Python基础综合练习
Pycharm开发环境设置与熟悉。
练习基本输入输出:
print('你好,{}.'.format(name))
print(sys.argv)
库的使用方法:
import ...
from ... import ...
条件语句:
if (abs(pos()))<1:
break
循环语句:
for i in range(5):
while True:
函数定义:
def mygoto(x,y):
def drawjx(r):
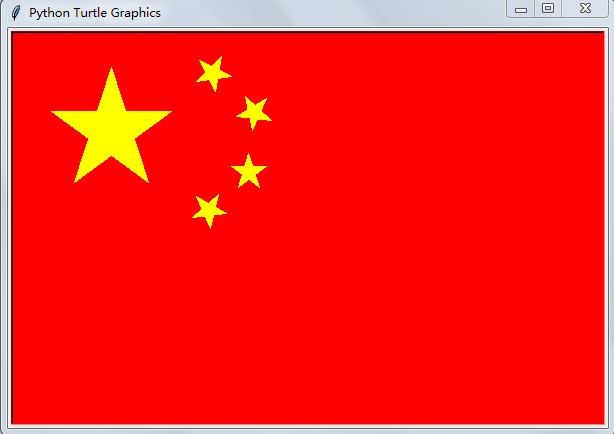
综合练习:画一面五星红旗,将代码与运行截图发布博客交作业
import turtle turtle.setup(600,400,0,0) turtle.bgcolor("red") turtle.fillcolor("yellow") turtle.color("yellow") def mygoto(x,y): turtle.up() turtle.goto(x, y) turtle.down() def drawwjx(l): turtle.begin_fill() for i in range(5): turtle.forward(l) turtle.right(144) turtle.end_fill() mygoto(-260,120) drawwjx(120) turtle.left(45) mygoto(-115,150) drawwjx(35) turtle.right(15) mygoto(-75,115) drawwjx(35) turtle.right(30) mygoto(-80,65) drawwjx(35) turtle.right(30) mygoto(-115,35) drawwjx(35) #画出网格,测试用 # turtle.color("black") # turtle.speed(10) # def paint(x,y): # turtle.up() # turtle.goto(x,y) # turtle.down() # # x1 = -280 # y1 = 200 # turtle.right(60) # for i in range(29): # paint(x1,y1) # turtle.forward(400) # x1 = x1+20 # # x2 = -300 # y2 = 180 # turtle.left(90) # for i in range(19): # paint(x2,y2) # turtle.forward(600) # y2 = y2-20 turtle.hideturtle() turtle.done()
字符串练习:
http://news.gzcc.cn/html/2017/xiaoyuanxinwen_1027/8443.html
取得校园新闻的编号
schoolnew = 'http://news.gzcc.cn/html/2017/xiaoyuanxinwen_1027/8443.html' print(schoolnew) print(schoolnew[-14:-5])

https://docs.python.org/3/library/turtle.html
产生python文档的网址
addr1 = 'https://docs.python.org/3/library/' addr2 = '.html' print(addr1 + 'turtle' + addr2)

http://news.gzcc.cn/html/xiaoyuanxinwen/4.html
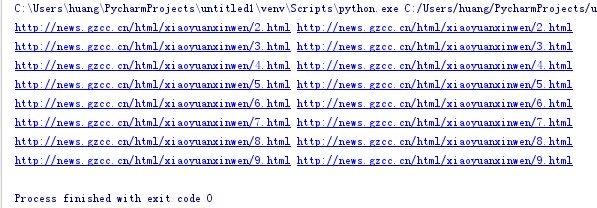
产生校园新闻的一系列新闻页网址
news1 = "http://news.gzcc.cn/html/xiaoyuanxinwen/" news2 = ".html" for i in range(2,10): newspage = news1 + str(i) + news2 newspage2 = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) print(newspage,newspage2)
练习字符串内建函数:strip,lstrip,rstrip,split,count,replace
用函数得到校园新闻编号
address = "http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html" for i in range(2, 10): addr3 = address.format(i) addr4 = addr3.rstrip(".html").split("/")[-1] print(addr4)

用函数统计一歌词(文章、小说)中单词出现的次数,替换标点符号为空格,用空格进行分词
str=''' In the eternal universe, every human being has a one-off chance to live --his existence is unique and irretrievable, for the mold with which he was made, as Rousseau said, was broken by God immediately afterwards. Fame, wealth and knowledge are merely worldly possessions that are within the reach of anybody striving for them. But your experience of and feelings about life are your own and not to be shared. No one can live your life over again after your death. A full awareness of this will point out to you that the most important thing in your existence is your distinctive individuality or something special of yours. What really counts is not your worldly success but your peculiar insight into the meaning of life and your commitment to it, which add luster to your personality. It is not easy to be what one really is. There is many a person in the world who can be identified as anything either his job, his status or his social role that shows no trace about his individuality. It does do him justice to say that he has no identity of his own, if he doesn't know his own mind and all his things are either arranged by others or done on others' sugg estions; if his life, always occupied by external things, is completely void of an inner world. You won't be able to find anything whatever, from head to heart, that truly belongs to him. He is, indeed, no more than a shadow cast by somebody else or a machine capable of doing business. ''' temp = str.replace(',',' ').replace('.',' ').replace('-',' ').replace('!',' ').replace(':',' ').replace(';',' ') word = [[0 for i in range(2)]for i in range(len(temp.split()))] word[0][0] = temp.split()[0] #把字符串数组的首位放进word[0][0],降低后面二维数组录入的复杂度 semp = 1 #记录存进word二维数组的下标 for i in range(1,len(temp.split())): #录入字符及出现次数到二维数组word for j in range(semp): if temp.split()[i] == word[j][0]: word[j][1] = word[j][1] + 1 break elif temp.split()[i] != word[j][0] and j==semp-1: word[semp][0] = temp.split()[i]; semp=semp+1 break for i in range(semp): #对二维数组word进行冒泡排序 for j in range(semp-1): if word[j][1] < word[j+1][1]: n1 = word[j][0] n2 = word[j][1] word[j][0] = word[j+1][0] word[j][1] = word[j+1][1] word[j+1][0] = n1 word[j+1][1] = n2 for i in range(semp): #按大到小输出 print(word[i][0],word[i][1]+1) print(str.count('he')) #所有包含he都算 print(temp.split().count('he')) #拆分后只有he被算

。。。。。。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号