并发编程
操作系统发展史
手工操作-穿孔卡片--->批处理-磁带存储--->联机批处理系统--->脱机批处理系统
手工操作-穿孔卡片

刚开始的计算机工作还在采用手工操作方式,刚开始的计算机是一个人一个人进去使用,同一时间机房只能有一个人操作,对等待的程序员非常不友好,
程序员等待操作人员操作完毕,才让下一个用户上机。
程序员将对应于程序和数据的穿孔的卡片装入输入机,然后启动输入机把程序和数据输入计算机内存,接着通过控制台开关启动程序针对数据运行;
计算完毕,打印机输出计算结果;用户取走结果并卸下穿孔卡片后,才让下一个用户上机,cpu真正工作的时间非常短,cpu利用率非常低
批处理-磁带存储
批处理系统:加载在计算机上的一个系统软件,在它的控制下,计算机能够自动地、成批地处理一个或多个用户的作业(这作业包括程序、数据和命令)。
联机批处理系统
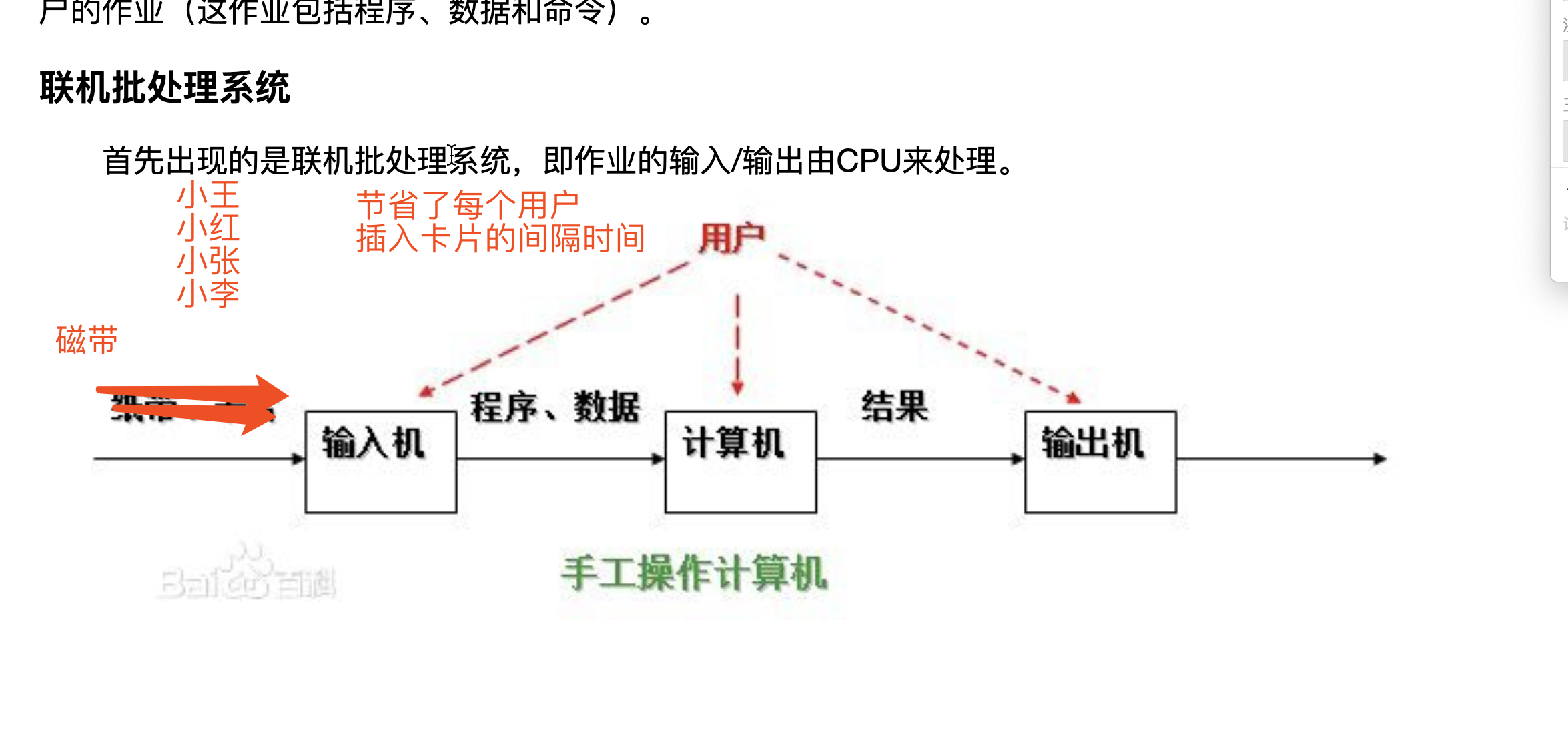
主机与输入机之间增加一个存储设备——磁带,计算机的监督程序可以将输入机的作业保存到磁带上,控制计算机自动工作,计算机可以成批地把输入机上的用户作业读入磁带,
再依次将磁带的数据读入内存并将处理结果返回给输出机,虽然提高了计算机的工作效率,但是在输入和输出的时候,cpu还是在空闲状态
脱机批处理系统(输入/输出脱离主机控制。)
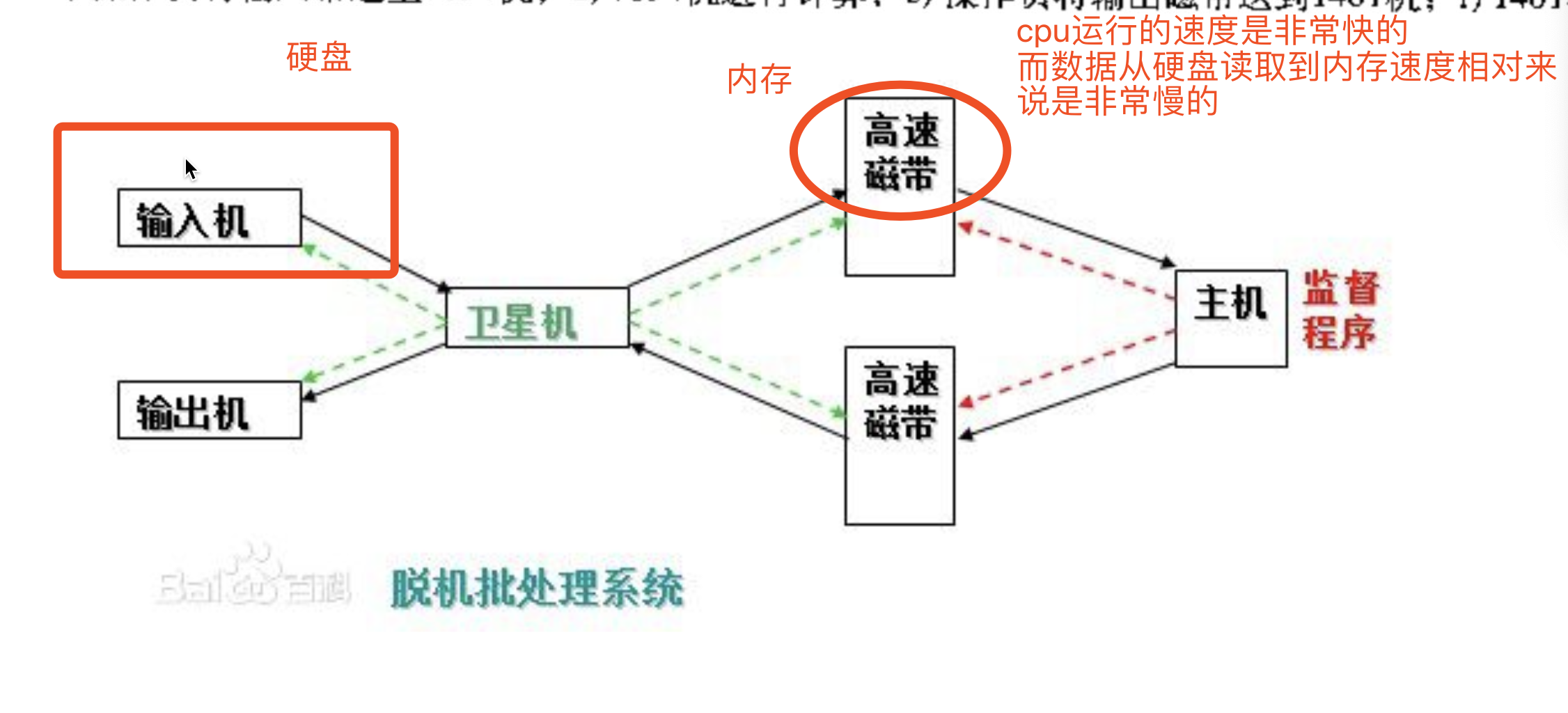
加入了卫星机:
卫星机:一台不与主机直接相连而专门用于与输入/输出设备打交道的。
功能是:
(1)从输入机上读取用户作业并放到输入磁带上。
(2)从输出磁带上读取执行结果并传给输出机。
因为输入机与输出机速度太慢,所以卫星机与速度较快的磁带机打交道(高速磁带,卫星机相当于媒介),有效缓解了主机与设备的矛盾,主机与卫星机可并行工作。提高了主机的工作效率
多道技术
所谓多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,
它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。
空间上的复用与时间上的复用
空间上的复用:多个程序公用一套计算机硬件
时间上的复用:切换+保存状态(单道需要先干完一件事,再去干另一件事;而多道,则是再干一件事的途中去干另一件事,例如:煮饭的途中去拖地,节省时间)
切换(CPU)分为两种情况
1.当一个程序遇到IO操作的时候,操作系统会剥夺该程序的CPU执行权限
作用:提高了CPU的利用率 并且也不影响程序的执行效率
2.当一个程序长时间占用CPU的时候,操作吸引也会剥夺该程序的CPU执行权限
弊端:降低了程序的执行效率(原本时间+切换时间)
进程
程序与进程的区别
程序就是一堆躺在硬盘上的代码,是“死”的
进程则表示程序正在执行的过程,是“活”的
进程调度:
先来先服务调度算法:对长作业有利,对短作业无益
短作业优先调度算法:对短作业有利,对长作业无益
时间片轮转法+多级反馈队列
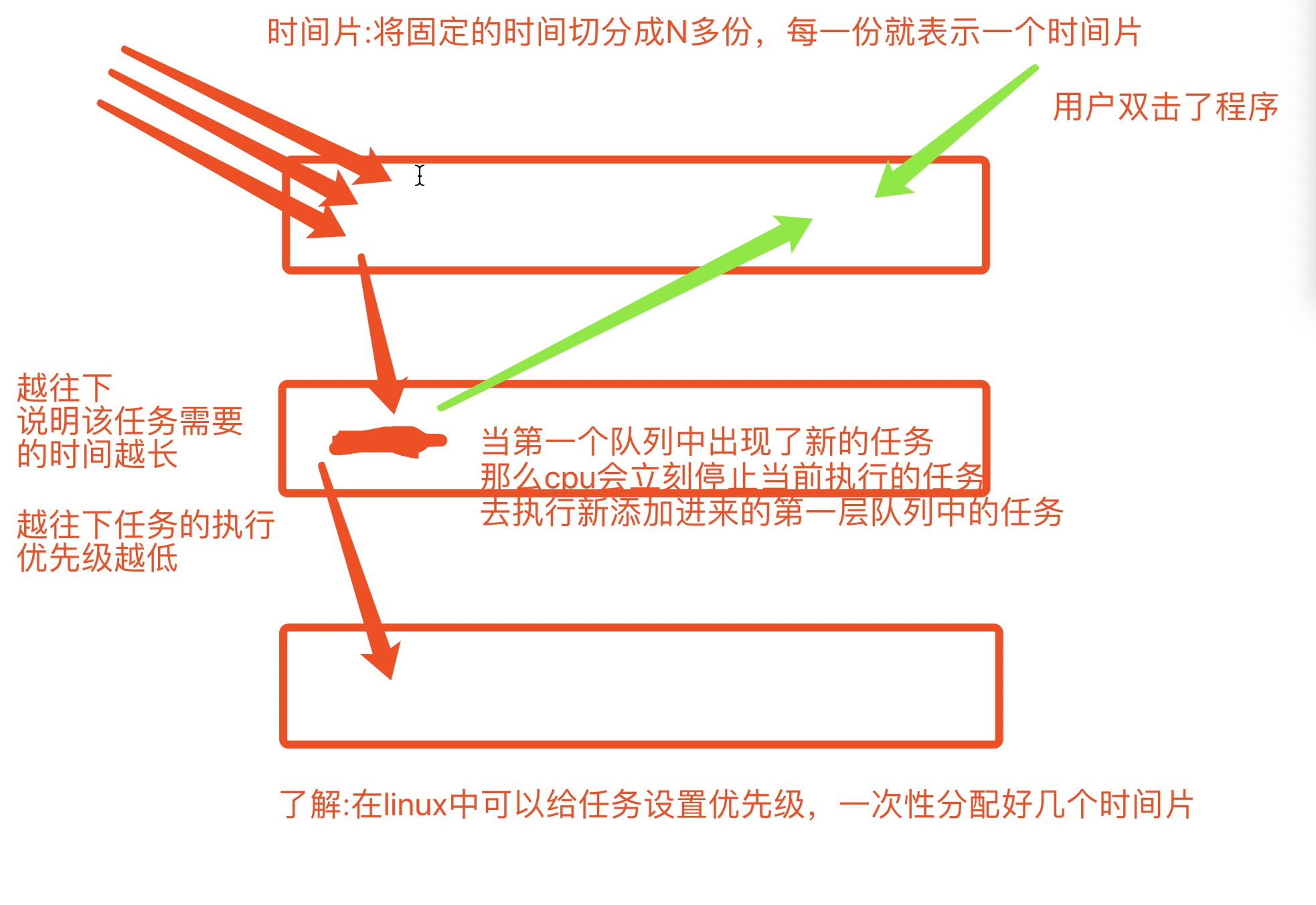
把处理机的运行时间分成很短的时间片,如果进程在该时间片内没有运行完毕,就暂停,进入下一个时间片,等下一轮再继续运行,
如果该进程在第二个时间片,第一时间片的队列中出现新的任务,cpu就会停止该进程的执行,去执行新添加的第一层队列的任务
越往下说明进程执行时间越长,执行优先级也就越低
进程运行的三状态图
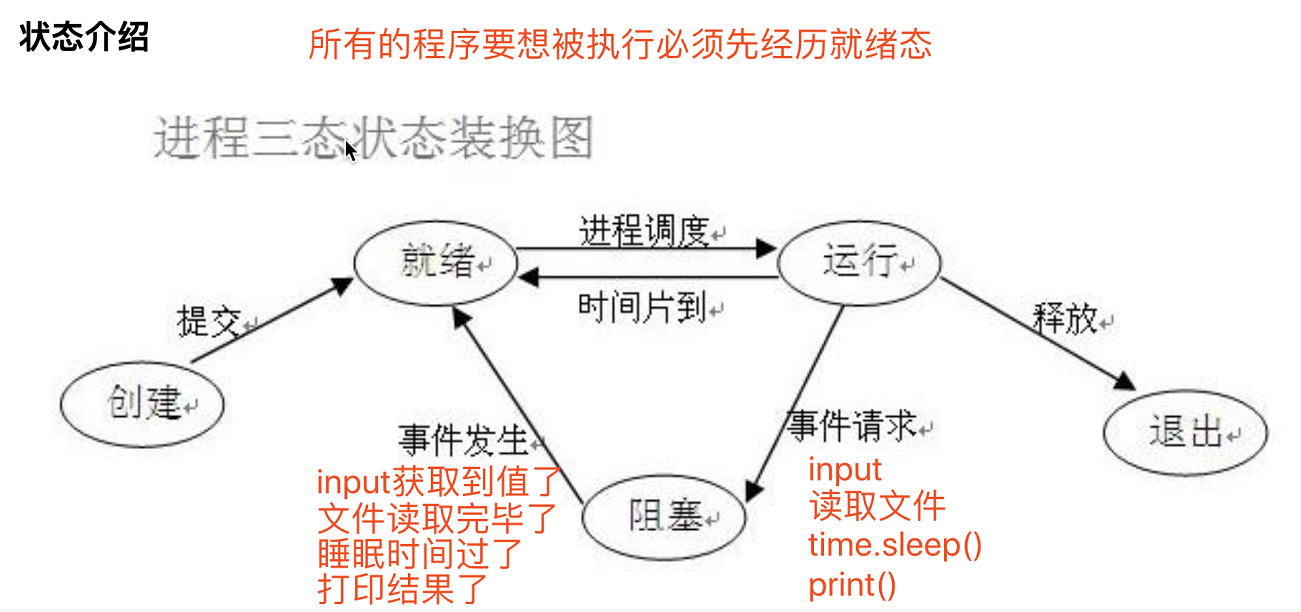
进程两对重要概念
* **同步和异步**
"""描述的是任务的提交方式"""
同步:任务提交之后,原地等待任务的返回结果,等待的过程中不做任何事(干等)
程序层面上表现出来的感觉就是卡住了
异步:任务提交之后,不原地等待任务的返回结果,直接去做其他事情
我提交的任务结果如何获取?
任务的返回结果会有一个异步回调机制自动处理
* **阻塞非阻塞**
"""描述的程序的运行状态"""
阻塞:阻塞态
非阻塞:就绪态、运行态
理想状态:我们应该让我们的写的代码永远处于就绪态和运行态之间切换
上述概念的组合:最高效的一种组合就是**异步非阻塞**
开启进程的两种方式:
第一种:
from multiprocessing import Process
import time
def task(name):
print('%s开始执行' % name)
time.sleep(3)
print('%s执行完毕' % name)
if __name__ == '__main__':
p = Process(target=task,args=('egon',))
p.start()
print('主进程执行完毕')
第二种:
类的继承
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print('%s开始执行' % self.name)
time.sleep(3)
print('%s执行完毕' % self.name)
if __name__ == '__main__':
p = MyProcess('egon')
p.start()
print('主进程执行完毕')
join方法:
join是让主进程等待子进程代码运行结束之后,再继续运行。不影响其他子进程的执行
from multiprocessing import Process
import time
def task(name, n):
print('%s is running'%name)
time.sleep(n)
print('%s is over'%name)
if __name__ == '__main__':
# p1 = Process(target=task, args=('jason', 1))
# p2 = Process(target=task, args=('egon', 2))
# p3 = Process(target=task, args=('tank', 3))
# start_time = time.time()
# p1.start()
# p2.start()
# p3.start() # 仅仅是告诉操作系统要创建进程
# # time.sleep(50000000000000000000)
# # p.join() # 主进程等待子进程p运行结束之后再继续往后执行
# p1.join()
# p2.join()
# p3.join()
start_time = time.time()
p_list = []
for i in range(1, 4):
p = Process(target=task, args=('子进程%s'%i, i))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('主', time.time() - start_time)
进程之间数据相互隔离
from multiprocessing import Process
money = 100
def task():
global money # 局部修改全局
money = 666
print('子',money)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print(money)
总结:
创建进程就是在内存中申请一块内存空间将需要运行的代码丢进去
一个进程对应在内存中就是一块独立的内存空间
多个进程对应在内存中就是多块独立的内存空间
进程与进程之间数据默认情况下是无法直接交互,如果想交互可以借助于第三方工具、模块

 浙公网安备 33010602011771号
浙公网安备 33010602011771号