大数据之路【第十三篇】:数据挖掘---中文分词
一、数据挖掘---中文分词
• 一段文字不仅仅在于字面上是什么,还在于怎么切分和理解。
• 例如:
– 阿三炒饭店:
– 阿三 / 炒饭 / 店 阿三 / 炒 / 饭店
• 和英文不同,中文词之间没有空格,所以实现中文搜索引擎,比英文多了一项分
词的任务。
• 如果没有中文分词会出现:
– 搜索“达内”,会出现“齐达内”相关的信息
• 要解决中文分词准确度的问题,是否可以提供一个免费版本的通用分词程序?
– 像分词这种自然语言处理领域的问题,很难彻底完全解决
– 每个行业或业务侧重不同,分词工具设计策略也是不一样的
二、切分方案

• 切开的开始位置对应位是1,否则对应位是0,来表示“有/意见/分歧”的bit内容是:11010
• 还可以用一个分词节点序列来表示切分方案,例如“有/意见/分歧”的分词节点序列是{0,1,3,5}
三、最常见的方法
• 最常见的分词方法是基于词典匹配
– 最大长度查找(前向查找,后向查找)
• 数据结构
– 为了提高查找效率,不要逐个匹配词典中的词
– 查找词典所占的时间可能占总的分词时间的1/3左右,为了保证切分速度,需要选择一个好
的查找词典方法
– Trie树常用于加速分词查找词典问题
四、Trie树

切分词图
五、概率语言模型
• 假设需要分出来的词在语料库和词表中都存在,最简单的方法是按词计算概率,
而不是按字算概率。
• 从统计思想的角度来看,分词问题的输入是一个字串C=c1,c2……cn ,输出是一
个词串S=w1,w2……wm ,其中m<=n。对于一个特定的字符串C,会有多个切
分方案S对应,分词的任务就是在这些S中找出一个切分方案S,使得P(S|C)的值
最大。
• P(S|C)就是由字符串C产生切分S的概率,也就是对输入字符串切分出最有可能的
词序列
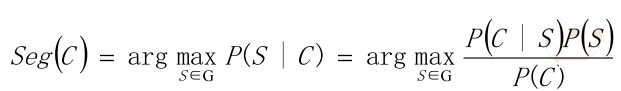
例子:
• 例如:对于输入字符串C“南京市长江大桥”,有下面两种切分可能:
– S1:南京市 / 长江 / 大桥
– S2:南京 / 市长 / 江大桥
• 这两种切分方法分别叫做S1和S2。计算条件概率P(S1|C)和P(S2|C),然后根据
P(S1|C)和P(S2|C)的值来决定选择S1还是S2。
• P(C)是字串在语料库中出现的概率。比如说语料库中有1万个句子,其中有一句
是 “南京市长江大桥”那么P(C)=P(“南京市长江大桥”)=万分之一。
• 因为P(C∩S) = P(S|C)*P(C) = P(C|S)*P(S),所以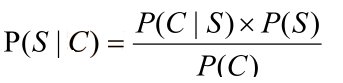
• 贝叶斯公式:

• P(C)只是一个用来归一化的固定值
• 另外:从词串恢复到汉字串的概率只有唯一的一种方式,所以P(C|S)=1。
• 所以:比较P(S1|C)和P(S2|C)的大小变成比较P(S1)和P(S2) 的大小
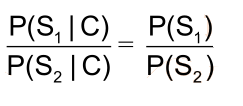
• 因为P(S1)=P(南京市,长江,大桥)=P(南京市)*P(长江)*P(大桥) > P(S2)=P(南京,市
长,江大桥),所以选择切分方案S1
例子三:
• 为了容易实现,假设每个词之间的概率是上下文无关的,则:

• 其中,P(w) 就是这个词出现在语料库中的概率。因为函数y=log(x),当x增大,
y也会增大,所以是单调递增函数。∝是正比符号。因为词的概率小于1,所以取
log后是负数。
• 最后算 logP(w)。取log是为了防止向下溢出,如果一个数太小,例如0.000000000000000000000000000001 可能会向下溢出。
• 如果这些对数值事前已经算出来了,则结果直接用加法就可以得到,而加法比乘法速度更快。
六、一元模型
• 对于不同的S,m的值是不一样的,一般来说m越大,P(S)会越小。也就是说,分出的词越多,概率越小。

七、N元模型
• 假设在日本,[和服]也是一个常见的词。按照一元概率分词,可能会把“产品和服务”分成[产品][和服][务]。为了切分更准确,要考虑词所处的上下文。
• 给定一个词,然后猜测下一个词是什么。当我说“NBA”这个词时,你想到下
一个词是什么呢?我想大家有可能会想到“篮球”,基本上不会有人会想到“足
球”吧。
• 之前为了简便,所以做了“前后两词出现概率是相互独立的”的假设在实际中是
不成立的
• N元模型使用n个单词组成的序列来衡量切分方案的合理性:
• 估计单词w1后出现w2的概率。根据条件概率的定义: 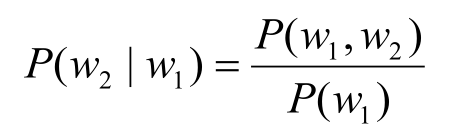
• 可以得到:P(w1,w2)= P(w1)P(w2|w1)
• 同理:P(w1,w2,w3)= P(w1,w2)P(w3|w1,w2)
• 所以有:P(w1,w2,w3)= P(w1)P(w2|w1)P(w3|w1,w2)
• 更加一般的形式:
• P(S)=P(w1,w2,...,wn)= P(w1)P(w2|w1)P(w3|w1,w2)…P(wn|w1w2…wn-1)
• 这叫做概率的链规则。
八、Jieba分词简介
• 源码下载的地址:https://github.com/fxsjy/jieba
• 支持三种分词模式
– 精确模式:将句子最精确的分开,适合文本分析
– 全模式:句子中所有可以成词的词语都扫描出来,速度快,不能解决歧义
– 搜索引擎模式:在精确模式基础上,对长词再次切分,提高召回
• 支持繁体分词
• 支持自定义字典
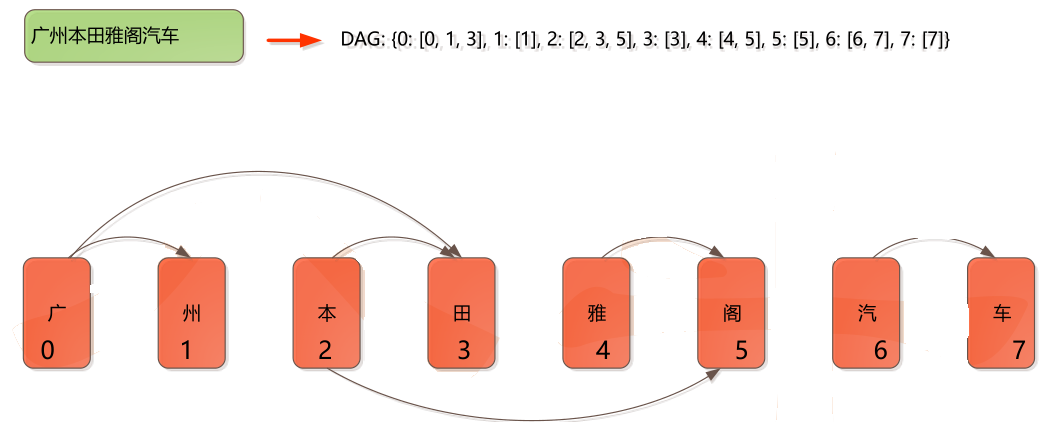
• 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成
的有向无环图(DAG)
• 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
• 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
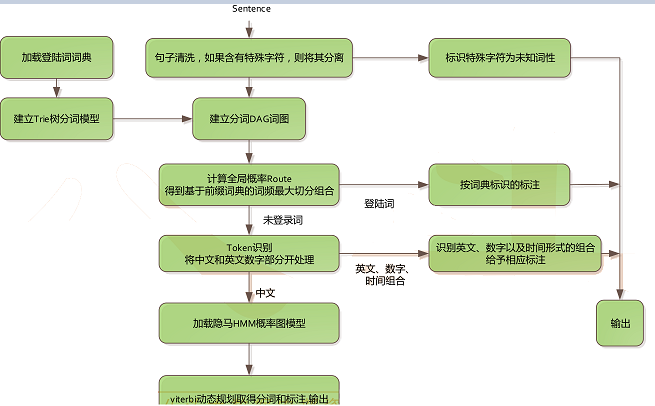
九、Jieba分词细节

 浙公网安备 33010602011771号
浙公网安备 33010602011771号