


11G数据的hive初测试
首先,看到标题,我想就会有人喷我,①11G对于hadoop而言不值一提②做耗时测试本没有必要,毕竟hadoop用于线下系统。
我的想法:没那么复杂,只是想看下hadoop的文件处理能力和表现出的问题,只是单纯的享受这个解决问题并且得到结果的快感。
不那么多废话啦!直接进入正题:
1、数据来源:
apache的日志,接近900万条数据,大小为11个G。
2、创建表,并用正则匹配的方式导入数据,(这里hive的正则和普通正则,路由不同,之后会发新的博客讨论这个问题:(hive的正则)http://blog.csdn.net/lengzijian/article/details/7048575):
这里正则值提取的日志当中的:site:当前站点 ,get:当前站点请求页,fore:之前站点------主要用于点击流,淡然是简单版的。为了以后应付更大文件做准备。
3、导入数据,我这里有23个数据,分别代表一天的时间(可能少了一个小时),可以把这23个数据连接在一起导入,但是我没有这样做,因为分别看每一个的时间,很容易的看到每个时间段的访问量,对于绘制监控图比较方便。
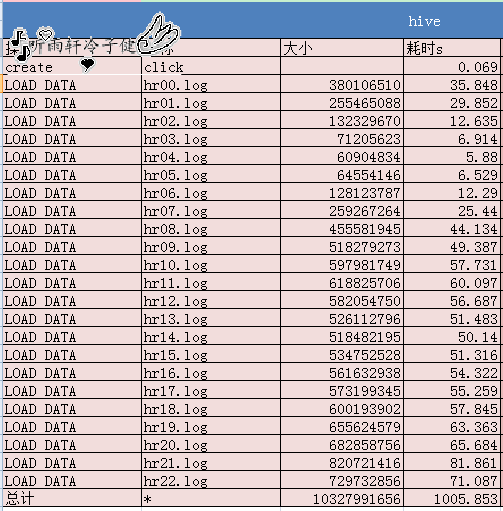
4、查询:因为刚刚做完没有经验,直接运行了
出现以下信息:
在执行过程中,一台电脑(子节点)一直再响,看了下cpu,双核几乎全被占满。最后结果运行了
测试先做到这里,之后会继续更新。


