用卡交易信息,包含账号,交易时间,交易额度。
Registering A UDF
注册一个udf,也就是用户自定义函数。具体TruncateDateToHour代码需要你在构建代码后在你的IDE中查看。
tEnv.registerFunction("truncateDateToHour", new TruncateDateToHour());
The Query
tEnv
.scan("transactions")
.insertInto("spend_report");
查看然后插入没有做其他的操作。
Execute
执行代码
env.execute("Spend Report");
Attempt One 尝试一下
tEnv
.scan("transactions")
.select("accountId, timestamp.truncateDateToHour as timestamp, amount")
.groupBy("accountId, timestamp")
.select("accountId, timestamp, amount.sum as total")
.insertInto("spend_report");
你尝试跑这个代码的时候肯定会报错
Caused by: java.lang.ClassNotFoundException: org.apache.flink.table.api.java.internal.BatchTableEnvironmentImpl
因为没有依赖有冲突,所以查看你的冲突直接把对应的排除就好。直接运行你的代码。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>org.apache.flink:flink-table-api-java-*</artifactId>
</exclusion>
</exclusions>
</dependency>
代码结果太长了,我截图简单的看一下。
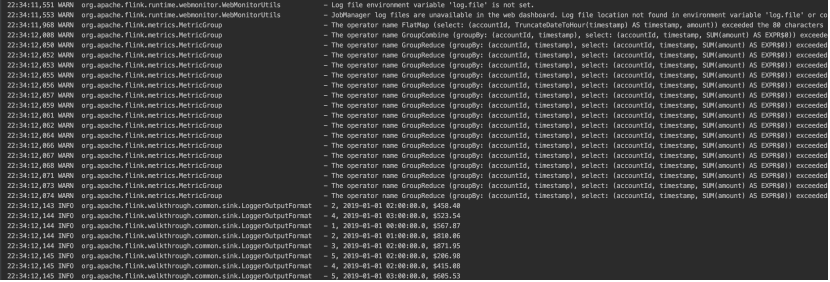
查询表,表中有三个字段,然后我们根据账号,时间分组,计算每个时间段对应的总钱数。然后sink的时候打印出来。
Adding Windows 添加窗口
窗口在我们flink经常使用的一种策略,keyed 窗口,no-keyed窗口。然后有三种指定的窗口类型,之前我记得是三种,分别是:滚动窗口,滑动窗口,会话窗口,全局窗口。等到了窗口的地方我们再细说。执行下面的代码,意思是统计按照时间字段一小时一个窗口进行统计的数据。
tEnv
.scan("transactions")
.window(Tumble.over("1.hour").on("timestamp").as("w"))
.groupBy("accountId, w")
.select("accountId, w.start as timestamp, amount.sum")
.insertInto("spend_report");
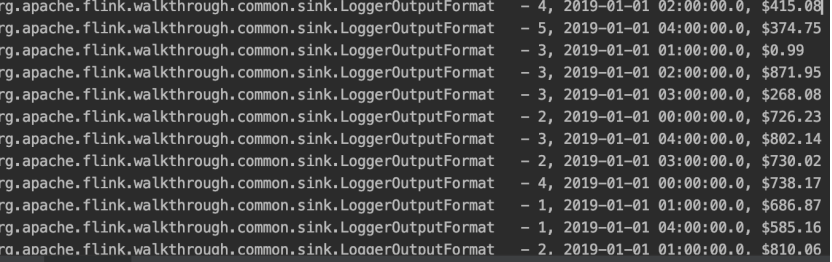
Once More, With Streaming! 再来个流计算
因为table api提供了两种一种batch一种是streaming。我们将环境换成如下就可以了,其他代码不变,直接运行。
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号