分布式 PostgreSQL 集群(Citus)官方示例 - 实时仪表盘
Citus 提供对大型数据集的实时查询。我们在 Citus 常见的一项工作负载涉及为事件数据的实时仪表板提供支持。
例如,您可以是帮助其他企业监控其 HTTP 流量的云服务提供商。每次您的一个客户端收到 HTTP 请求时,您的服务都会收到一条日志记录。您想要摄取所有这些记录并创建一个 HTTP 分析仪表板,为您的客户提供洞察力,例如他们的网站服务的 HTTP 错误数量。 重要的是,这些数据以尽可能少的延迟显示出来,这样您的客户就可以解决他们网站的问题。 仪表板显示历史趋势图也很重要。
或者,也许您正在建立一个广告网络,并希望向客户展示其广告系列的点击率。 在此示例中,延迟也很关键,原始数据量也很高,历史数据和实时数据都很重要。
在本节中,我们将演示如何构建第一个示例的一部分,但该架构同样适用于第二个和许多其他用例。
- real-time-analytics-Hands-On-Lab-Hyperscale-Citus
- Architecting Real-Time Analytics for your Customers
数据模型
我们正在处理的数据是不可变的日志数据流。我们将直接插入 Citus,但这些数据首先通过 Kafka 之类的东西进行路由也很常见。 这样做具有通常的优势,并且一旦数据量变得难以管理,就可以更容易地预先聚合数据。
我们将使用一个简单的 schema 来摄取 HTTP 事件数据。 这个 schema 作为一个例子来展示整体架构;一个真实的系统可能会使用额外的列。
-- this is run on the coordinator
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
SELECT create_distributed_table('http_request', 'site_id');
当我们调用 create_distributed_table 时,我们要求 Citus 使用 site_id 列对 http_request 进行 hash 分配。 这意味着特定站点的所有数据都将存在于同一个分片中。
- create_distributed_table
UDF 使用分片计数的默认配置值。我们建议在集群中使用 2-4 倍于 CPU 核的分片。使用这么多分片可以让您在添加新的工作节点后重新平衡集群中的数据。
Azure Database for PostgreSQL — 超大规模 (Citus) 使用流式复制来实现高可用性,因此维护分片副本将是多余的。在任何流复制不可用的生产环境中,您应该将 citus.shard_replication_factor 设置为 2 或更高以实现容错。
- Azure Database for PostgreSQL
- 流式复制
有了这个,系统就可以接受数据并提供查询了! 在继续执行本文中的其他命令时,让以下循环在后台的 psql 控制台中运行。 它每隔一两秒就会生成假数据。
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
摄取数据后,您可以运行仪表板查询,例如:
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
上述设置有效,但有两个缺点:
- 每次需要生成图表时,您的 HTTP 分析仪表板都必须遍历每一行。 例如,如果您的客户对过去一年的趋势感兴趣,您的查询将从头开始汇总过去一年的每一行。
- 您的存储成本将随着摄取率和可查询历史的长度成比例增长。 在实践中,您可能希望将原始事件保留较短的时间(一个月)并查看较长时间(年)的历史图表。
汇总
您可以通过将原始数据汇总为预聚合形式来克服这两个缺点。 在这里,我们将原始数据汇总到一个表中,该表存储 1 分钟间隔的摘要。 在生产系统中,您可能还需要类似 1 小时和 1 天的间隔,这些都对应于仪表板中的缩放级别。 当用户想要上个月的请求时间时,仪表板可以简单地读取并绘制过去 30 天每一天的值。
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
SELECT create_distributed_table('http_request_1min', 'site_id');
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
这看起来很像前面的代码块。最重要的是:它还在 site_id 上进行分片,并对分片计数和复制因子使用相同的默认配置。因为这三个都匹配,所以 http_request 分片和 http_request_1min 分片之间存在一对一的对应关系,Citus 会将匹配的分片放在同一个 worker 上。这称为协同定位(co-location); 它使诸如联接(join)之类的查询更快,并使我们的汇总成为可能。
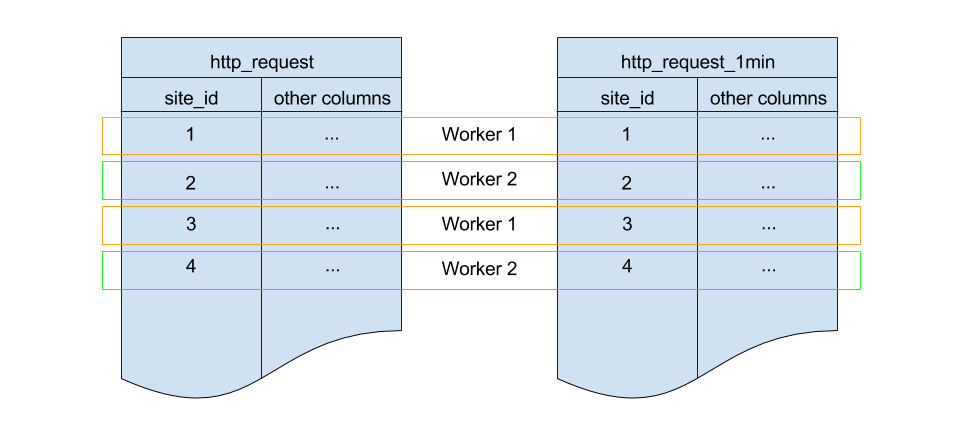
为了填充 http_request_1min,我们将定期运行 INSERT INTO SELECT。 这是可能的,因为这些表位于同一位置。为方便起见,以下函数将汇总查询包装起来。
-- single-row table to store when we rolled up last
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
-- "minute" should be no more precise than a minute
CHECK (minute = date_trunc('minute', minute))
);
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
上述函数应该每分钟调用一次。您可以通过在 coordinator 节点上添加一个 crontab 条目来做到这一点:
* * * * * psql -c 'SELECT rollup_http_request();'
或者,诸如 pg_cron 之类的扩展允许您直接从数据库安排周期性查询。
之前的仪表板查询现在好多了:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
过期的旧数据
汇总使查询更快,但我们仍然需要使旧数据过期以避免无限的存储成本。 只需决定您希望为每个粒度保留数据多长时间,然后使用标准查询删除过期数据。 在以下示例中,我们决定将原始数据保留一天,将每分钟的聚合保留一个月:
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
在生产中,您可以将这些查询包装在一个函数中,并在 cron job 中每分钟调用一次。
通过在 Citrus 哈希分布之上使用表范围分区,数据过期可以更快。 有关详细示例,请参阅时间序列数据部分。
这些是基础!我们提供了一种架构,可以摄取 HTTP 事件,然后将这些事件汇总到它们的预聚合形式中。 这样,您既可以存储原始事件,也可以通过亚秒级查询为您的分析仪表板提供动力。
接下来的部分将扩展基本架构,并向您展示如何解决经常出现的问题。
近似不同计数
HTTP 分析中的一个常见问题涉及近似的不同计数:上个月有多少独立访问者访问了您的网站?准确地回答这个问题需要将所有以前见过的访问者的列表存储在汇总表中,这是一个令人望而却步的数据量。然而,一个近似的答案更易于管理。
一种称为 hyperloglog 或 HLL 的数据类型可以近似地回答查询; 要告诉您一个集合中大约有多少个独特元素,需要的空间非常小。其精度可以调整。 我们将使用仅使用 1280 字节的那些,将能够以最多 2.2% 的错误计算多达数百亿的唯一访问者。
如果您要运行全局查询,则会出现类似的问题,例如在上个月访问您客户的任何站点的唯一 IP 地址的数量。在没有 HLL 的情况下,此查询涉及将 IP 地址列表从 worker 传送到 coordinator 以进行重复数据删除。这既是大量的网络流量,也是大量的计算。 通过使用 HLL,您可以大大提高查询速度。
首先你必须安装 HLL 扩展;github repo 有说明。接下来,您必须启用它:
- postgresql-hll
CREATE EXTENSION hll;
这在 Hyperscale 上是不必要的,它已经安装了 HLL 以及其他有用的扩展。
现在我们准备好在 HLL 汇总中跟踪 IP 地址。首先向汇总表添加一列。
ALTER TABLE http_request_1min ADD COLUMN distinct_ip_addresses hll;
接下来使用我们的自定义聚合来填充列。 只需将它添加到我们汇总函数中的查询中:
@@ -1,10 +1,12 @@
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
+ , distinct_ip_addresses
) SELECT
site_id,
minute,
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
+ , hll_add_agg(hll_hash_text(ip_address)) AS distinct_ip_addresses
FROM http_request
仪表板查询稍微复杂一些,您必须通过调用 hll_cardinality 函数读出不同数量的 IP 地址:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec,
hll_cardinality(distinct_ip_addresses) AS distinct_ip_address_count
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - interval '5 minutes';
HLL 不仅速度更快,还可以让你做以前做不到的事情。 假设我们进行了汇总,但我们没有使用 HLL,而是保存了确切的唯一计数。 这很好用,但您无法回答诸如在过去的一周内,我们丢弃了原始数据有多少不同的会话?之类的问题。
使用 HLL,这很容易。您可以使用以下查询计算一段时间内的不同 IP 计数:
SELECT hll_cardinality(hll_union_agg(distinct_ip_addresses))
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
您可以在项目的 GitHub 存储库中找到有关 HLL 的更多信息。
- postgresql-hll
- https://github.com/aggregateknowledge/postgresql-hll
使用 JSONB 的非结构化数据
Citus 与 Postgres 对非结构化数据类型的内置支持配合得很好。 为了证明这一点,让我们跟踪来自每个国家/地区的访客数量。 使用半结构数据类型可以让您不必为每个国家添加一列,并最终得到具有数百个稀疏填充列的行。我们有一篇博文解释了半结构化数据使用哪种格式。这篇文章推荐使用 JSONB,在这里我们将演示如何将 JSONB 列合并到您的数据模型中。
首先,将新列添加到我们的汇总表中:
ALTER TABLE http_request_1min ADD COLUMN country_counters JSONB;
接下来,通过修改汇总函数将其包含在汇总中:
@@ -1,14 +1,19 @@
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
+ , country_counters
) SELECT
site_id,
minute,
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
- FROM http_request
+ , jsonb_object_agg(request_country, country_count) AS country_counters
+ FROM (
+ SELECT *,
+ count(1) OVER (
+ PARTITION BY site_id, date_trunc('minute', ingest_time), request_country
+ ) AS country_count
+ FROM http_request
+ ) h
现在,如果您想在仪表板中获取来自美国的请求数量,您可以将仪表板查询修改为如下所示:
SELECT
request_count, success_count, error_count, average_response_time_msec,
COALESCE(country_counters->>'USA', '0')::int AS american_visitors
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号