

Redis—缓存雪崩,穿透
1、缓存穿透
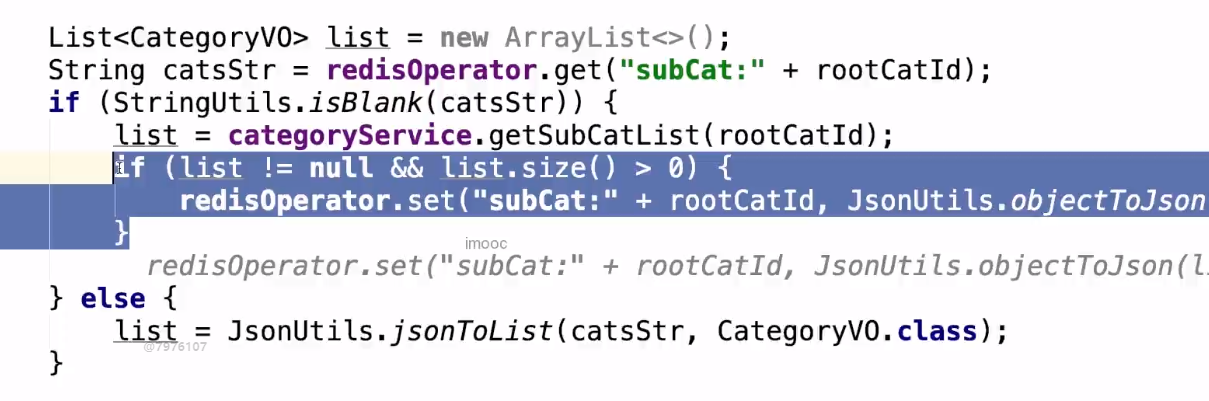
从上面代码可以看出,第二行从 Redis 缓存中获取,if 判断是否有数据,如果没有就从数据库中查询,判断 list 是否有数据,然后存入到 Redis 中。Redis 中如果存在数据就直接返回。
但是在这段代码中如果 Redis 中一直没有数据的话,它就会直接访问数据库,list 查询出来一直没有数据,Redis 中就不会有数据。当我们不管发起多少次请求执行这段代码,它都不会走 Redis, 而是走数据库。如果用户发起10w,几十万的数据请求,所有的请求都会打在数据库上,就会导致数据库崩溃,没有经过缓存,我们的缓存没有起到相应的做用,这样子就叫缓存穿透,我们不应该让这种情况存在。
解决方案:把空的数据也缓存起来,比如空字符串,空对象,空数组等,设置有效时间。
2、布隆过滤器
它是能够迅速的判断一个元素是否在一个集合里的,这个布隆过滤器本质是非常的小的,是以二进制存储的,里面全是 0,1。

0代表不存在,1代表存在,它是以这样的形式存在的,它就可以称之为布隆过滤滤器。正因为它是二进制存储的,都是0 1 ,哪怕是上一条数据在进行存储了以后,它不会占用我们很大的一个空间内存,而且它添加、查询速度极快的。使用布隆过滤器时候,你可以在使用邮件、短信拦截都可以使用布隆过滤器进行解决,它内部都是维护0101这样的数组。
布隆过滤器在 Redis 之前再做一次拦截。他有一个误判的概念,至少有一个1%的误判率,错误的判断。比方说有一个数据不存在这个数组的,在某些情况下它会有一个错误的判断,它会认为这个数据存在。对于误判来讲,它的误判率越低,整个数组的长度就会越长,相应的它占用空间的比值就会越大。误判率很高的话,那么这个数组比较的短,比较的小,相应的所占用的空间就小。
那么使用布隆过滤器的时候它虽然可以去解决这个缓存穿透的问题,但是它本身是包含了一些缺点。比方说我们的数据一旦我们添加到数组里面去了之后,你的查询是非常的快的,但是假设这个 key 我们移除了,不仅是数据库移除,也从 Redis 里面移除。这个我们要到布隆过滤器里面是移除不了的,是做不到一个移除删除的概念的。这种情况是因为多个数据是会存在于同一个位置,这样你删除其中一个是删不了的,一旦删除另一个怎么办。另一个就是它的误判这种情况会有的,另外我们在使用布隆过滤器的时候,代码复杂度会增大。要去维护一个集合,这个集合包含了很多很多 key ,这个也是要进行维护的。这个都是放到缓存里面相应的 key,而且是在一个集群、分布式的情况下的话,你的一个布隆过滤器还需要结合 Redis 来使用,数据存放到 Redis 里面去,保证各个节点都可用。
3、布隆过滤器使用
谷歌提供的依赖,其中就有布隆过滤器
<!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>28.1-jre</version> </dependency>
public class BloomFilterTest { @Test public void myTest() { // 10000 要插入的长度 BloomFilter bf = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 10000); for (int i = 0; i < 100000; i++) { bf.put(String.valueOf(i)); } int counts = 0; for (int i = 0; i < 100000; i++) { boolean b = bf.mightContain("test" + i); if (b) { counts++; } } System.out.println("误判率:" + counts); } }
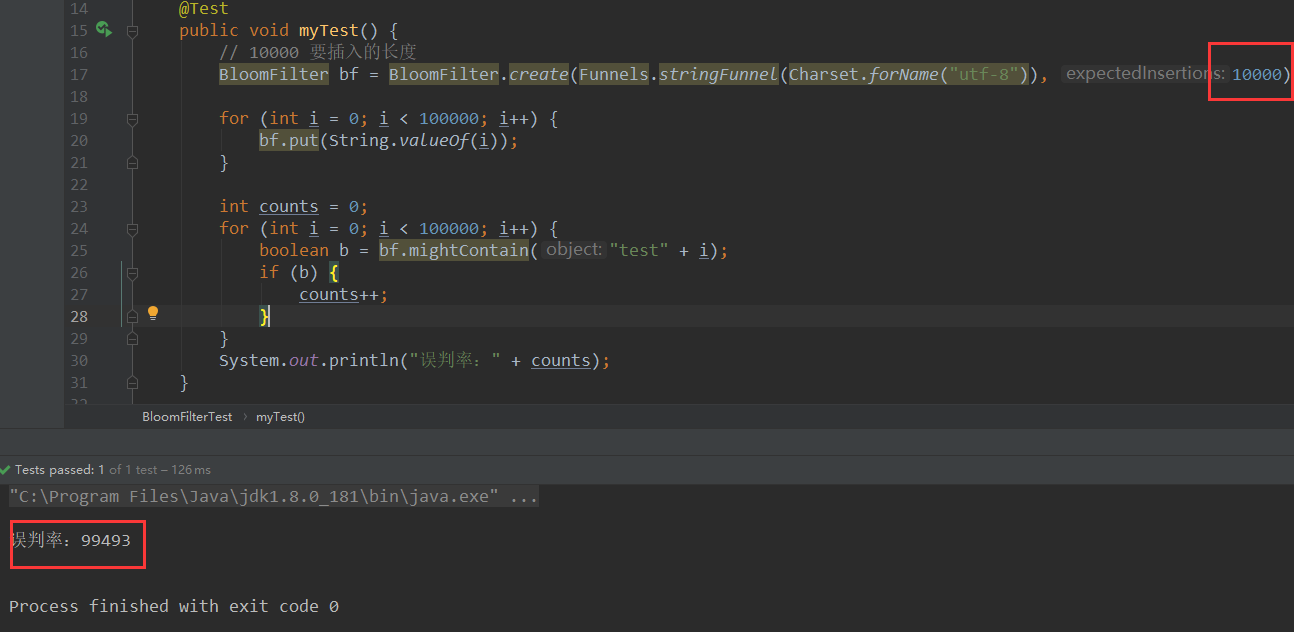
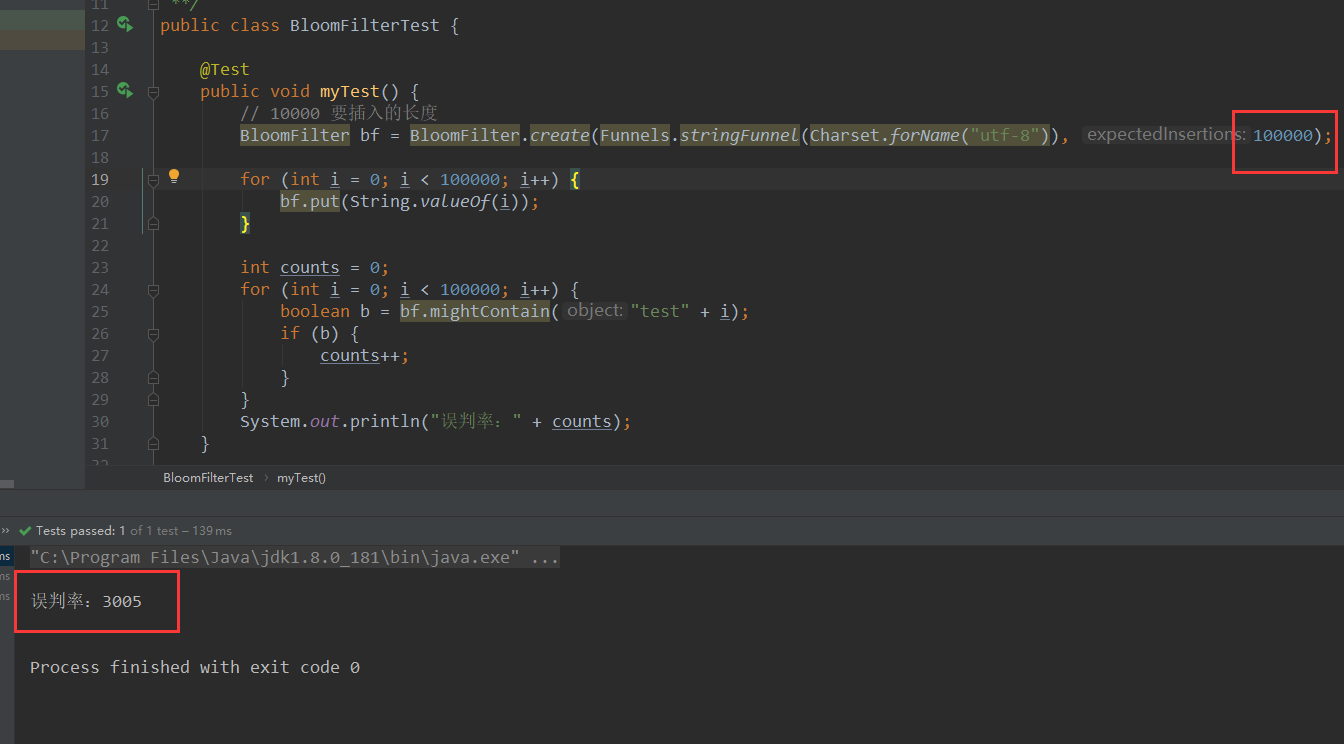
可以看出这个误判率很高。但是我们把长度增加看看,误判率低了很多。
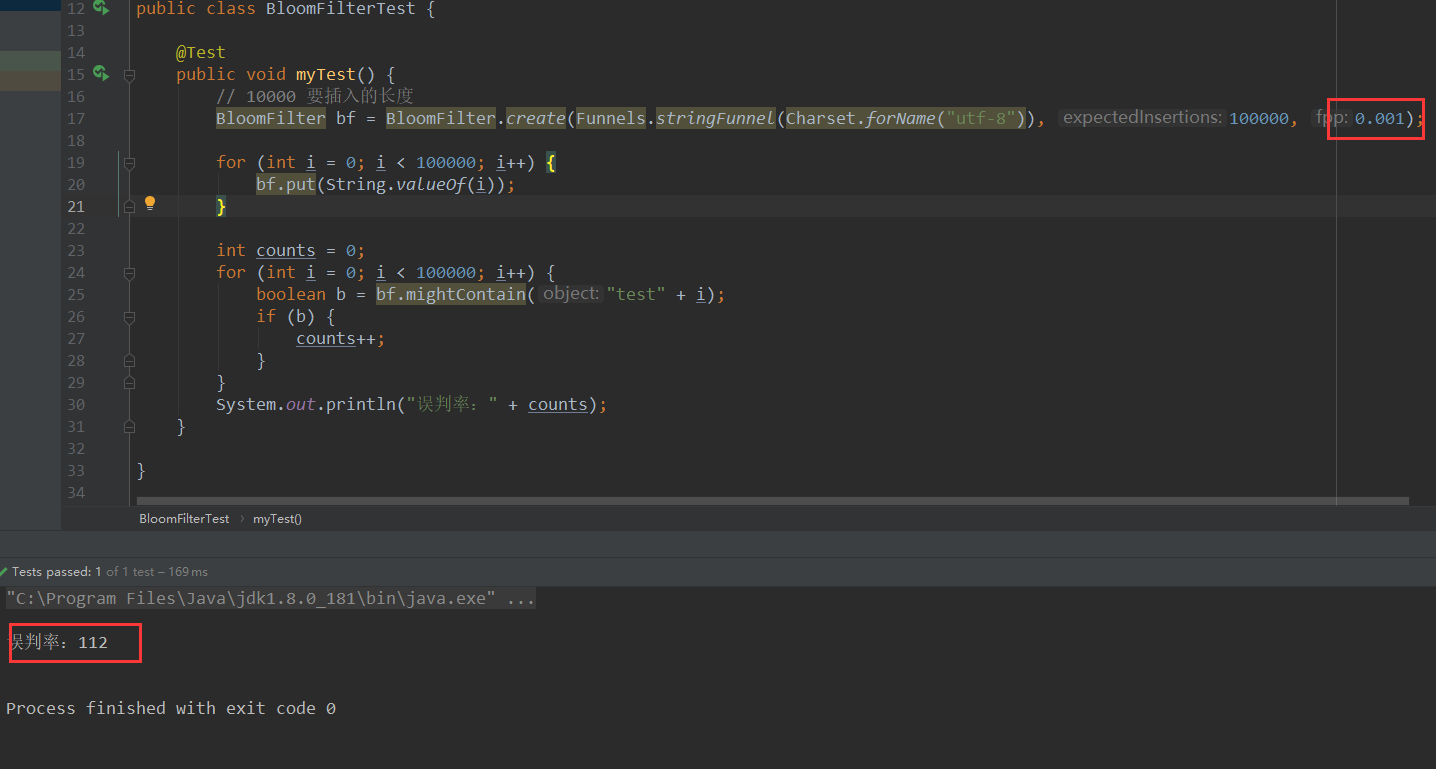
当我们设置 fpp 参数和 长度后,误判率降低了很多。
fpp:误报概率,必须要小于1.0
4、缓存雪崩和预防
1、什么是缓存雪崩
雪崩就是我们的 Key 在 Redis 里面,其实有很多的 Key ,一般有可能会设置一些过期的时间,过期时间一旦是有重合的某一个时间点,有一个时刻大面积的 Key 全部都失效了,但是又在这个时候有很大很大的一个流量涌入进来,这个时候所有的请求全部会打在数据库上,所以我们的请求不会经过 Redis 的,这样是就是缓存雪崩的问题。大面积的 Key 失效不能提供缓存服务,所以超大的流量全部打在数据库上,这时候数据库就会宕机崩溃。
2、雪崩预防
永不过期:验证码在缓存中可能3分钟1分钟就失效了,这个不会有什么问题的,这个是不会访问到数据库的。那么其他的一些可以设置成永不过期的。如果说你要让它过期,可以人为的让它过期。让被动过期转变为主动过期,永不过期就不会造成成片大面积 Key 失效的情况。
过期时间错开:有些系统在启动的时候会初始化缓存的,在初始化缓存的时候会有很多,如果有过期时间的话肯定是有重复的,所以采取时间错峰的概念。
多缓存结合:现在系统都是 Reis 缓存,如果说要预防雪崩可以再去结合一些其他缓存比如说 memcache,这样子两个缓存结合在一起预防这样一个问题。首先请求过来的时候,它会先查询 Redis ,Redis没有就再去查询 memcache,如果有就返回,没有就查询数据库,这样的情况的话 memcache 设置的过期时间是要比 Redis 久一些。
购买第三方 Redis:比如阿里产品

