
反混淆:恢复被OLLVM保护的程序
译者序:
OLLVM作为代码混淆的优秀开源项目,在国内主流app加固应用中也经常能看到它的身影,但是公开的分析研究资料寥寥。本文是Quarkslab团队技术博客中一篇关于反混淆的文章,对OLLVM项目中的控制流平坦化、虚假控制流、指令替换等混淆策略进行了针对性分析,并展示了利用符号执行对OLLVM混淆进行清理的一些思路和成果。
文章侧重于反混淆思路的讲解,并没有提供完整的代码方案,部分关键点也有所保留。文章末尾会提供编译好的测试程序(基于LLVM3.6.1),对OLLVM反混淆感兴趣的读者可以结合实例继续研究,后续有机会也会分享关于OLLVM还原的实例分析案例。外文技术文章翻译确实不易,初次尝试难免有误,欢迎留言指正。
【原文】: 《Deobfuscation: recovering an OLLVM-protected program》
我们最近研究了Obfuscator-LLVM项目,目的是测试其不同的保护策略。下面是我们关于如何处理代码混淆的结论与解决方案。
介绍
由于有时需要处理一些经过重度混淆的代码,我们打算研究Obfuscator-LLVM项目,检查其所生成混淆代码的优缺点。我们使用其可用的最新版本(基于LLVM3.5)。下面将展示如何使用Miasm逆向工程框架来突破所有的保护。
敬告:本文只是为了展示解决OLLVM混淆处理的一种方法。虽然包含许多代码示例,但本文不是Miasm教程,也没有提供相应的Python脚本打包下载。当然我们可以搞长篇大论,分析一个被OLLVM混淆保护的复杂程序,或者是一个Miasm不支持的CPU架构等等…然而并没有这些。我们将保持简单化,并展示我们如何清理混淆代码。
首先,我们会介绍分析过程中使用的所有工具,然后针对一个简单的示例程序,展示如何逐层(最后累加)打破OLLVM的保护方案。
免责声明:Quarkslab团队也在开发基于LLVM的混淆保护。所以我们对于设计混淆器和反混淆都有过一些研究。但这些成果尚未公开,并且也不准备公开。所以我们研究了OLLVM,因为我们了解其中会遇到的的困难。OLLVM是一个有意义的项目,在混淆的世界里所有一切都是关于(错位)的秘密。
混淆是什么?
代码混淆意味着代码保护。混淆修改后的代码更难以被理解。例如它通常被用于DRM(数字版权保护)软件中,通过隐藏算法和加密密钥等机密信息来保护多媒体内容。
当任何人都可以获取访问你的代码或二进制程序,但你不想让别人了解程序的工作原理的时候,你就需要代码混淆。但混淆的安全性基于代码模糊程度,破解它也只是时间问题。因此混淆工具的安全性取决于攻击者打破它所必须花费的时间。
使用的工具
测试例子
我们的测试目标是一个对输入值进行简单计算的单一函数。代码包含4个条件分支,这些分支取决于输入参数。测试程序在x86 32位架构下编译:
unsigned int target_function(unsigned int n)
{
unsigned int mod = n % 4;
unsigned int result = 0;
if (mod == 0) result = (n | 0xBAAAD0BF) * (2 ^ n);
else if (mod == 1) result = (n & 0xBAAAD0BF) * (3 + n);
else if (mod == 2) result = (n ^ 0xBAAAD0BF) * (4 | n);
else result = (n + 0xBAAAD0BF) * (5 & n);
return result;
}
下面是IDA的控制流程图展示:
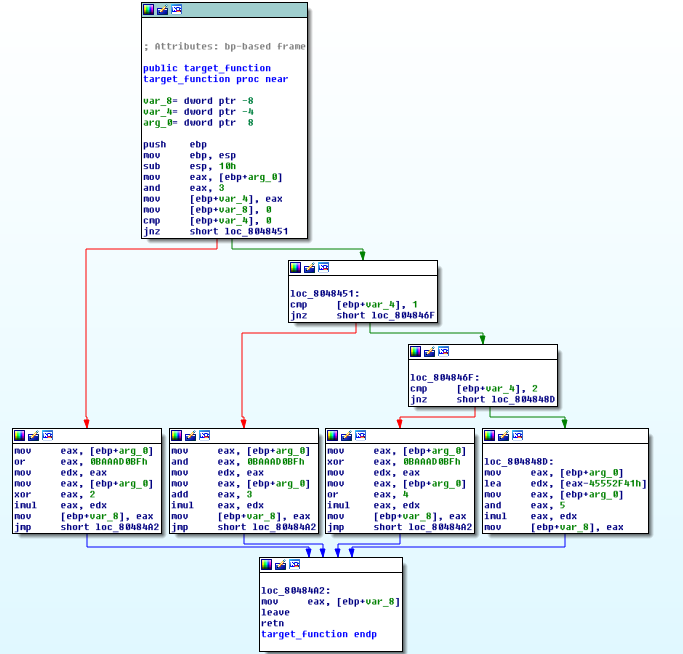
我们可以看到使用布尔比较和算术指令计算的3个条件和4个分支路径。我们这样做的目的是为了充分测试OLLVM所有的混淆策略。
这个函数虽然很简单,但它是研究反混淆最好的方式。因为我们的目标是为了研究OLLVM行为,而不是获得一个百分百通用的反混淆工具。
Miasm框架
Miasm是一个Python开源逆向工程框架。最新版本获取:https://github.com/cea-sec/miasm。正如我们前面所说的,虽然我们会展示一些代码示例,但是本文并不是Miasm教程。虽然其他工具可以同样用来做反混淆,但本文对于Miasm框架是一个很好的展示机会,Miasm框架更新比较活跃,可以用来做为强大的反混淆工具。
敬告!Miasm API可能在以后的提交更新中发生变化,所以请务必注意本文中提供的Miasm代码示例仅适用于本文发布时的最新版本(commit a5397cee9bacc81224f786f9a62adf3de5c99c87)。
图形展示
在我们开始分析混淆代码之前,关键的一点是决定我们想要的反混淆输出结果的展示形式。这并不简单,因为反混淆工作可能需要耗费一些时间,并且我们想有一个简单易懂的输出。
我们可以将基本块内容转换为LLVM中间表示(IR),这样可以重新编译混淆后的代码,并通过“优化传递”来清除无用代码然后生成新的程序,但是这个方案比较耗时,不过可以作为未来的改进目标。所以我们选择IDAPython构建流程图(使用GraphViewer类)作为我们的反混淆输出。这样,我们可以轻松地构建出节点和路径,然后使用Miasm的中间表示(IR)去填充代码基本块。
示例,下面的流程图是我们通过脚本对前面的测试程序生成的:
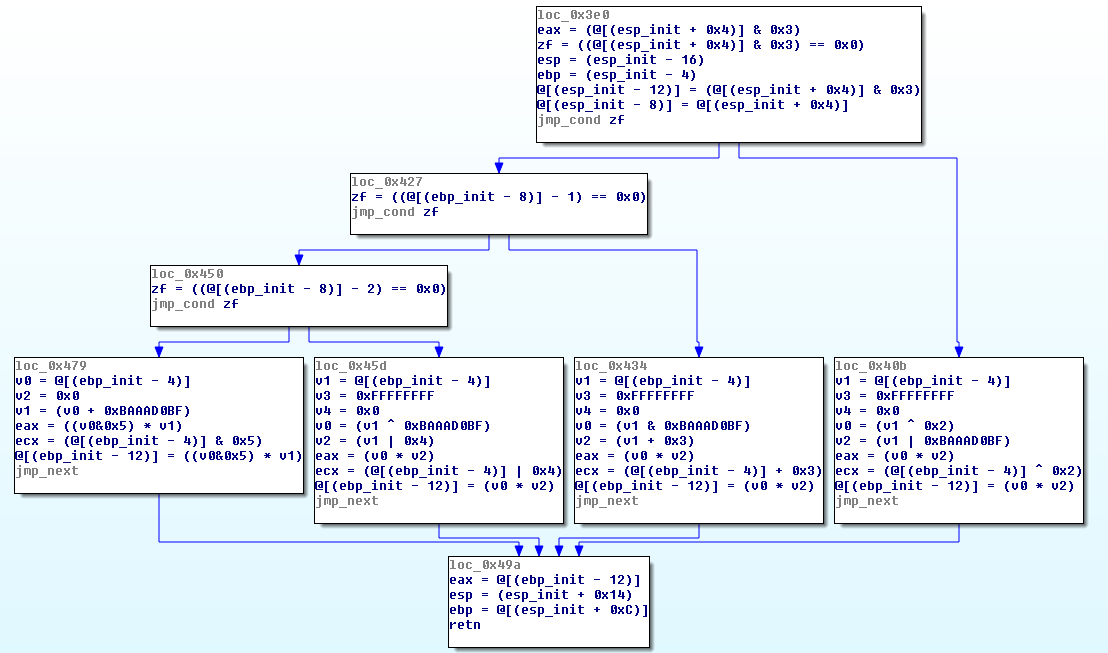
使结果输出展示更容易理解还需要有一些努力改进,但对于本文来说足够了。在上图中,我们可以看到3个条件和4个路径及其各自的运算。当然展示的图形是无法去执行的,但它为分析者正确地理解函数含义保留了足够的信息。而这就是反混淆的意义所在。
我们的脚本生成图形比较简陋,在基本块中没有颜色和美化。并且这不是纯粹的Miasm IR代码,阅读起来比较困难。所以我们选择将IR转换为一些伪代码(近似Python)。
所以当我们完成一些反混淆测试需要展示结果时,我们可以使用同样的方法生成图形输出,将其与上面的原始截图进行比较。
OLLVM反混淆
快速演示
在这里我们不会详细解释OLLVM的工作原理,因为这些在其项目网站(http://o-llvm.org)中已经被很好地阐释说明。简单来说,它由3种不同的保护方式组成:控制流平坦化,虚假控制流和指令替换,这些保护方式可以累加,对于静态分析来说混淆后代码非常复杂。在这一部分,我们将展示如何逐一去除每种保护,最后去除全部方式累加后的混淆保护。
控制流平坦化
关于“控制流平坦化”解释如下: https://github.com/obfuscator-llvm/obfuscator/wiki/Control-Flow-Flattening
使用以下命令行编译测试代码:
../build/bin/clang -m32 target.c -o target_flat -mllvm -fla -mllvm -perFLA=100
这个编译命令会对我们的测试程序所有函数开启“控制流平坦化”保护,以便确保我们的测试具有针对性。
被混淆保护的函数
通过IDA查看被混淆目标函数的控制流图如下:
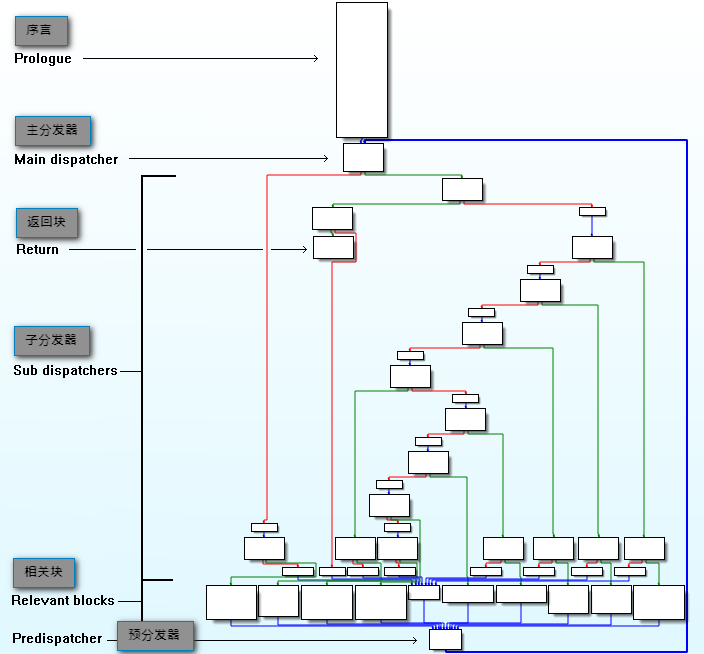
混淆代码的行为很简单。在“序言”中,状态变量受数字常数的影响,而该数字常量通过“主分发器”(包括“子分发器”)指引到达目标基本“关联块”所需的路径。“相关块”就是没有经过混淆的函数的原始块。在每个基本“相关块”的结尾,状态变量受另一个数字常量的影响,再指示下一个“相关块”,以此循环类推。
原始条件被转换为CMOV条件传送指令,然后根据比较结果,在状态变量中设置下一个“相关块”。
由于这种转换传递在指令级别并没有添加任何保护,所以混淆后代码仍然保持了可读性。只有控制流程图被破坏打乱。我们现在的目标是恢复函数原始的控制流程图。我们需要恢复所有可能的执行路径,这意味着为了重建控制流程图,我们需要知道所有基本“相关块”之间的链接关系(父子节点)。
这里我们需要一个符号执行工具来遍历代码,并尝试计算每个基本块的目标终点。当出现判断条件分支时,它将帮助我们尝试运行并获取所有分支可能到达的目标地址列表。Miasm框架包含有一个符号执行引擎(支持x86 32位等架构),其基于自身的“中间表示”(IR)实现,并且可以通过反汇编器转换二进制代码到“中间表示”(IR)。
下面是Miasm 脚本代码,通过这个代码我们可以在函数基本块上进行符号执行来计算其目标地址:
# Imports from Miasm framework
from miasm2.core.bin_stream import bin_stream_str
from miasm2.arch.x86.disasm import dis_x86_32
from miasm2.arch.x86.ira import ir_a_x86_32
from miasm2.arch.x86.regs import all_regs_ids, all_regs_ids_init
from miasm2.ir.symbexec import symbexec
from miasm2.expression.simplifications import expr_simp
# Binary path and offset of the target function 【程序路径与目标函数代码偏移】
offset = 0x3e0
fname = "../src/target"
# Get Miasm's binary stream [获取文件二进制流]
bin_file = open(fname, "rb").read() # fix: (此处原文代码BUG,未指定“rb”模式可能导致文件读取错误)
bin_stream = bin_stream_str(bin_file)
# Disassemble blocks of the function at 'offset' 【反汇编目标函数基本块】
mdis = dis_x86_32(bin_stream)
disasm = mdis.dis_multibloc(offset)
# Create target IR object and add all basic blocks to it 【创建IR对象并添加所有的基本块】
ir = ir_a_x86_32(mdis.symbol_pool)
for bbl in disasm: ir.add_bloc(bbl)
# Init our symbols with all architecture known registers 【符号初始化】
symbols_init = {}
for i, r in enumerate(all_regs_ids):
symbols_init[r] = all_regs_ids_init[i]
# Create symbolic execution engine 【创建符号执行引擎】
symb = symbexec(ir, symbols_init)
# Get the block we want and emulate it 【获取目标代码块并进行符号执行】
# We obtain the address of the next block to execute
block = ir.get_bloc(offset)
nxt_addr = symb.emulbloc(block)
# Run the Miasm's simplification engine on the next
# address to be sure to have the simplest expression 【精简表达式】
simp_addr = expr_simp(nxt_addr)
# The simp_addr variable is an integer expression
# (next basic block offset) 【如果simp_addr变量是整形表达式(下一个基本块的偏移)】
if isinstance(simp_addr, ExprInt):
print("Jump on next basic block: %s" % simp_addr)
# The simp_addr variable is a condition expression 【如果simp_addr变量为条件表达式】
elif isinstance(simp_addr, ExprCond):
branch1 = simp_addr.src1
branch2 = simp_addr.src2
print("Condition: %s or %s" % (branch1,branch2))
上述代码只是针对单个基本块进行符号执行的示例。为了覆盖目标函数代码的所有基本块,我们可以使用这段代码从目标函数的序言开始跟踪函数执行流程。如果遇到判断条件则逐一探索每个流程分支,直到完全覆盖目标函数。
当执行到函数返回位置后还需要继续跟踪下一个有效分支,我们就必须有一个分支栈来处理这些情况。我们需要保存每一个分支状态,当需要后续处理的时候就可以用来恢复所有符号执行过程的上下文信息(例如寄存器)。
中间函数
通过应用之前的解决思路,我们可以重建中间控制流程图。下面通过流程图处理脚本进行展示:
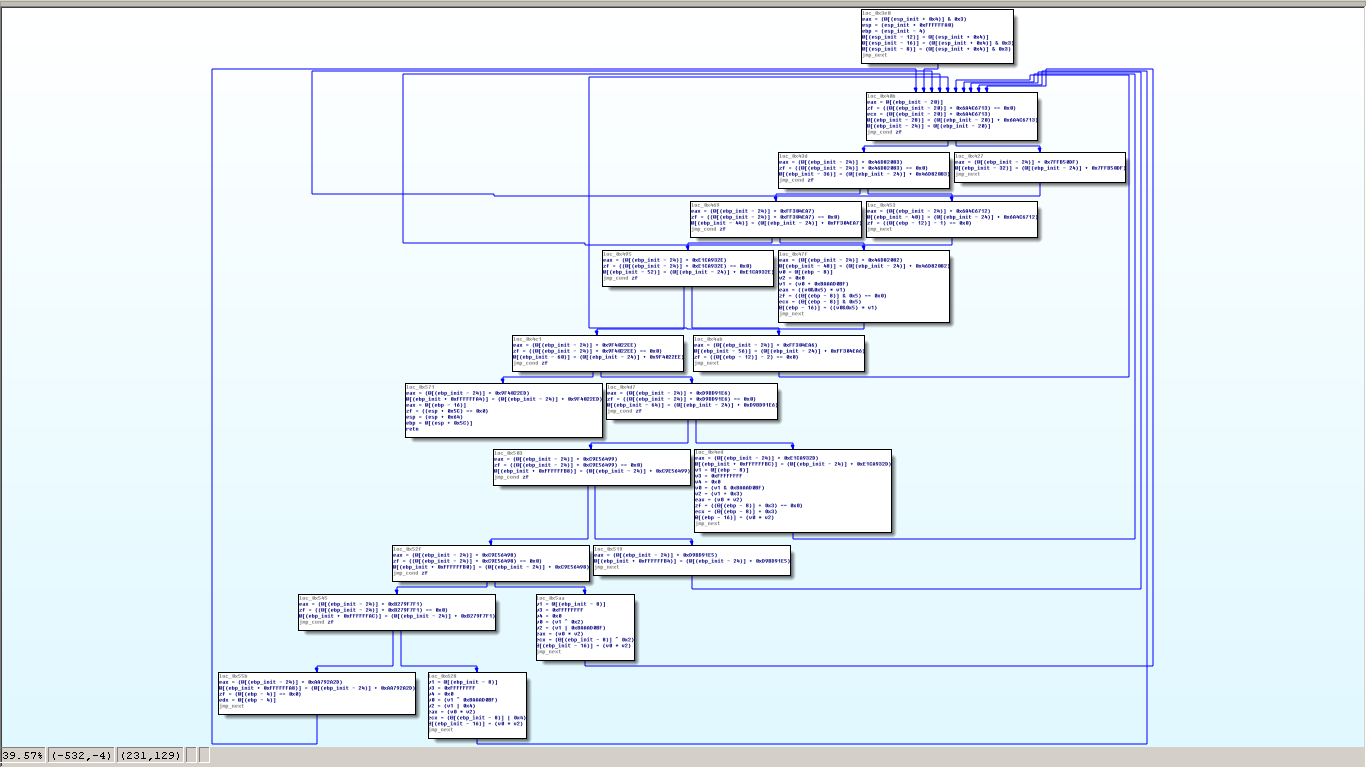
在这个中间函数流图中,现在可以清楚看到所有有用的基本块和分支条件。“主分发器”及“子分发器“对代码执行有用,但对于我们恢复原始控制流程图的目标来说是无用的。我们需要清除这些分发器代码,只保留“相关块。
为了实现这个目标,可以对OLLVM控制流平坦化后的函数固定“形状”分析。实际上大多数“相关块”(除了序言和返回基本块)位于可以被检测的明确位置。为了定位这些“相关块”,我们需要从被保护的原函数开始,构建编写一个具备通用性的算法:
- 序言块位于函数开始(相关块)
- (译者补充:序言的后续子节点为主分发器),处于主分发器时获取其父节点(非序言):预分发器
- 标记预分发器的所有父节点为相关块
- 标记没有子节点的单独块:返回块
这个算法很容易实现,如前文所见,Miasm反汇编器可以为我们提供目标函数反汇编后的基本块列表。当获得相关的块列表后,我们就能够在符号执行时通过以下规则算法重建原控制流:
- 定义一个父节点块(开始处序言)的集合变量(只有“相关块”才能加入)
- 对于每个新块,如果它在相关块列表中,我们可以将它和父节点块链接起来。并将此新块设置为父节点。
- 在每个条件分支下,每个路径都有自己的父节点相关块变量。
- 其他等等。
为了说明这个算法,以下是示例代码:
# Here we disassemble target function and collect relevants blocks
# Collapsed for clarity but nothing complicated here, and the algorithm is given above
relevants = get_relevants_blocks()
# Control flow dictionnary {parent: set(childs)} 【控制流字典变量 {父节点: 集合(子节点)}】
flow = {}
# Init flow dictionnary with empty sets of childs 【使用空集合初始化控制流变量】
for r in relevants: flow[r] = set()
# Start loop of symbolic execution 【开始符号执行循环】
while True:
block_state = # Get next block state to emulate
# Get current branch parameters 【获取当前分支参数】
# "parent_addr" is the parent block variable se seen earlier
# 【"parent_addr"即前面所说的父节点块】
# "symb" is the context (symbols) of the current branch 【"symb"即当前分支上下文】
parent_addr, block_addr, symb = block_state
# If it is a relevant block 【如果是相关块】
if block_addr in flow:
# We avoid the prologue's parent, as it doesn't exist 【忽略序言父节点】
if parent_addr != ExprInt32(prologue_parent):
# Do the link between the block and its relevant parent 【关联目标块与其父节点块】
flow[parent_addr].add(block_addr)
# Then we set the block as the new relevant parent 【将当前块设置为新的父节点块】
parent_addr = block_addr
# Finally, we can emulate the next block and so on.
恢复函数
通过使用上面的算法,可以生成如下控制流程图:
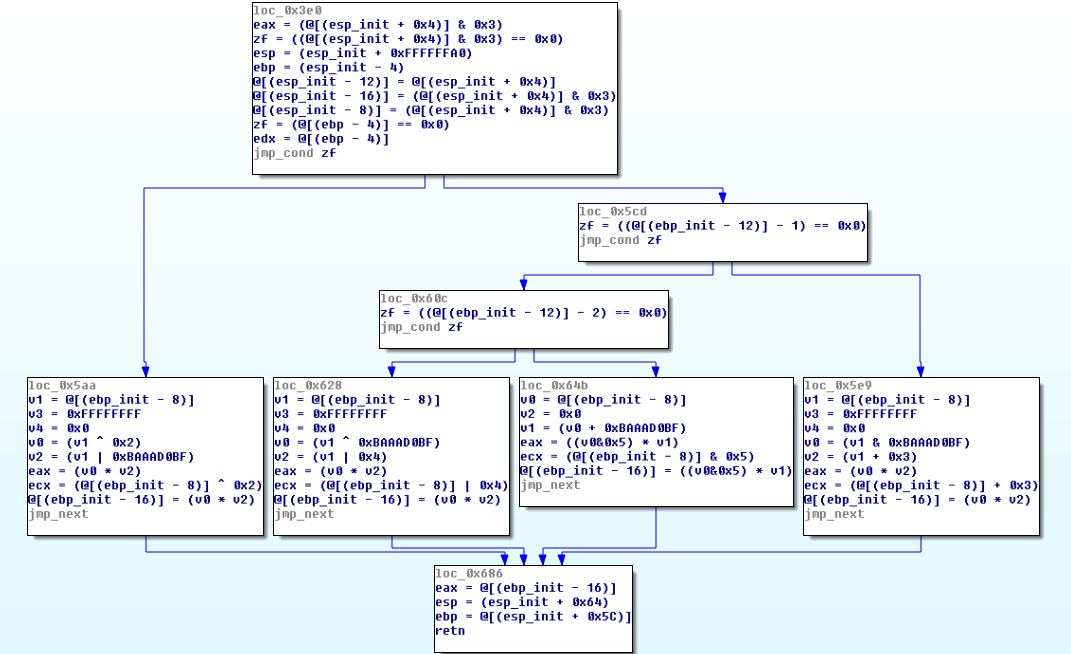
如上,原始代码被完整恢复。我们可以看到用于计算输出结果的3个条件分支和4个计算表达式。
虚假控制流
关于“虚假控制流”的解释:https://github.com/obfuscator-llvm/obfuscator/wiki/Bogus-Control-Flow
使用以下命令行编译测试代码:
../build/bin/clang-m32 target.c -o target_flat -mllvm -bcf -mllvm -boguscf-prob=100 -mllvm-boguscf-loop=1
该编译命令可以在我们的测试程序的函数上启用“虚假控制流”保护。我们将“-boguscf-loop”参数(循环次数)设置为1,对反混淆处理没有影响,只是代码生成和恢复过程会比较慢,并且内存消耗更多。
被保护函数
当我们使用IDA Pro加载目标程序时,控制流图如下:

屏幕分辨率在这里已变得不再重要,因为从上图中我们足以看出混淆后的函数代码非常复杂。“虚假控制流”保护会对每个基本块进行混淆,创建一个包含“不透明谓词”的新代码块,“不透明谓词”会生成条件跳转:可以跳转到真正的基本块或另一个包含垃圾指令的代码块。
我们可以同样使用前文中的符号执行方法,找到所有有用基本块并重建控制流。但还存在一个问题:“不透明谓词”,如果包含垃圾代码的基本块返回它的父节点块,这种情况下如果我们在符号执行过程中还按这个路径去跟踪,将导致陷入死循环。所以需要先解决“不透明谓词”问题,以避免垃圾代码块,直接找到正确的执行路径。
下面是“不透明谓词”问题在OLLVM源码中的图形注释:
// Before :
// entry
// |
// ______v______
// | Original |
// |_____________|
// |
// v
// return
//
// After :
// entry
// |
// ____v_____
// |condition*| (false)
// |__________|----+
// (true)| |
// | |
// ______v______ |
// +-->| Original* | |
// | |_____________| (true)
// | (false)| !-----------> return
// | ______v______ |
// | | Altered |<--!
// | |_____________|
// |__________|
//
// * The results of these terminator's branch's conditions are always true, but these predicates are
// opacificated. For this, we declare two global values: x and y, and replace the FCMP_TRUE
// predicate with (y < 10 || x * (x + 1) % 2 == 0) (this could be improved, as the global
// values give a hint on where are the opaque predicates)
在进行符号执行时,我们需要简化这个“不透明谓词”:(y <10 || x *(x + 1)%2 == 0)。Miasm框架仍然可以帮助我们完成这个任务,因为框架包含了一个基于自身IR(中间表示)的表达式简化引擎。我们还需加深对不透明谓词的了解。因为这两个表达式之间通过“或”连接,并且结果必须为真,所以简化一个表达式足矣。 当下目标是使用Miasm框架进行模式匹配,并将表达式x *(x + 1)%2替换为0。这样“不透明谓词”的正确结果为真,这一点很容易解决。 看起来OLLVM项目的程序员在上面的代码注释中犯了一点错误:代码注释中说的“不透明谓词”是错的。最初使用Miasm框架的简化引擎没有匹配到目标表达式。通过查看Miasm框架代码中给出的表达式,我们发现实际的“不透明谓词”方程是:(x *(x + 1)%2)(减1而并非加1)。 这个问题可以通过查看OLLVM源码来验证:
*BogusControlFlow.cpp:620*
//if y < 10 || x*(x+1) % 2 == 0
opX = new LoadInst ((Value *)x, "", (*i));
opY = new LoadInst ((Value *)y, "", (*i));
op = BinaryOperator::Create(Instruction::Sub, (Value *)opX,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 1,
false), "", (*i));
这段代码展示了上述问题。代码注释中写的(x + 1),但实际上代码使用了sub指令,说明表达式应该是:(x-1)。因为最后做模2操作,所以对计算结果值影响不大,因为两种表达式的结果是相同的,但对于使用模式匹配来说这个信息很关键。
因为我们确切地知道匹配目标,以下是使用Miasm模式匹配的代码示例:
# Imports from Miasm framework
from miasm2.expression.expression import *
from miasm2.expression.simplifications import expr_simp
# We define our jokers to match expressions
jok1 = ExprId("jok1")
jok2 = ExprId("jok2")
# Our custom expression simplification callback 【表达式匹配回调函数】
# We are searching: (x * (x - 1) % 2)
def simp_opaque_bcf(e_s, e):
# Trying to match (a * b) % 2 【尝试匹配(a * b) % 2】
to_match = ((jok1 * jok2)[0:32] & ExprInt32(1))
result = MatchExpr(e,to_match,[jok1,jok2,jok3])
if (result is False) or (result == {}):
return e # Doesn't match. Return unmodified expression
# Interesting candidate, try to be more precise 【进一步精准匹配 b == (a - 1)】
# Verifies that b == (a - 1)
mult_term1 = expr_simp(result[jok1][0:32])
mult_term2 = expr_simp(result[jok2][0:32])
if mult_term2 != (mult_term1 + ExprInt(uint32(-1))):
return e # Doesn't match. Return unmodified expression
# Matched the opaque predicate, return 0 【匹配到表达式后返回0】
return ExprInt32(0)
# We add our custom callback to Miasm default simplification engine
# 【添加自定义回调函数到Miasm默认简化引擎中】
# The expr_simp object is an instance of ExpressionSimplifier class
# 【expr_simp对象是ExpressionSimplifier类的实例】
simplifications = {ExprOp : [simp_opaque_bcf]}
expr_simp.enable_passes(simplifications)
这样当每次我们调用方法:exprsimp(e) (“e”是一个Miasm IR 的lambda表达式),如果其中包含“不透明谓词”就会被简化。由于Miasm IR类有时调用exprsimp()方法,此回调函数在IR修改期间可能会被执行。
中间函数
现在我们需要使用与之前相同的符号执行算法,但无需处理相关块。因为无用的块不会被执行,它们将被自动清除。可以获得以下控制流图:
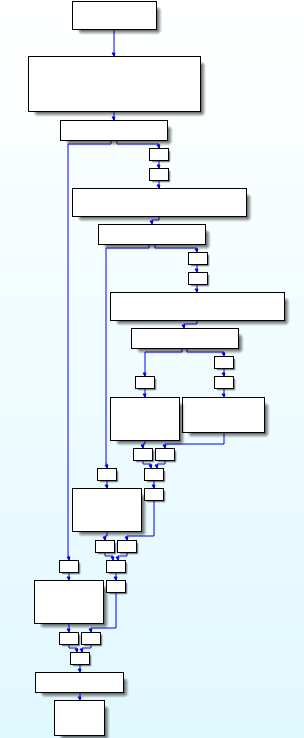
添加“不透明谓词”识别到我们的原来的算法中后,Miasm框架会简化这些表达式,最后得到上图展示的结果。符号执行会找到所有的可达路径,并忽略不可达路径。可以看出函数流程图的“形状”是正确的,但是这个结果图还比较难看,因为其中还包含了OLLVM添加的剩余指令和一些空的基本块。
恢复函数
现在可以使用与以前相同的算法去清除残留垃圾代码(控制流平坦化)。虽然这个方法不是很优雅,但不得不这么做,因为我们无法使用编译器优化这些。 最终我们获得以下流程图,它和原始流程图已非常接近:
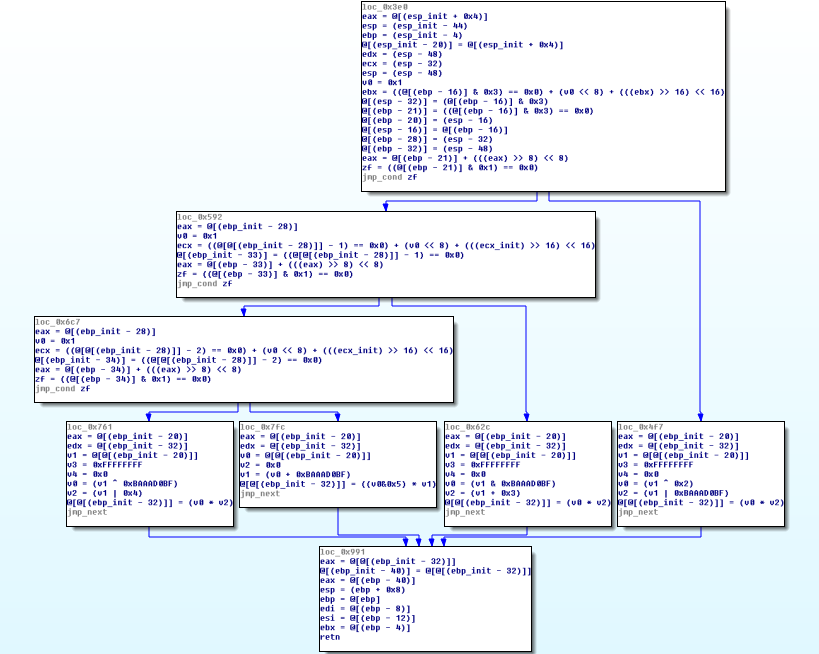
混淆后的代码被完好恢复。同样可以看到3个条件分支和4个用于计算输出值的计算表达式。
指令替换
关于“指令替换”的解释:https://github.com/obfuscator-llvm/obfuscator/wiki/Instructions-Substitution 使用以下命令行编译测试代码:
../build/bin/clang -m32 target.c -o target_flat -mllvm -subv
上述编译命令会在我们的测试程序的所有函数开启“指令替换”保护。
保护函数
“指令替换”保护不会修改函数原始的控制流程,使用Miasm IR图形展示中如下:
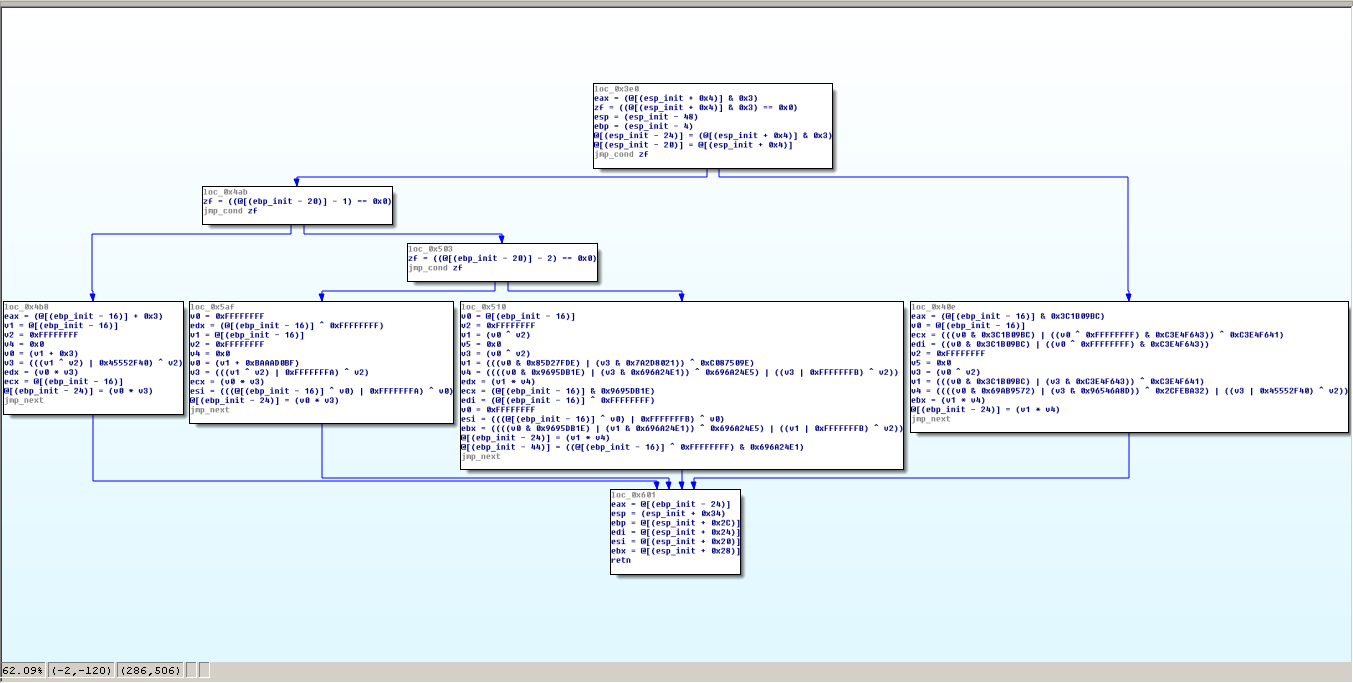
正如期望的那样,函数流程图“形状”没有改变,仍可以看到相同的条件分支,但是在“相关块”中,可以看到对输入值的计算过程变得更繁杂。因为这个例子中代码比较简单,所以混淆复杂度看起来还能够接受,但如果是比较庞大的函数源码,这样的混淆也足够恶心。 OLLVM项目把普通算术和布尔运算替换为更复杂的操作。但由于“指令替换”只是一个等价转换表达式列表,我们仍然可以通过使用Miasm模式匹配去解除这种保护。 从OLLVM项目官网上我们可以看到,根据运算符不同,有以下几种指令被替换:+, – ,^,| ,& 以下是简化OLLVM项目 XOR指令替换的代码:
# Imports from Miasm framework
from miasm2.expression.expression import *
from miasm2.expression.simplifications import expr_simp
# We define our jokers to match expressions
jok1 = ExprId("jok1")
jok2 = ExprId("jok2")
jok3 = ExprId("jok3")
jok4 = ExprId("jok4")
# Our custom expression simplification callback 【表达式匹配简化回调函数】
# We are searching: (~a & b) | (a & ~b) 【匹配表达式(~a & b) | (a & ~b)】
def simp_ollvm_XOR(e_s, e):
# First we try to match (a & b) | (c & d)
to_match = (jok1 & jok2) | (jok3 & jok4)
result = MatchExpr(e,to_match,[jok1,jok2,jok3,jok4])
if (result is False) or (result == {}):
return e # Doesn't match. Return unmodified expression
# Check that ~a == c
if expr_simp(~result[jok1]) != result[jok3]:
return e # Doesn't match. Return unmodified expression
# Check that b == ~d
if result[jok2] != expr_simp(~result[jok4]):
return e # Doesn't match. Return unmodified expression
# Expression matched. Return a ^ d 【匹配成功返回a ^ d】
return expr_simp(result[jok1]^result[jok4])
# We add our custom callback to Miasm default simplification engine
# The expr_simp object is an instance of ExpressionSimplifier
simplifications = {ExprOp : [simp_ollvm_XOR]}
expr_simp.enable_passes(simplifications)
这个方法对于所有指令的替换恢复都是相同的。只需检查Miasm框架是否正确匹配即可。但Miasm有时会出现一些匹配上问题,这可能会有点棘手或耗费时间,这时对公式匹配就需要特殊处理。但是当它完成…一切就搞定了。 另外在这个问题上我们有一个重要优势,就是正在被分析的混淆器是开源的,通过查看源代码就可以知道指令替换公式。如果是在闭源的混淆器中,我们就必须手动找到它们,这个过程可能非常耗时。
恢复函数
将所有OLLVM的替换公式添加到Miasm简化引擎后,我们可以重新生成如下控制流图:
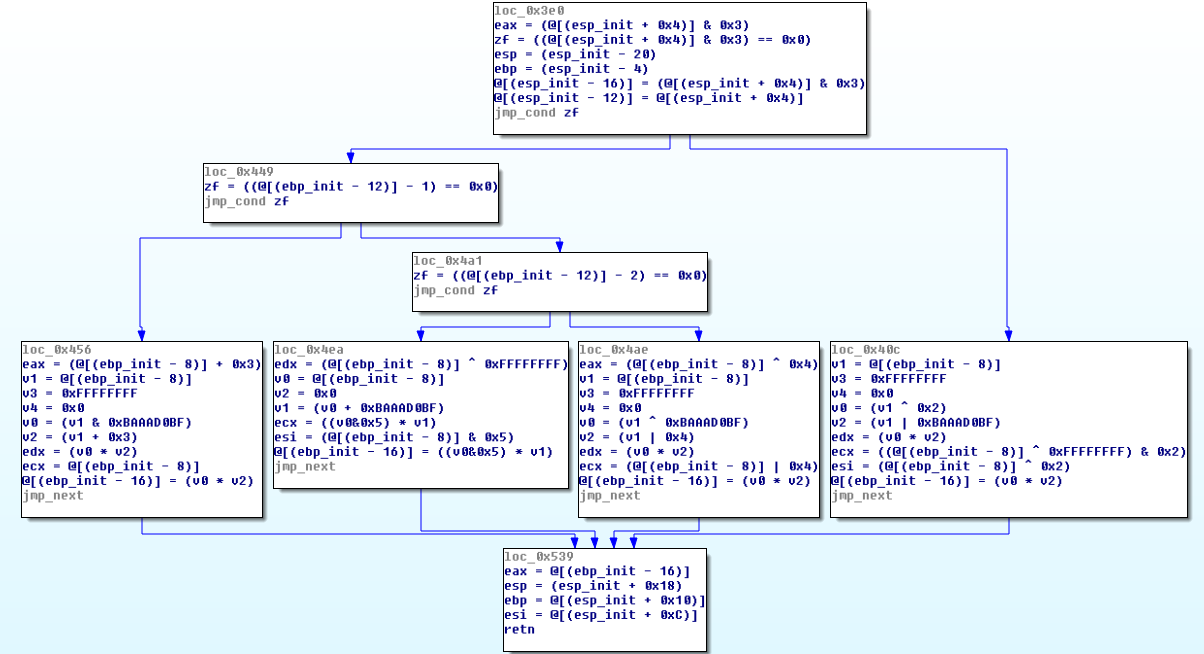
可以看到在上面截图中的基本块比较小,指令混淆已经被清理替换。这样我们得到了原始函数,这对分析者来说比较清晰易懂。
完整保护
逐个打破所有的保护是个可行的思路,通常来说,混淆器的保护力度是可以被叠加的,这使得未处理的混淆代码很难被理解。另外在现实情况中,一般都会启用最大保护级别去混淆模糊目标软件代码。所以能够处理完整保护显得非常重要。
使用以下编译命令对测试目标函数启用OLLVM完整保护:
../build/bin/clang -m32 target.c -o target_flat -mllvm -bcf -mllvm -boguscf-prob=100 -mllvm -boguscf-loop=1 -mllvm -sub -mllvm -fla -mllvm -perFLA=100
保护函数
通过IDA查看被保护的函数代码,可以看到以下控制流图:
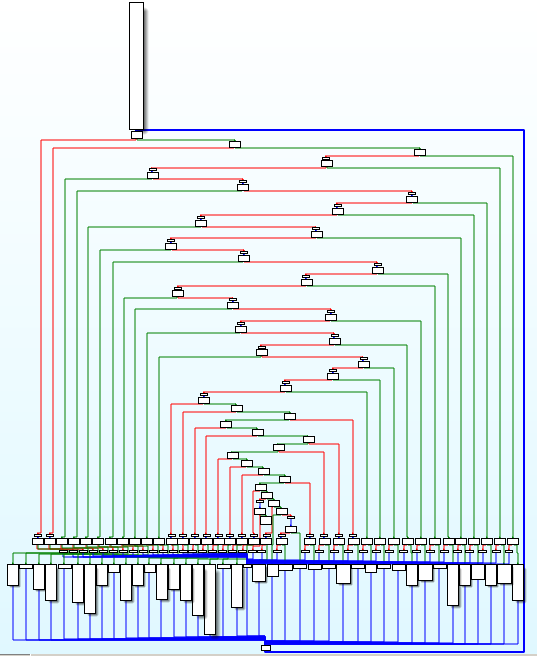
可以看出很重要的一点,通过保护方式叠加似乎明显地提高了代码的混淆程度,因为“不透明谓词”可以通过“指令替换”来转换实现,而“控制流平坦化”又会被应用于“伪造控制流”保护后的代码。从上面的截图中可以看到更加庞杂的相关块。
恢复函数
我们没有对前文中描述的方法进行任何修改,直接运行我们的脚本后就可以完全恢复被混淆后的函数代码,虽然上面混淆后的函数代码看起来非常糟糕,但是可以说在保护级别上,叠加保护和之前的保护并没有任何区别。
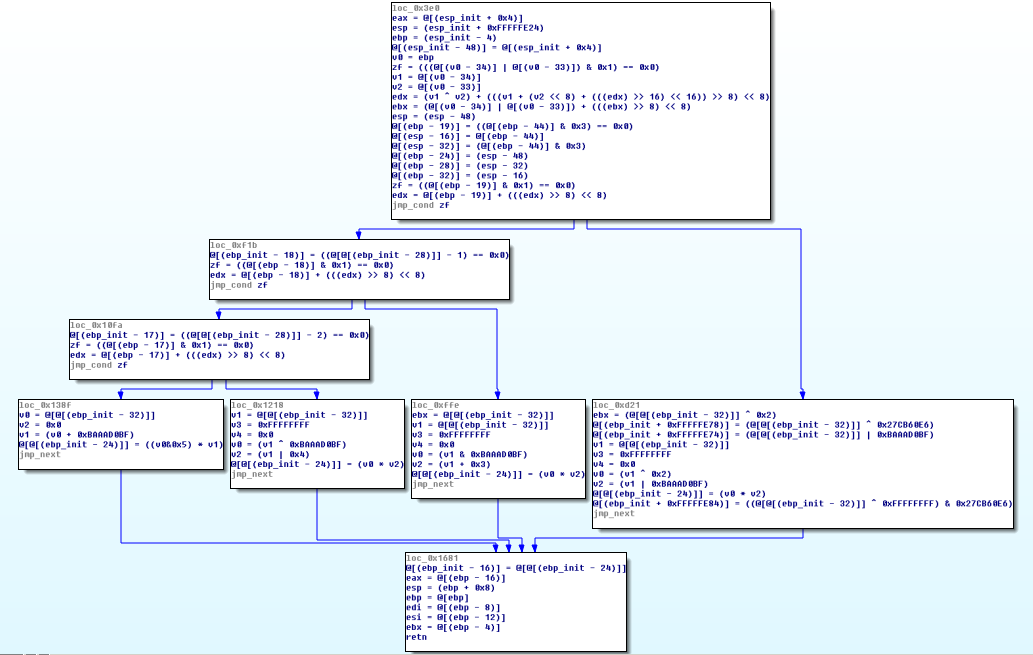
可以看到一些无用指令行并没有被我们的启发脚本完全清除,但这些可以被可忽略,因为我们已经恢复出原始函数的“形状”、条件分支和运算公式。
附加
如上文所述,我们可以通过“重建控制流并使用易懂伪代码填充”的方式清除控制流保护。在我们的下面测试例子中,我们将使用Miasm符号执行引擎展示另一种不同思路。
目标函数接受参数输入并输出值,结果取决于输入。我们可以这么做,在符号执行期间,每次到达一个分支结尾(返回)时,输出EAX(x86 32位架构中返回值寄存器)对应的表达式。对于此示例,如上文所见,我们已经激活了完整的OLLVM保护选项。
# .. Here we have to do basic blocks symbolic execution, as we seen earlier ..
# Jump to next basic block
if isinstance(simp_addr, ExprInt):
# Useless code removed here...
# Condition
elif isinstance(simp_addr, ExprCond):
# Useless code removed here...
# Next basic block address is in memory
# Ugly way: Our function only do that on return, by reading return value on the stack
elif isinstance(simp_addr, ExprMem):
print("-"*30)
print("Reached return ! Result equation is:")
# Get the equation of EAX in symbols 【读取EAX对应表达式】
# "my_sanitize" is our function used to display Miasm IR "properly" 【格式化表达式】
eq = str(my_sanitize(symb.symbols[ExprId("EAX",32)]))
# Replace input argument memory deref by "x" to be more understandable 【替换参数为x更易读】
eq = eq.replace("@32[(ESP_init+0x4)]","x")
print("Equation = %s" % eq)
通过符号执行运行上面的代码,我们得到以下输出:
starting symbolic execution...
------------------------------
Reached return ! Result equation is:
Equation = ((x^0x2) * (x|0xBAAAD0BF) & 0xffffffff)
------------------------------
Reached return ! Result equation is:
Equation = ((x&0xBAAAD0BF) * (x+0x3) & 0xffffffff)
------------------------------
Reached return ! Result equation is:
Equation = ((x^0xBAAAD0BF) * (x|0x4) & 0xffffffff)
------------------------------
Reached return ! Result equation is:
Equation = ((x&0x5) * (x+0xBAAAD0BF) & 0xffffffff)
------------------------------
symbolic execution is done.
非常好,这个表达式结果正是我们测试例子的源代码中所写的!
结论
虽然这些脚本对于反混淆是一个不错的开端,但它不可能适用于所有被OLLVM保护的代码,一方面在一些目标程序上总是存在特殊的情况,这些脚本还需要相应地进行改进以适应不同情况。而且它还依赖于Miasm框架,其本身还存在一些功能限制,需要实现或提交改进。
在例如“循环”这样更复杂的函数上我们测试了这些脚本,它仍然效果良好。但也存在其无法处理的特殊情况,比如当输入参数决定循环停止条件时。这种情况处理起来比较困难,因为我们必须处理已经遇到的分支,否则将很快导致符号执行陷入死循环。为了检测这些情况,就需要通过分支状态差异来推断循环停止条件,以继续正常地符号执行。
OLLVM是一个非常有趣并且有意义的项目,它实例展示了如何通过操作LLVM构建自己的混淆器,并支持多CPU架构。显而易见,与闭源的商业保护方案相比,能够查看源码对于对抗保护非常有用。这也显示了一个强大的混淆器所依赖的秘密:如何使用变换,变换依赖于什么,如何组合保护策略等。所以,真的非常感谢OLLVM团队公开这些。
代码混淆做起来是非常困难的,这与大多人的想法都不同。混淆不是禁止访问代码和数据,而是预见突破保护层所需的时间成本。
致谢
- 感谢OLLVM作者的优秀项目
- 感谢Fabrice Desclaux创建优秀的Miasm框架
- 感谢Camille Mougey对Miasm的贡献和帮助
- 感谢Ninon Eyrolles的帮助和指正
附件-测试程序下载链接:https://share.weiyun.com/c38128f2b56d60fbfac6d6144f52fa8a

