OO第三次博客作业
OO第三单元总结
一、JML语言基础
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言(Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义手段。所谓接口即一个方法或类型外部可见的内容。近年来,JML持续受到关注,为严格的程序设计提供了一套行之有效的方法。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具以静态方式来检查代码实现对规格的满足情况。
一般而言JML有2种主要用法:
(1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
(2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
1、JML表达式
1)原子表达式
\result表达式:表示一个非void 类型的方法执行所获得的结果,即方法执行后的返回值。
\old( expr )表达式:用来表示一个表达式expr 在相应方法执行前的取值。
\not_assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。
\not_modified(x,y,...)表达式:与上面的\not_assigned表达式类似,该表达式限制括号中的变量在方法执行期间的取值未发生变化。
\type(type)表达式:返回类型type对应的类型(Class),如type( boolean )为Boolean.TYPE。
\typeof(expr)表达式:该表达式返回expr对应的准确类型。
2)量化表达式
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\product表达式:返回给定范围内的表达式的连乘结果。
\max表达式:返回给定范围内的表达式的最大值。
\min表达式:返回给定范围内的表达式的最小值。
\num_of表达式:返回指定变量中满足相应条件的取值个数。
3)集合表达式
集合构造表达式:可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。例子:new JMLObjectSet {Integer i | s.contains(i) && 0 < i.intValue() } 表示构造一个JMLObjectSet对象,其中包含的元素类型为Integer,该集合中的所有元素都在容器集合s中出现。
4)操作符
(1) 子类型关系操作符: E1<:E2 ,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。
(2) 等价关系操作符: b_expr1<==>b_expr2 或者b_expr1<=!=>b_expr2 ,其中b_expr1和b_expr2都是布尔表达式,这两个表达式的意思是b_expr1==b_expr2 或者b_expr1!=b_expr2 。
(3) 推理操作符: b_expr1==>b_expr2 或者b_expr2<==b_expr1 。
(4) 变量引用操作符:除了可以直接引用Java代码或者JML规格中定义的变量外,JML还提供了几个概括性的关键词来引用相关的变量。
2、JML方法规格
前置条件(pre-condition): 前置条件通过requires子句来表示: requires P; 。其中requires是JML关键词,表达的意思是“要求调用者确保P为真”.
后置条件(post-condition): 后置条件通过ensures子句来表示: ensures P; 。其中ensures是JML关键词,表达的意思是“方法实现者确保方法执行返回结果一定满足谓词P的要求,即确保P为真”.
副作用范围限定(side-effects): 副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响。从方法规格的角度,必须要明确给出副作用范围。JML提供了副作用约束子句,使用关键词assignable 或者modifiable 。
signals子句: signals子句的结构为signals (***Exception e) b_expr ,意思是当b_expr 为true 时,方法会抛出括号中给出的相应异常e。
3、类型规格
不变式invariant: 不变式(invariant)是要求在所有可见状态下都必须满足的特性,语法上定义invariant P ,其中invariant 为关键词, P 为谓词。
状态变化约束constraint: 对象的状态在变化时往往也许满足一些约束,这种约束本质上也是一种不变式。JML为了简化使用规则,规定invariant只针对可见状态(即当下可见状态)的取值进行约束,而是用constraint来对前序可见状态和当前可见状态的关系进行约束。
二、JML工具链
jml-launcher(图形用户界面工具的启动器)。
jml和jml-gui(检查器)。
jmlc和jmlc-gui(编译用于运行时断言检查)。
jmldoc和jmldoc-gui(包含JML规范信息的javadoc版本)。
jmle(编译用于执行或原型规范)。
jmlrac(java的一个版本,VM,包含CLASSPATH中的bin / jmlruntime.jar文件,用于运行使用jmlc编译的文件)。
jmlre(java的一个版本,VM,包括执行规范所需的运行时支持,用于运行使用jmle编译的文件)。
jmlspec和jmlspec-gui(从Java源文件生成框架规范文件)。
jmlunit和jmlunit-gui(生成用于JUnit的单元测试代码存根)。
jtest(结合了jmlc和jmlunit的工作)
jml-junit(JUnit的swing用户界面的一个版本,包括CLASSPATH中的bin / jmlruntime.jar和bin / jmljunitruntime.jar文件,用于对使用jmlc编译的文件和jmlunit生成的测试用例运行基于JML和JUnit的测试)。
三、部署JML UnintNG
检查方法如下图所示:
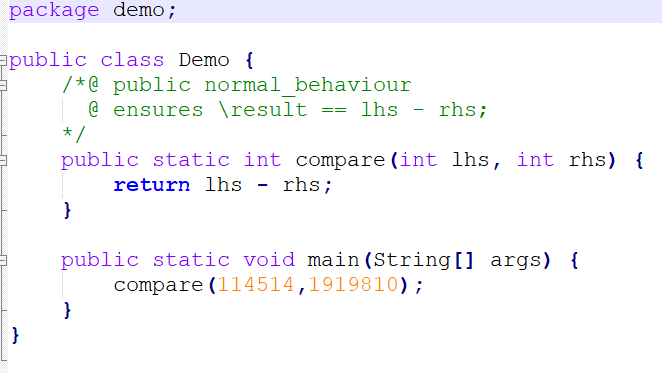
编译后文件目录:

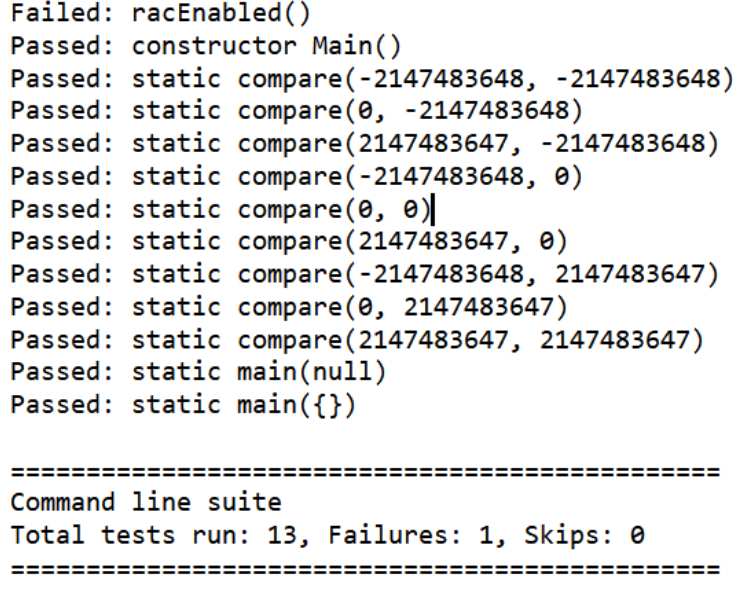
最终生成测试结果:
四、作业架构设计
第一次作业
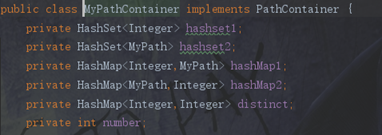
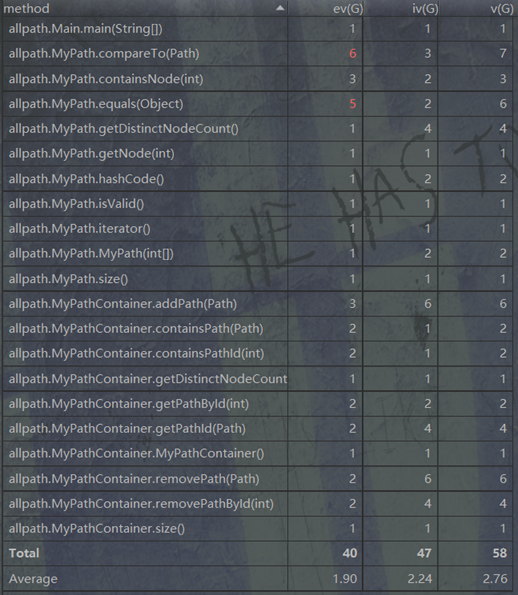
第一次作业总体上来说结构比较简单。主要说说PathContainer的数据容器选择。为了最大限度地降低时间复杂度,我的PathContainer使用了2个HASHSET和3个HASHMAP。其中hashset主要负责判断特定的ID和PATH是否存在于PATHCONTAINER。前2个HASHMAP负责实现PATH到ID的查询以及ID到PATH的查询。最后一个HASHMAP负责储存DISTINCTCOUNT更新。在每一次增加和删除时更新所有的HASH数据结构。如下图所示:
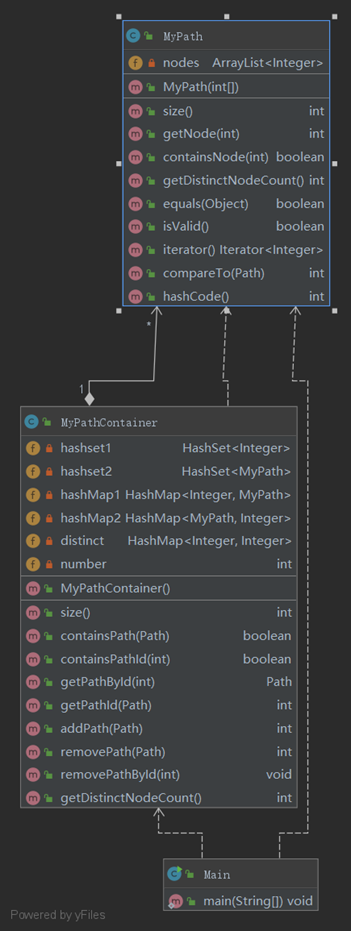
类图如下所示:
经典度量结果:
第一次BUG修复
由于第一次作业总结上结构比较简单,同时HASHMAP的运用使得复杂度不会超标。因此在中强互测阶段都未发现BUG。
第二次作业
第二次作业在第一次作业的基础上增加了边的概念。同时增加了2个函数,判断2点是否连通以及最短距离。我在第一次作业的数据结构上增加了2个HASHMAP。如下图所示:
edgeset是关于边的HASHMAP,key String的构成方法是点的数字通过空格相连,而Integer记录它们中间相连的边数
connectset记录点和点的连接情况。左侧的Integer是点的名字,而右侧的HASHMAP表示和它相连的点以及相连的边数,采用两种结构大致相同的HASHMAP的确比较占用内存,但能够在我的架构中很大的减少编程复杂度。
由于本次作业的边都是无权边,因此在计算最短路径时采用BFS遍历方法。遍历到特定点的层数就是最短路径长度。相较于迪杰斯特拉斯算法复杂度明显降低,但是对第三次作业的扩展难度比较大,需要重构算法。
类图:
经典度量分析:
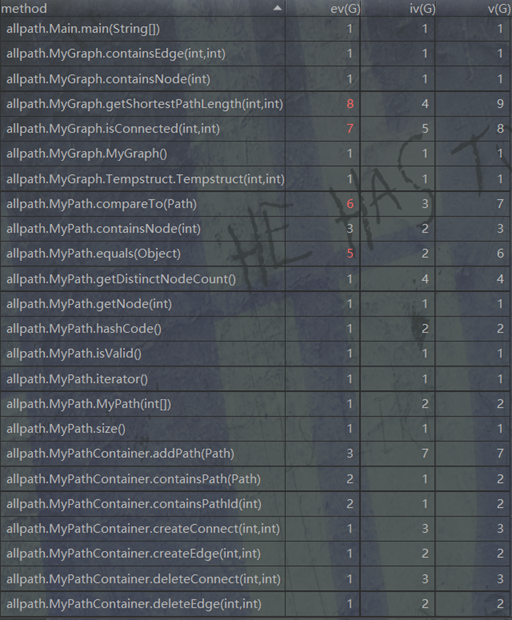
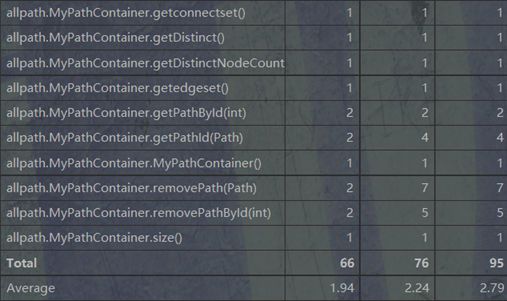
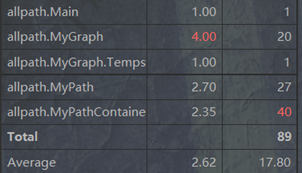
可以看到在计算最短路径以及判断连通这两个函数的复杂度明显过高,原因是对BFS以及异常处理这两个步骤没有进行进一步细化,想通过一个函数完全解决。完全可以通过将2者分离开来降低复杂度。
第二次BUG修复
第二次作业相较于第一次作业只增加了边的部分。由于采用HASHMAP和BFS,复杂度并不高,因此在中强测以及互测阶段都没有发现BUG。
第三次作业
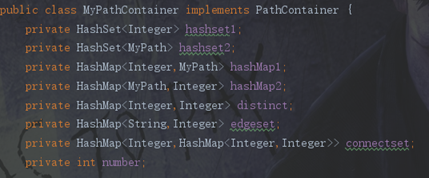
个人理解第三次作业相较于第二次作业一共只增加了2个部分。第一是CONNECTBLOCK的计算,第二是有权图的出现。UNPLEASANT VALUE,PRICE以及TRANSFER都可以通过不同的有权图进行表示,在我的结构中通过3个HASHMAP进行了存储。对于CONNECTBLOCK,我通过一个HASHSET数组进行解决。以上的数据结构都会在PATH增加和删除时进行更新。
对于最少UNPLEASANT VALUE/PRICE/TRANSFER,由于图都有权重,因此不能使用BFS,只能通过迪杰斯特拉斯算法解决。同时由于在遍历的过程中会先找到其它节点的最短距离,因此可以通过特定数据结果将其缓存下来,在PATH数据更新时将所有缓存信息删除。
对于不同PATH的相同点,我采用将相同点拆成多个不同点,根据UNPLEASANT VALUE,PRICE,TRANSFER不同情况对边的权重赋予不同的值。
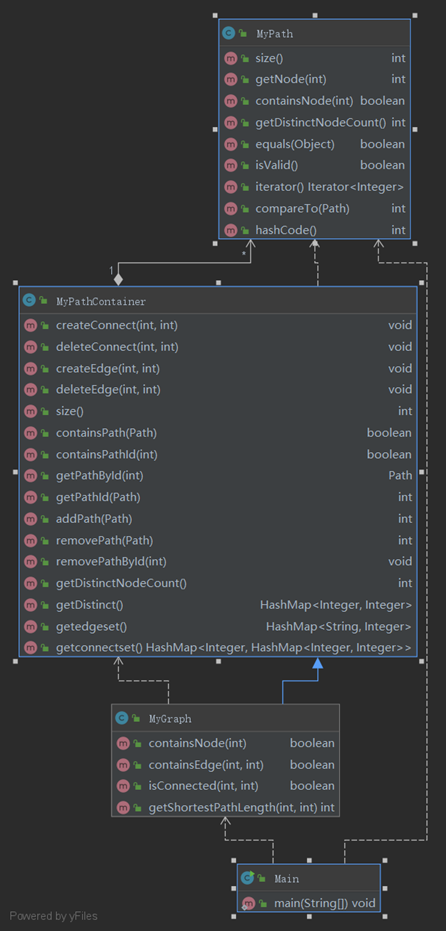
类图如下所示:
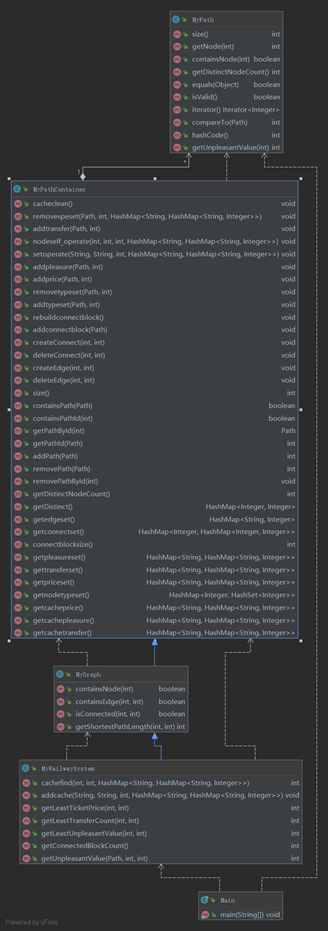
由于数据结构增多需要增加相应的调用以及修改函数,导致PATHCONTAINER显著增加。
在实现上采用继承的方法。GRAPH继承PATHCONTAINER,而RAILWAYSYSTEM继承GRAPH。
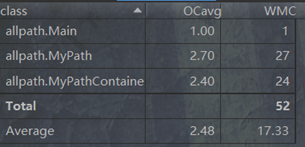
OO经典度量:
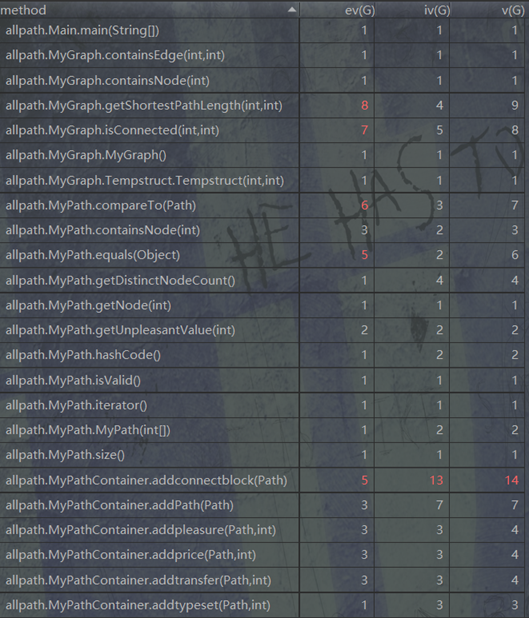

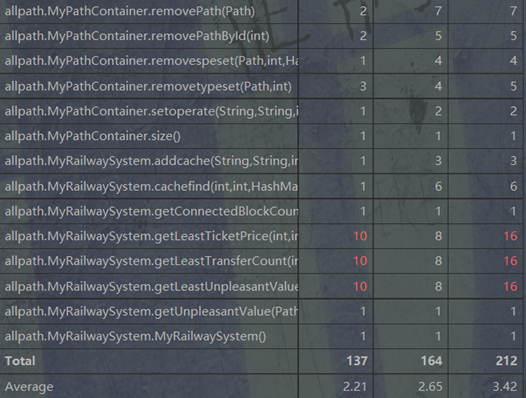
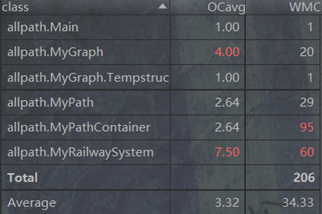
复杂度较高的函数主要分为2种。第一种是CONNECTBLOCK的更新函数,由于情况较多,并且需要对CONNECTBLOCK进行合并,因此复杂度较高。第二类是迪杰斯特拉斯算法,尽管已经将对缓存的更新和查询拆分成不同函数,但是由于算法本身原因,复杂度依然较高。
第三次作业BUG修复
第三次作业的BUG分为2部分,包括TIE BUG以及常规错误。
常规错误:通过强测共发现2个常规错误。第一是对ARRAYLIST.REMOVE的使用错误。如果使用该函数移除最后一个元素之前的元素,会将ARRAYLIST次序重新排列,而我忘记考虑这种情况,导致错误发生。
第二个常规错误是缓存的错误,由于将不同PATH的相同点拆成不同的点,因此到一个PATH点的最短距离未必是到这个点的最短距离,可能离其他PATH的同一个点距离更近。而我忘记了这种情况,导致错误。
TLE错误:目前还未发现解决原因。目前判断有2种可能情况:
1)没有对第二次作业的函数进行缓存
2)拆点方法不好,太过直接暴力。如果相同点在不同路径数较高,将导致整个图的边数非常高。
五、总结心得与体会
这3周的作业内容包括JML的理解和对于数据结构的重新测试。相较于具有二义性并且非常不够准确的自然语言,JML通过逻辑方法在很大程度上提高了编程的严谨性,保证了程序的合理性以及准确性。
但另一方面,JML由于其过度严格的要求,反过来也会产生一定的问题。首先就是可读性,对于一个非常复杂的程序,如果只通过JML规定规格,那么可读性会非常差,使程序员难以理解,实质上变相地降低了程序的准确性。第二,JML在一定程度上语言过度严谨。例如JML如果规定使用数组,那么如果使用ARRAYLIST,即使函数结构完全正确,OPENJML也会疯狂报错。第三,当我打开百度搜索JML,可以发现可供查考的资料非常少。实质上人们在大多数情况下通过简单的规格描述就能解决问题,而JML尽管非常严谨,但是在一般领域使用价值似乎并不高。
个人对JML的理解还比较初步。在我的理解下,JML主要运用于验证阶段的使用。通过严谨的逻辑验证能够在DEBUG阶段做到足够的严谨。同时可以做到对自然语言的补充。在编程时如果同时自然语言规格描述以及JML规格描述可以做到2者优势互补,最大限度提高编程效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号