Hash算法
Hash算法是什么
哈希(hash)也翻译作散列。Hash算法,是将一个不定长的输入,通过散列函数变换成一个定长的输出,即散列值,这个值就是Hash值。
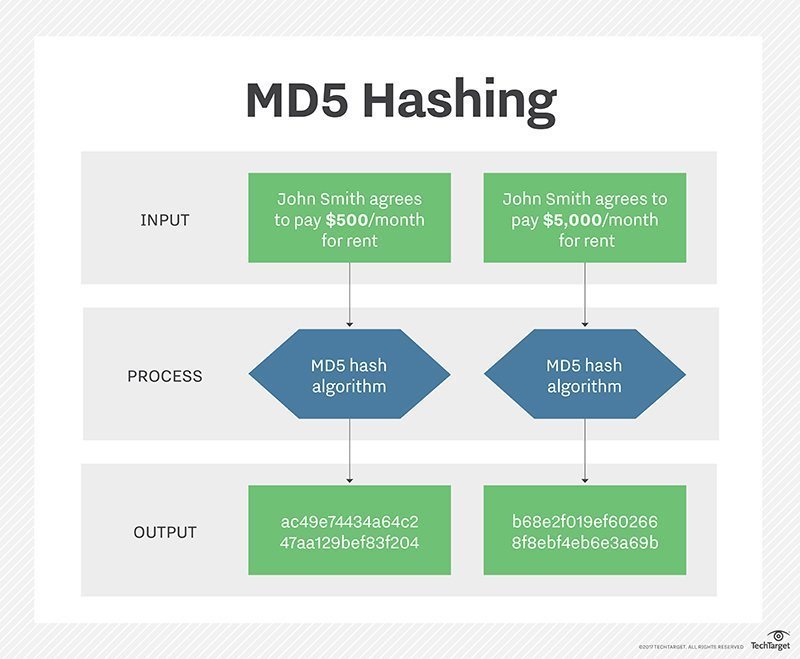
Hash算法只是一个定义,并没有规定具体的实现,常见的hash算法有:SM3、MD5、SHA-1等 。
这种散列变换是一种单向运算,具有不可逆性即不能根据散列值还原出输入信息,因此严格意义上讲Hash算法是一种消息摘要算法,不是一种加密算法。Hash值的空间远小于输入的空间(因此可能发生hash碰撞)。
在Java语言里,每个Object对象都有一个hashCode方法,它默认是根据对象的内存地址计算的Hash值。当然我们可以覆盖这个方法,用自己的方法去计算得出一个Hash值。
Hash算法用途
Hash主要应用在数据检索和数字签名领域。在不同的应用场景下,hash函数的选取也有所侧重,比如在数据检索时,主要考虑的是运算的快速性,并且要保证hash均匀分布。在数字签名领域优先考虑抗碰撞性,避免出现两段不同的明文hash值相同的情况发生。
数据检索
数据检索 Data retrieval
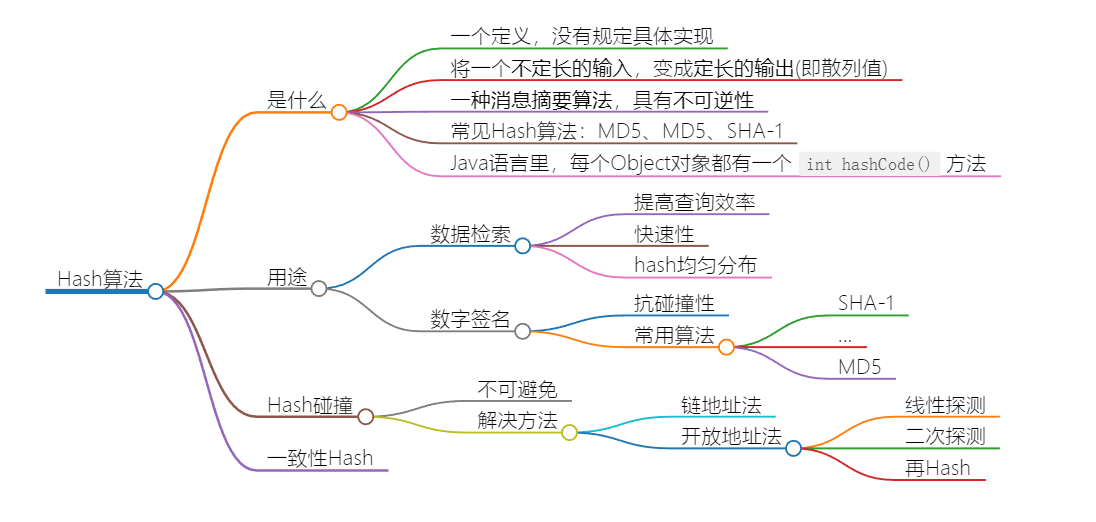
使用Hash算法的数据结构叫做哈希表,也叫散列表,主要是为了提高查询的效率。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数就是hash函数,存放记录的数组叫做哈希表。在数据检索时,有时需要较高的运算速度而弱化考虑抗碰撞性,可以使用自己构建的哈希函数。
如下示例,在hash表中,采用键值对(key value)的形式保存客户的记录,key用来定位数据,使用hash函数计算key的hash值,快速定位记录的位置。
数字签名
数字签名 Digital signatures
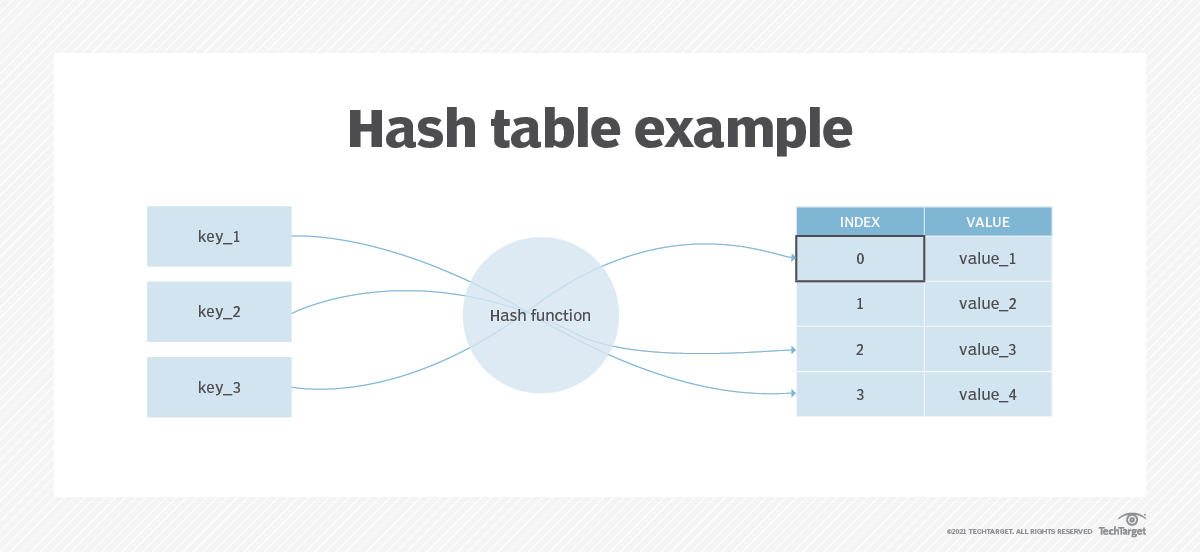
在密码学中,Hash算法的作用主要是用于消息摘要和签名,换句话说,它主要用于对整个消息的完整性进行校验。比如一些登陆网站并不会直接明文存储用户密码,存储的是经过hash处理的密码的摘要(hash值),当用户登录时只需要对比输入明文的摘要与数据库存储的摘要是否相同;即使黑客入侵或者维护人员访问数据库也无法获取用户的密码明文,大大提高了安全性。
密码学通常使用多个散列函数来保护数据。 一些最流行的加密哈希包括以下内容:
- Secure Hash Algorithm 1 (SHA-1)
- Secure Hash Algorithm 2 (SHA-2)
- Secure Hash Algorithm 3 (SHA-3)
- MD2
- MD4
- MD5
MD2、MD4 和 MD5 这样的散列函数可以用来实现散列数字签名。散列后,签名将转换为更短的值,称为消息摘要。
安全散列算法 (SHA) 是用于创建更大(160 位)消息摘要的标准算法。 虽然它类似于消息摘要散列函数 MD4 并且擅长数据库存储和检索,但这并不是用于加密或错误检查目的的最佳方法。 SHA-2 用于创建更大的(224 位)消息摘要。 SHA-3 是 SHA-2 的继任者。
Hash碰撞
什么是Hash碰撞
网络安全中使用的是单向散列算法,这是阻攻击者通过逆向方法获得其原始状态的关键步骤。但是还是会存在两个不同的key可以生成相同hash的情况,这种现象称为hash碰撞。
hash函数接受任意的输入,然后产生一个独一无二的固定长度的值作为输出。现实中,输入可以有无限种可能,但 hash table 的长度是有限的,所以难免不同的输入产生相同的输出,这就产生了 hash 碰撞。
Hash碰撞产生的概率
无论 hash table 有多大,hash 冲突都很容易出现。典型的例子是生日悖论,23 个人中两个人生日相同的概率高达50%。
一个好的散列函数永远不会从两个不同的输入中产生相同的散列值,具有极低碰撞风险的散列函数被认为是可以接受的。
如何解决Hash碰撞
开放地址(Open addressing) 和 链地址法/拉链法(separate chaining)是在发生Hash冲突时解决冲突的两种方法。
开放地址
开发地址法会将所有值都存储在 hash table 中,这样就要求 hash table 的长度必须大于等于值的数量。
- 当执行 insert 操作时,以 hash 函数得到的输出作为开始位置,持续向后查找,直到找到空的 slot。
- 当执行 select 操作时,以 hash 函数得到的输 出作为开始位置,持续向后查找,直到找到与输入值相等的项或空 slot。
- 当执行 delete 操作时,以 hash 函数得到的输出作为开始位置,持续向后查找,直到找到与输入值相等的项,将该 slot 标记为 deleted。之后,insert 操作会在该位置插入新值,但 search 操作在遇到这种 slot 后会继续向后查找。
具体来说分为如下三类(这三种方法都是为了解决hash碰撞出现时,如何存储数据的方法):
- 线性探测
- 二次探测
- 双重哈希
线性探测
以 hash 函数的输出作为起始位置,依次向后查找,直到找到一个空的 slot,然后将值插入。
以下为伪代码,其中 x 为输入值,hash(x) 即为查找开始位置,S 为 hash table 的 size。
If slot hash(x) % S is full, then try (hash(x) + 1) % S
If (hash(x) + 1) % S is also full, then try (hash(x) + 2) % S
If (hash(x) + 2) % S is also full, then try (hash(x) + 3) % S
以序列 50, 700, 76, 85, 92, 73, 101 为例,以下为示意图:
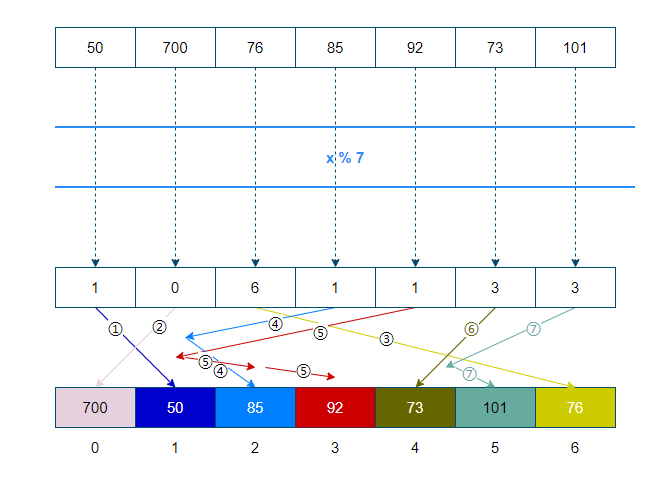
线性探查法由于在发生碰撞时值会连续存储,所以有很高的缓存性能;但正是由于值的连续存储,造成集群现象,导致查找和插入比较耗时。
二次探测
以 hash 函数的输出作为起始位置,以偏移量的二次方向后查找,直到找到一个空的 slot,然后将值插入。
仍以 x 为输入值,hash(x) 作为查找起始位置,S 为 hash table 的长度。以下为伪代码:
If slot hash(x) % S is full, then try (hash(x) + 1*1) % S
If (hash(x) + 1*1) % S is also full, then try (hash(x) + 2*2) % S
If (hash(x) + 2*2) % S is also full, then try (hash(x) + 3*3) % S
二次探查法在发生碰撞时,值的连续性不如线性探查法,所以缓存性能也不如线性探查法,但也不会像线性探查法那样出现集群现象,所以查找和插入不会像线性探查法那样耗时。
再 hash 法
以 hash 函数的输出作为起始位置,如果该位置对应的 slot 不为空,则对输入再次进行 hash。
仍以 x 为输入值,hash(x) 作为查找起始位置,S 为 hash table 的长度。hash2 为再 hash 函数,以下为伪代码:
If slot hash(x) % S is full, then try (hash(x) + 1*hash2(x)) % S
If (hash(x) + 1*hash2(x)) % S is also full, then try (hash(x) + 2*hash2(x)) % S
If (hash(x) + 2*hash2(x)) % S is also full, then try (hash(x) + 3*hash2(x)) % S
再 hash 法的值存储的连续行最差,所以缓存性能也最差。同时,由于需要进行两次 hash,增加了计算量。但再 hash 不会出现集群现象。
链地址法
所谓链地址法,即实际发生碰撞的值存储在一个链表中,值的插入、查找、删除都在链表中进行,而 hash table 的每个 slot 中只记录指向该链表的头指针。
如下示例:要将hash值 50, 700, 76, 85, 92, 73, 101 存入 hash table,hash table 长度为 7,hash 函数为 key % 7。
50 % 7 = 1
700 % 7 = 0
76 % 7 = 6
85 % 7 = 1
92 % 7 = 1
73 % 7 = 3
101 % 7 = 3
在操作过程中,50、85、92 会产生碰撞;73、101 会产生碰撞。最后产生的 hash table 示意
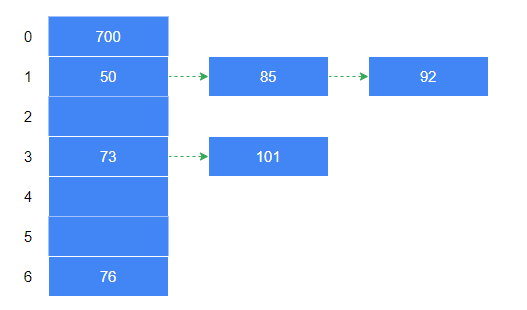
链地址法 VS 开放地址
| 拉链法 | 开放定址法 |
|---|---|
| 实现简单 | 计算量大 |
| 不需要担心 hash table 被填满 | hash table 可能会被填满 |
| 对 hash 函数和装填因子不敏感 | 需要额外关注装填因子,同时避免出现集群 |
| 在对 key 的数量和频次不确定时使用 | 在对 key 的数量和频次确定时使用 |
| 缓存性能差 | 缓存性能比较好 |
| 链表需要额外占用空间 | 不需要额外占用空间 |
一致性Hash
为什么
如下图所示:在一个图片服务集群中,用户访问图片资源时,负载均衡设备基于图片name的hash值,将访问转发到对象存储服务器bucket0、bucket1、bucket2上。(这里隐含一个概念:云端存储是有状态的,每个存储桶中的内容不一致,如果云端服务是无状态的,则无需考虑这些事情)。
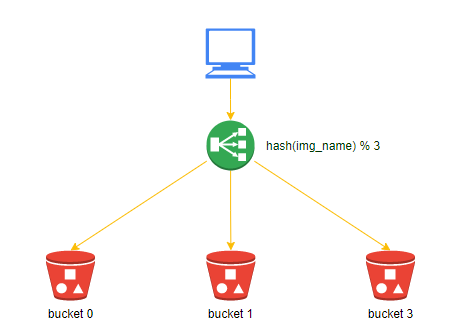
上图中描述的方案解决了如何确定存储/检索服务器的问题。但是存在一个很严重的问题,随着图片数据量的不断增大,肯定会需要增加新的服务器节点,或者某台服务器如果发生故障或损坏,还会面临删除服务器节点的情况,这会导致服务器总数被改变。
如下示例:当存储桶bucket0损坏后,我们的图片定位算法会变为:hash(img_name) % 2,图片的Hash值未发生变化,但是除数发生了变化,则余数必然会变化,余数变化会导致图片请求落到错误的存储桶上,我们无法正确取到所需的图片。
即在分布式集群环境中,当新增或者减少一台服务器后,由于路由算法发生改变,导致大量的路由策略失败,服务不可用。
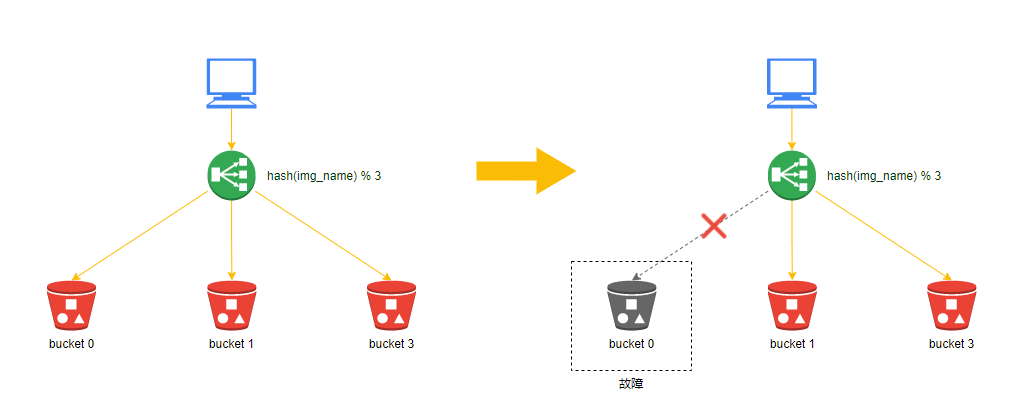
是什么
一致性hash可以解决这种因为横向伸缩导致的大规模数据变动问题。
一致性哈希算法通过一个叫作一致性哈希环的数据结构实现。这个环的起点是0,终点是$2{32}-1$,并且起点和终点相连接,故这个环的整数分布范围是$[0,2-1]$。我们将服务器节点和资源Key的hash值放置在Hash环上,如下图:
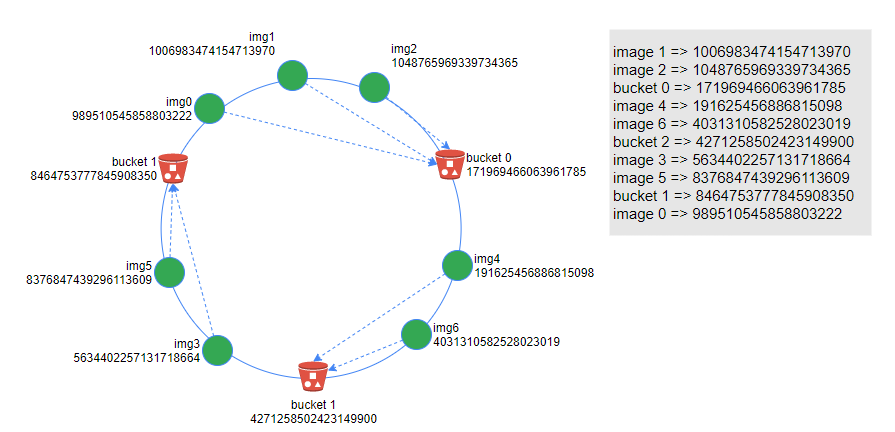
服务器节点分别为:bucket 0、bucket 1、bucket 2,img0 ~ 7 分别代表图片0~7。将服务器节点和资源节点放在同一个Hash环上之后,在hash环上顺时针查找离这个img的Hash值最近的机器(图片资源会存储在这台服务器上)。右侧是采用一个自定义HashCode方法计算出来的,服务器资源和图片资源的Hash值。
源码分析
Java
Object
Java Object 对象中就存在 hashCode 方法,如下:
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* The general contract of {@code hashCode} is:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@code equals(Object)}
* method, then calling the {@code hashCode} method on each of
* the two objects must produce the same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link java.lang.Object#equals(java.lang.Object)}
* method, then calling the {@code hashCode} method on each of the
* two objects must produce distinct integer results. However, the
* programmer should be aware that producing distinct integer results
* for unequal objects may improve the performance of hash tables.
* </ul>
* <p>
* As much as is reasonably practical, the hashCode method defined by
* class {@code Object} does return distinct integers for distinct
* objects. (This is typically implemented by converting the internal
* address of the object into an integer, but this implementation
* technique is not required by the
* Java™ programming language.)
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
public native int hashCode();
String
具体 String 对象的实现如下:
/**
* Returns a hash code for this string. The hash code for a
* {@code String} object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using {@code int} arithmetic, where {@code s[i]} is the
* <i>i</i>th character of the string, {@code n} is the length of
* the string, and {@code ^} indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
其中比较核心的代码如下:
// 其中val[i] 是一个char类型数据
int h = 31 * h + val[i];
为什么hashCode乘积系数为31
- 更少的乘积结果冲突,31是个不大不小的质数, 能保证乘积有足够的离散率, 并且保证最后的hashCode不至于过大超出int范围
- 计算可被JVM优化 32 * i 可以使用位运算, 进行高效计算, 可以写成 i << 5 31 * i 可以被优化成 (i << 5) - i, 从而进行高效运算
附:Java 中int型和char型相加说明:
基本数据类型之间的运算规则:
byte、char、short -> int -> long -> float -> double
注意:byte、char、short这三种数据类型做运算时,结果为int型。
char c2 = 'a' + 1;
int num2 = 'a' + 1;
System.out.println("c2: " + c2);
System.out.println("num2: " + num2);
System.out.println("(char) num2: " + (char) num2);
char和int之间相加,char型会转换为int类型,最后结果为107.
char和char之间相加,最后结果也是int类型,最后结果为195.
自定义对象
一个自定义对象的HashCode方法如下:
class User {
private String userName;
private Integer age;
public User(String userName, Integer age) {
this.userName = userName;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return Objects.equals(userName, user.userName) && Objects.equals(age, user.age);
}
@Override
public int hashCode() {
return Objects.hash(userName, age);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号