
gin的生命周期——源码学习
先来了解下其目录结构:
. ├── binding 依据 HTTP 请求 Accept 解析响应数据格式 │ ├── binding.go │ ├── ...... ├── ginS ├── internal ├── render 依据解析的 HTTP 请求 Accept 响应格式生成响应 │ ├── data.go │ ├── html.go │ ├── json.go │ ├── ...... ├── auth.go ├── *context.go ├── *gin.go ├── logger.go ├── mode.go 设置 Gin 运行环境模式 ├── path.go Path 处理 ├── recovery.go 处理 Panic 的 Recovery 中间件 ├── *routergroup.go 路由组设置 ├── tree.go 路由算法 ├── utils.go helper 函数 └── ......
其中比较重要的模块为: context.go,gin.go,routergroup.go,以及 tree.go;分别处理 HTTP 请求及响应上下文,gin 引擎初始化,路由注册及路由查找算法实现。
Gin的生命周期
以官网demo来了解 gin 的生命周期
package main import "github.com/gin-gonic/gin" func main() { // 创建 Gin Engine 实例 r := gin.Default() // 设置请求 URI /ping 的路由及响应处理函数 r.GET("/ping", func(c *gin.Context) { c.JSON(200, gin.H{ "message": "pong", }) }) // 启动 Web 服务,监听端口,等待 HTTP 请求到并生成响应 r.Run() // 监听并在 0.0.0.0:8080 上启动服务 }
以问题驱动学习,以下面问题为目标,阅读源码
gin 是如何监听请求?如何接收并响应请求?对于一个路径,如何做到只响应一个方法?如何处理中间件?如何对路由进行分组?如何绑定路由?如何请求绑定?
所需要了解的内容为:
-
gin.Engine的作用及数据结构 -
gin.context的作用及数据结构 -
RouterGroup的作用及数据结构 -
压缩前缀树的作用及数据结构
gin.Default()
使用 gin 开发都是以gin.Default()开始,该函数返回一个*gin.Engine对象,该对象贯穿了整个生命周期,是核心数据结构

func New() *Engine { debugPrintWARNINGNew() engine := &Engine{ // 初始化根路由组 RouterGroup: RouterGroup{ Handlers: nil, basePath: "/", root: true, }, // 部分开关标志, FuncMap: template.FuncMap{}, RedirectTrailingSlash: true, RedirectFixedPath: false, // 字典树,路由 trees: make(methodTrees, 0, 9), ...... } engine.RouterGroup.engine = engine // 新建context池,避免context频繁销毁和重建,基于sync.pool实现 engine.pool.New = func() interface{} { return engine.allocateContext() } return engine }
中间件注册
gin.Default()部分,还利用了engine.Use进行了全局中间件注册,这是默认注册的中间件, ginLogger() 和 Recovery() 用于日志记录和错误恢复。
具体过程是通过gin.Engine进行的,利用引擎的默认路由组的Use方法进行
func (engine *Engine) Use(middleware ...HandlerFunc) IRoutes { // 路由组方法注册 engine.RouterGroup.Use(middleware...) engine.rebuild404Handlers() engine.rebuild405Handlers() return engine }
func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes { // handlers存放一系列中间件以及最后的控制器函数 group.Handlers = append(group.Handlers, middleware...) return group.returnObj() }
RouterGroup
路由组用于处理路由,对路由进行分组,如两个路由
r.GET("/admin/set", func(c *gin.Context)
r.GET("/admin/get", func(c *gin.Context)
通过路由组,可以减少代码冗余度,增加可读性;同时,路由组下的所有路由都会走该路由组的基础中间件
adminRouters := r.Group("/admin") adminRouters.GET("/admin/set", func(c *gin.Context) adminRouters.GET("/admin/get", func(c *gin.Context)
type HandlersChain []HandlerFunc type RouterGroup struct { Handlers HandlersChain // 存放中间件的handler链 basePath string // 基础路径 engine *Engine // 路由组的所属引擎 root bool // 是否是根路由组 }
另外,通过gin.Default()可以发现,默认引擎下有一个路由组,而路由组下又包含这个引擎,也就是说Engine和RouterGroup之间形成了一个双向引用的关系,这样设计有什么好处呢?
通过将
*Engine实例嵌入到gin.RouterGroup
路由分组
既然有了路由组,那么使用RouterGroup的Group方法将一些重复化的路由进行分组,对于初始根路由,可以使用默认引擎的路由组进行分组
func AdminRoutersInit(r *gin.Engine) { adminRouters := r.Group("/admin") // adminRouters也可以再次分组 }
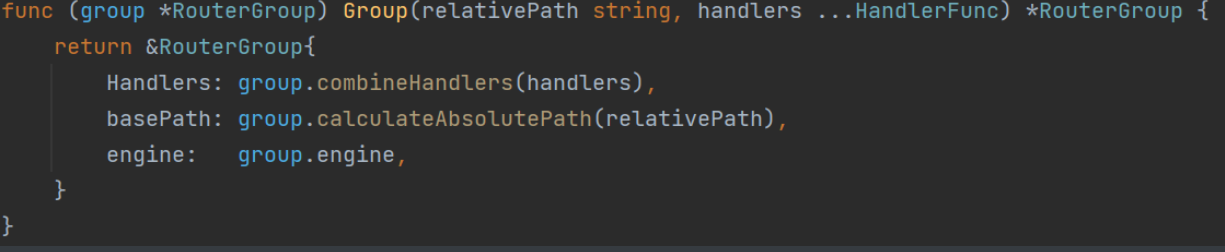
路由注册
根据 demo 继续往下执行,就到了路由注册部分,当使用不同的 http 方法注册路由后,会调用group.handle方法,将路由与方法进行绑定

进入group.handle方法,该方法主要做了以下几件事:
-
拼接完整的路径
-
组合 handler 链,注意这里控制器函数也被组合起来了
-
将该路径的方法以及中间件添加到路由树(核心)

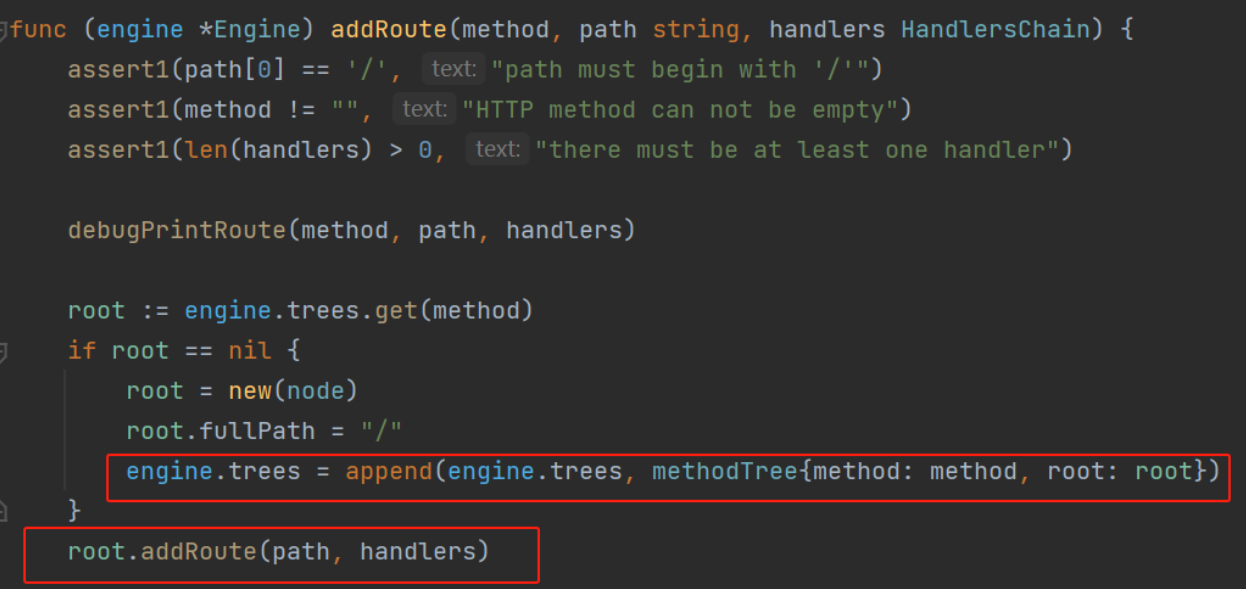
gin 针对每个 http 请求方法,都构造了一棵路由树。这里就根据注册路由的请求方法获取对应的路由树,再将路由的完整路径和对应的处理函数链注册到路由树中,后续才能根据请求路径调用对应的处理函数链进行处理。 具体路由树的数据结构以及如何添加路由后面再说
至此,路由就注册好,实际上就是将路径及中间件添加到对应方法的路由树上,由此也可以推测,当收到某个请求后,先找到对应方法的路由树,再从路由树上找到路径和中间件,依次执行
接收请求并相应
engine的Run方法底层实际上调用的 http/net 包的ListenAndServe方法,
func (engine *Engine) Run(addr ...string) (err error) { defer func() { debugPrintError(err) }() if engine.isUnsafeTrustedProxies() { debugPrint("[WARNING] You trusted all proxies, this is NOT safe. We recommend you to set a value.\n" + "Please check https://pkg.go.dev/github.com/gin-gonic/gin#readme-don-t-trust-all-proxies for details.") } address := resolveAddress(addr) debugPrint("Listening and serving HTTP on %s\n", address) // Engine 实现了该接口 err = http.ListenAndServe(address, engine.Handler()) return }
该方法使用net.Listen("tcp", addr)方法指定监听端口,srv.Serve(ln)启动服务,监听对应端口,当出现请求时创建一个新的 goroutine 处理并响应,具体看 net/http 的源码,位置
net/http/server.go #L2973
我们知道,ListenAndServe的第二个参数是一个接口类型,该接口实现了ServeHTTP方法,当有请求时就会调用该接口实现的ServeHTTP方法
func ListenAndServe(addr string, handler Handler) error { server := &Server{Addr: addr, Handler: handler} return server.ListenAndServe() } // Handler为一个接口,实现ServeHTTP方法 type Handler interface { ServeHTTP(ResponseWriter, *Request) }
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) { // 从context对象池取一个可用的context对象 c := engine.pool.Get().(*Context) // 将http请求和响应写入context,方便后面从上下文获取数据 c.writermem.reset(w) c.Request = req c.reset() // 处理http请求 engine.handleHTTPRequest(c) // 使用完后放回对象池,下次复用 engine.pool.Put(c) }
func (engine *Engine) handleHTTPRequest(c *Context) { httpMethod := c.Request.Method rPath := c.Request.URL.Path ... // Find root of the tree for the given HTTP method t := engine.trees for i, tl := 0, len(t); i < tl; i++ { // 根据http请求方法获取对应的路由树 if t[i].method != httpMethod { continue } root := t[i].root // Find route in tree // 根据请求路径获取路由树节点信息,包括handler链和路径 value := root.getValue(rPath, c.params, c.skippedNodes, unescape) if value.params != nil { c.Params = *value.params } if value.handlers != nil { // 将handler链注入到context中 c.handlers = value.handlers // 将完整路径注入到context中 c.fullPath = value.fullPath // c.Next()依次执行中间件,以及控制器 c.Next() // 结果写入context c.writermem.WriteHeaderNow() return } ... break } ... }
简单总结过程如下:
-
根据当前客户端的请求方法,获取到对应的路由树。
-
根据请求的路径在路由树中进行路径匹配,能够获取到路径参数和该路由的完整处理器链(包括预先设置的 middleware 处理函数),并保存到 context对象中。
-
调用
c.Next(),开始按顺序调用处理器链中的每一个中间件,对请求进行处理。 -
最后一个处理函数为控制器,一般情况下,会在业务处理函数中调用 context 暴露的方法将响应写入到 http 输出流中。但是如果没调用,这里会帮忙做这件事(
WriteHeaderNow),给客户端一个响应。
// 将响应写入到了http输出流中 func(c *gin.Context) { c.JSON(200, gin.H{ "message": "pong", }) }
至此,就完成了接收请求到响应的完整过程。
问题回答
到这里,可以解决之前提出的部分问题了
gin 是如何监听请求,接收并响应请求?
底层利用 http/net 包的
ListenAndServe方法监听,当请求到来时就创建一个新的goroutine 处理,首先从对象池中取一个gin.context,把请求和结果都写入该context,找到该方法的路由树,在路由树中查找路径,找到要执行的中间件链,依次执行中间件及控制器,最后将响应写入到http输出流中
标准库本身的路由是不区分请求方法的,也就是说注册一个路由后,GET、POST都能匹配到该路由,在 gin 中,如何做到只响应一个方法?
通过路由树,一个http请求方法有一颗路由树,如果该请求在路由树中没找到对应路径,就无法响应,返回
StatusMethodNotAllowed
如何处理中间件?
从根路由组开始,到该路径所在的路由组上,所有的中间件都通过
slice存放,注册路由时,会将该路由执行的中间件(包括控制器)一起写入到路由树上,收到请求后c.next()依次执行
如何对路由进行分组?
RouterGroup数据结构,该数据结构包括路径和中间件链,调用Group方法后,返回一个新的RouterGroup,基础路径和中间件链都在原来的路由组上新增

 浙公网安备 33010602011771号
浙公网安备 33010602011771号