Linux用户空间与内核地址空间
Linux 操作系统和驱动程序运行在内核空间,应用程序运行在用户空间,两者不能简单地使用指针传递数据,因为Linux使用的虚拟内存机制,用户空间的数据可能被换出,当内核空间使用用户空间指针时,对应的数据可能不在内存中。
Linux内核地址映射模型
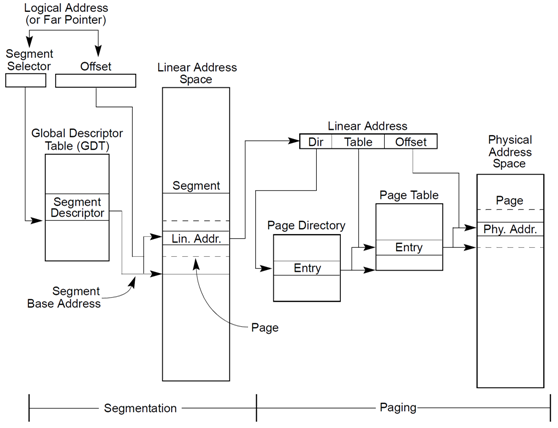
x86 CPU采用了段页式地址映射模型。进程代码中的地址为逻辑地址,经过段页式地址映射后,才真正访问物理内存。
段页式机制如下图。
linux内核地址空间划分
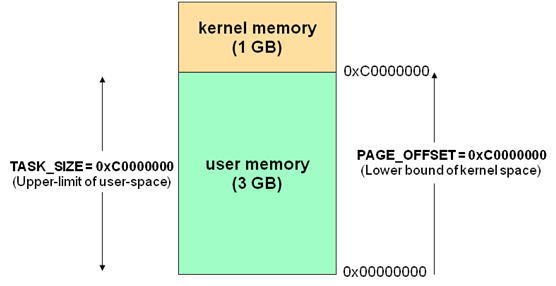
通常32位Linux内核地址空间划分0~3G为用户空间,3~4G为内核空间。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
Linux内核高端内存的由来
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射,如逻辑地址0xc0000003对应的物理地址为0×3,0xc0000004对应的物理地址为0×4,… …,逻辑地址与物理地址对应的关系为
物理地址 = 逻辑地址 – 0xC0000000
| 逻辑地址 | 物理内存地址 |
| 0xc0000000 | 0×0 |
| 0xc0000001 | 0×1 |
| 0xc0000002 | 0×2 |
| 0xc0000003 | 0×3 |
| … | … |
| 0xe0000000 | 0×20000000 |
| … | … |
| 0xffffffff | 0×40000000 ?? |
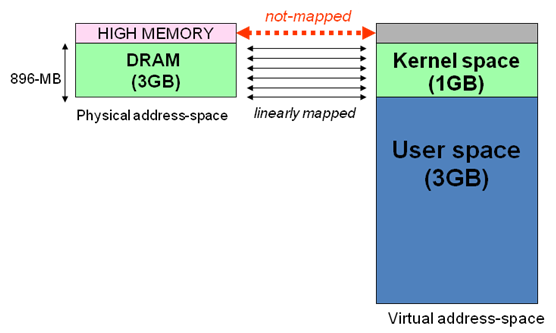
假 设按照上述简单的地址映射关系,那么内核逻辑地址空间访问为0xc0000000 ~ 0xffffffff,那么对应的物理内存范围就为0×0 ~ 0×40000000,即只能访问1G物理内存。若机器中安装8G物理内存,那么内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核 的地址空间已经全部映射到物理内存地址范围0×0 ~ 0×40000000。即使安装了8G物理内存,那么物理地址为0×40000001的内存,内核该怎么去访问呢?代码中必须要有内存逻辑地址 的,0xc0000000 ~ 0xffffffff的地址空间已经被用完了,所以无法访问物理地址0×40000000以后的内存。
显 然不能将内核地址空间0xc0000000 ~ 0xfffffff全部用来简单的地址映射。因此x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和 ZONE_HIGHMEM。ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域如下:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束
Linux内核高端内存的理解
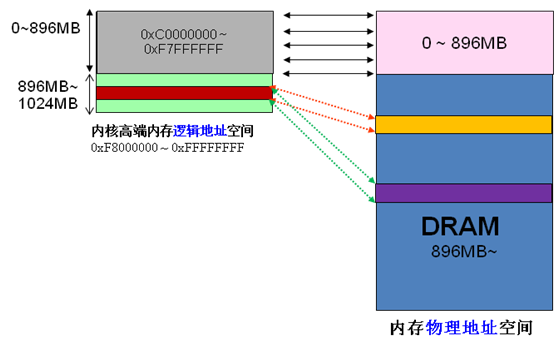
前 面我们解释了高端内存的由来。 Linux将内核地址空间划分为三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端内存HIGH_MEM地址空间范围为 0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。如下图。
例 如内核想访问2G开始的一段大小为1MB的物理内存,即物理地址范围为0×80000000 ~ 0x800FFFFF。访问之前先找到一段1MB大小的空闲地址空间,假设找到的空闲地址空间为0xF8700000 ~ 0xF87FFFFF,用这1MB的逻辑地址空间映射到物理地址空间0×80000000 ~ 0x800FFFFF的内存。映射关系如下:
| 逻辑地址 | 物理内存地址 |
| 0xF8700000 | 0×80000000 |
| 0xF8700001 | 0×80000001 |
| 0xF8700002 | 0×80000002 |
| … | … |
| 0xF87FFFFF | 0x800FFFFF |
当内核访问完0×80000000 ~ 0x800FFFFF物理内存后,就将0xF8700000 ~ 0xF87FFFFF内核线性空间释放。这样其他进程或代码也可以使用0xF8700000 ~ 0xF87FFFFF这段地址访问其他物理内存。
从上面的描述,我们可以知道高端内存的最基本思想:借一段地址空间,建立临时地址映射,用完后释放,达到这段地址空间可以循环使用,访问所有物理内存。
看到这里,不禁有人会问:万一有内核进程或模块一直占用某段逻辑地址空间不释放,怎么办?若真的出现的这种情况,则内核的高端内存地址空间越来越紧张,若都被占用不释放,则没有建立映射到物理内存都无法访问了。
在 香港尖沙咀有些写字楼,洗手间很少且有门锁的。客户要去洗手间的话,可以向前台拿钥匙,方便完后,把钥匙归还到前台。这样虽然只有一个洗 手间,但可以满足所有客户去洗手间的需求。要是某个客户一直占用洗手间、钥匙不归还,那么其他客户都无法上洗手间了。Linux内核高端内存管理的思想类 似。
Linux内核高端内存的划分
内核将高端内存划分为3部分:VMALLOC_START~VMALLOC_END、KMAP_BASE~FIXADDR_START和FIXADDR_START~4G。
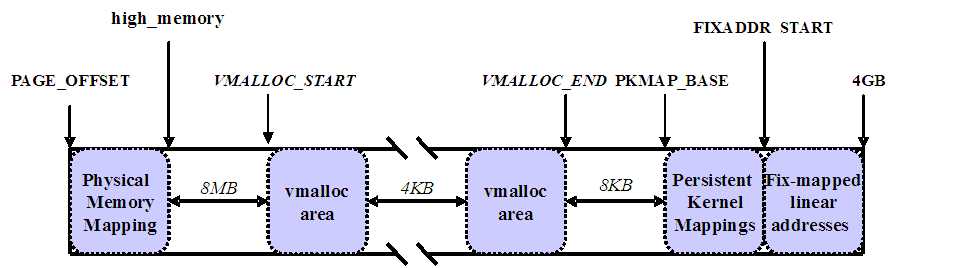
对
于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page
转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page
找一个线性空间,这个过程称为高端内存映射。
对应高端内存的3部分,高端内存映射有三种方式:
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面(参看 vmalloc 的实现),因此说高端内存有可能映射到”内核动态映射空间”中。
持久内核映射(permanent kernel mapping)
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是
4G-8M 到 4G-4M
之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是
swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来
pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个
page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的
page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。
临时映射(temporary kernel mapping)
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。
这块空间具有如下特点:
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。
常见问题:
1、用户空间(进程)是否有高端内存概念?
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和逻辑地址有关系,和逻辑地址、物理地址没有直接关系。
5、为什么不把所有的地址空间都分配给内核?
若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?
(1)让我们忽略Linux对段式内存映射的支持。
在保护模式下,我们知道无论CPU运行于用户态还是核心态,CPU执行程序所访问的地址都是虚拟地址,MMU
必须通过读取控制寄存器CR3中的值作为当前页面目录的指针,进而根据分页内存映射机制(参看相关文档)将该虚拟地址转换为真正的物理地址才能让CPU真
正的访问到物理地址。
(2)对于32位的Linux,其每一个进程都有4G的寻址空间,但当一个进程访问其虚拟内存空间中的某个地址时又是怎样实现不与其它进程的虚拟空间混淆
的呢?每个进程都有其自身的页面目录PGD,Linux将该目录的指针存放在与进程对应的内存结构task_struct.(struct
mm_struct)mm->pgd中。每当一个进程被调度(schedule())即将进入运行态时,Linux内核都要用该进程的PGD指针设
置CR3(switch_mm())。
(3)当创建一个新的进程时,都要为新进程创建一个新的页面目录PGD,并从内核的页面目录swapper_pg_dir中复制内核区间页面目录项至新建进程页面目录PGD的相应位置,具体过程如下:
do_fork() --> copy_mm() --> mm_init() --> pgd_alloc() -->
set_pgd_fast() --> get_pgd_slow() --> memcpy(&PGD +
USER_PTRS_PER_PGD, swapper_pg_dir + USER_PTRS_PER_PGD, (PTRS_PER_PGD -
USER_PTRS_PER_PGD) * sizeof(pgd_t))
这样一来,每个进程的页面目录就分成了两部分,第一部分为“用户空间”,用来映射其整个进程空间(0x0000 0000-0xBFFF
FFFF)即3G字节的虚拟地址;第二部分为“系统空间”,用来映射(0xC000 0000-0xFFFF
FFFF)1G字节的虚拟地址。可以看出Linux系统中每个进程的页面目录的第二部分是相同的,所以从进程的角度来看,每个进程有4G字节的虚拟空间,
较低的3G字节是自己的用户空间,最高的1G字节则为与所有进程以及内核共享的系统空间。
(4)现在假设我们有如下一个情景:
在进程A中通过系统调用sethostname(const char *name,seze_t len)设置计算机在网络中的“主机名”.
在该情景中我们势必涉及到从用户空间向内核空间传递数据的问题,name是用户空间中的地址,它要通过系统调用设置到内核中的某个地址中。让我们看看这个
过程中的一些细节问题:系统调用的具体实现是将系统调用的参数依次存入寄存器ebx,ecx,edx,esi,edi(最多5个参数,该情景有两个
name和len),接着将系统调用号存入寄存器eax,然后通过中断指令“int
80”使进程A进入系统空间。由于进程的CPU运行级别小于等于为系统调用设置的陷阱门的准入级别3,所以可以畅通无阻的进入系统空间去执行为int
80设置的函数指针system_call()。由于system_call()属于内核空间,其运行级别DPL为0,CPU要将堆栈切换到内核堆栈,即
进程A的系统空间堆栈。我们知道内核为新建进程创建task_struct结构时,共分配了两个连续的页面,即8K的大小,并将底部约1k的大小用于
task_struct(如#define alloc_task_struct() ((struct task_struct *)
__get_free_pages(GFP_KERNEL,1))),而其余部分内存用于系统空间的堆栈空间,即当从用户空间转入系统空间时,堆栈指针
esp变成了(alloc_task_struct()+8192),这也是为什么系统空间通常用宏定义current(参看其实现)获取当前进程的
task_struct地址的原因。每次在进程从用户空间进入系统空间之初,系统堆栈就已经被依次压入用户堆栈SS、用户堆栈指针ESP、EFLAGS、
用户空间CS、EIP,接着system_call()将eax压入,再接着调用SAVE_ALL依次压入ES、DS、EAX、EBP、EDI、ESI、
EDX、ECX、EBX,然后调用sys_call_table+4*%EAX,本情景为sys_sethostname()。
(5)在sys_sethostname()中,经过一些保护考虑后,调用copy_from_user(to,from,n),其中to指向内核空间
system_utsname.nodename,譬如0xE625A000,from指向用户空间譬如0x8010FE00。现在进程A进入了内核,在
系统空间中运行,MMU根据其PGD将虚拟地址完成到物理地址的映射,最终完成从用户空间到系统空间数据的复制。准备复制之前内核先要确定用户空间地址和
长度的合法性,至于从该用户空间地址开始的某个长度的整个区间是否已经映射并不去检查,如果区间内某个地址未映射或读写权限等问题出现时,则视为坏地址,
就产生一个页面异常,让页面异常服务程序处理。过程如
下:copy_from_user()->generic_copy_from_user()->access_ok()+__copy_user_zeroing().
(6)小结:
*进程寻址空间0~4G
*进程在用户态只能访问0~3G,只有进入内核态才能访问3G~4G
*进程通过系统调用进入内核态
*每个进程虚拟空间的3G~4G部分是相同的
*进程从用户态进入内核态不会引起CR3的改变但会引起堆栈的改变
Linux
简化了分段机制,使得虚拟地址与线性地址总是一致,因此,Linux的虚拟地址空间也为0~4G。Linux内核将这4G字节的空间分为两部分。将最高的
1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为“内核空间”。而将较低的3G字节(从虚拟地址
0x00000000到0xBFFFFFFF),供各个进程使用,称为“用户空间)。因为每个进程可以通过系统调用进入内核,因此,Linux内核由系统
内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有4G字节的虚拟空间。
Linux使用两级保护机制:0级供内核使用,3级供用户程序使用。从图中可以看出(这里无法表示图),每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的。最高的1GB字节虚拟内核空间则为所有进程以及内核所共享。
1.虚拟内核空间到物理空间的映射
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。读者会问,系
统启动时,内核的代码和数据不是被装入到物理内存吗?它们为什么也处于虚拟内存中呢?这和编译程序有关,后面我们通过具体讨论就会明白这一点。
虽
然内核空间占据了每个虚拟空间中的最高1GB字节,但映射到物理内存却总是从最低地址(0x00000000)开始。对内核空间来说,其地址映射是很简单
的线性映射,0xC0000000就是物理地址与线性地址之间的位移量,在Linux代码中就叫做PAGE_OFFSET。
我们来看一下在include/asm/i386/page.h中对内核空间中地址映射的说明及定义:
/*
* This handles the memory map.. We could make this a config
* option, but too many people screw it up, and too few need
* it.
*
* A __PAGE_OFFSET of 0xC0000000 means that the kernel has
* a virtual address space of one gigabyte, which limits the
* amount of physical memory you can use to about 950MB.
*
* If you want more physical memory than this then see the CONFIG_HIGHMEM4G
* and CONFIG_HIGHMEM64G options in the kernel configuration.
*/
#define __PAGE_OFFSET (0xC0000000)
……
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
源
代码的注释中说明,如果你的物理内存大于950MB,那么在编译内核时就需要加CONFIG_HIGHMEM4G和CONFIG_HIGHMEM64G选
项,这种情况我们暂不考虑。如果物理内存小于950MB,则对于内核空间而言,给定一个虚地址x,其物理地址为“x-
PAGE_OFFSET”,给定一个物理地址x,其虚地址为“x+ PAGE_OFFSET”。
这里再次说明,宏__pa()仅仅把一个内核空间的虚地址映射到物理地址,而决不适用于用户空间,用户空间的地址映射要复杂得多。
2.内核映像
在下面的描述中,我们把内核的代码和数据就叫内核映像(kernel
image)。当系统启动时,Linux内核映像被安装在物理地址0x00100000开始的地方,即1MB开始的区间(第1M留作它用)。然而,在正常
运行时,
整个内核映像应该在虚拟内核空间中,因此,连接程序在连接内核映像时,在所有的符号地址上加一个偏移量PAGE_OFFSET,这样,内核映像在内核空间
的起始地址就为0xC0100000。
例如,进程的页目录PGD(属于内核数据结构)就处于内核空间中。在进程切换时,要将寄存器CR3设置成指
向新进程的页目录PGD,而该目录的起始地址在内核空间中是虚地址,但CR3所需要的是物理地址,这时候就要用__pa()进行地址转换。在
mm_context.h中就有这么一行语句:
asm volatile(“movl %0,%%cr3”: :”r” (__pa(next->pgd));
这是一行嵌入式汇编代码,其含义是将下一个进程的页目录起始地址next_pgd,通过__pa()转换成物理地址,存放在某个寄存器中,然后用mov指令将其写入CR3寄存器中。经过这行语句的处理,CR3就指向新进程next的页目录表PGD了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号