

一些编码有关的HTTP报头
一些编码有关的HTTP报头
Transfer-Encoding
Transfer-Encoding只有一个取值那就是chunked,如果赋值了的话那就表示分块编码传输, Content-Length不确定,会在块尾
在早年间的设计里,和内容编码使用 Accept-Encoding来标记客户端接收的压缩编码类型一样,传输编码还需要配合 TE 这个请求报文头来使用,用于指定支持的传输编码。但是在最新的 HTTP/1.1 协议规范中,只定义了一种传输编码:分块编码(chunked),所以并不需要再依赖 TE 这个头部。
我们知道 HTTP 协议是建立在 TCP 协议之上的,自然有 TCP 一样的三次握手、慢启动等特性,这样每一次连接其实都是一次宝贵的资源。为了尽可能的提高 HTTP 的性能,使用持久连接就显得很重要了。为此在 HTTP 协议中,就引入了相关的机制。
在早期的 HTTP/1.0 协议中并没有持久连接,持久连接的概念是在后期才引入的,当时是通过 Connection:Keep-Alive 这个头部来标记实现,用于通知客户端或服务端相对的另一端,在发送完数据之后,不要断开 TCP 连接,之后还需要再次使用。
而在 HTTP/1.1 协议中,发现持久连接的重要性了,它规定所有的连接必须都是持久的,除非显式的在报文头里,通过 Connection:close 这个首部,指定在传输结束之后会关闭此连接。
实际上在 HTTP/1.1 中Connect 这个头部已经没有 Keep-Alive 这个取值了,由于历史原因,很多客户端和服务端,依然保留了这个报文头。长连接带来了另外一个问题,如何判定当前数据发送完成。
分块传输的规则:
1. 每个分块包含一个 16 进制的数据长度值和真实数据。
2. 数据长度值独占一行,和真实数据通过 CRLF(\r\n) 分割。
3. 数据长度值,不计算真实数据末尾的 CRLF,只计算当前传输块的数据长度。
4. 最后通过一个数据长度值为 0 的分块,来标记当前内容实体传输结束。
chunked 的拖挂
当我们使用 chunked 进行分块编码传输的时候,传输结束之后,还有机会在分块报文的末尾,再追加一段数据,此数据称为拖挂(Trailer)。拖挂的数据,可以是服务端在末尾需要传递的数据,客户端其实是可以忽略并丢弃拖挂的内容的,这就需要双方协商好传输的内容了。
在拖挂中可以包含附带的首部字段,除了 Transfer-Encoding、Trailer 以及 Content-Length 首部之外,其他 HTTP 首部都可以作为拖挂发送。一般我们会使用拖挂来传递一些在响应报文开始的时候,无法确定的某些值,例如:Content-MD5 首部就是一个常见的在拖挂中追加发送的首部。和长度一样,对于需要分块编码传输的内容实体,在开始响应的时候,我们也很难算出它的 MD5 值, 如果有多个拖挂的数据,可以使用逗号进行分割。
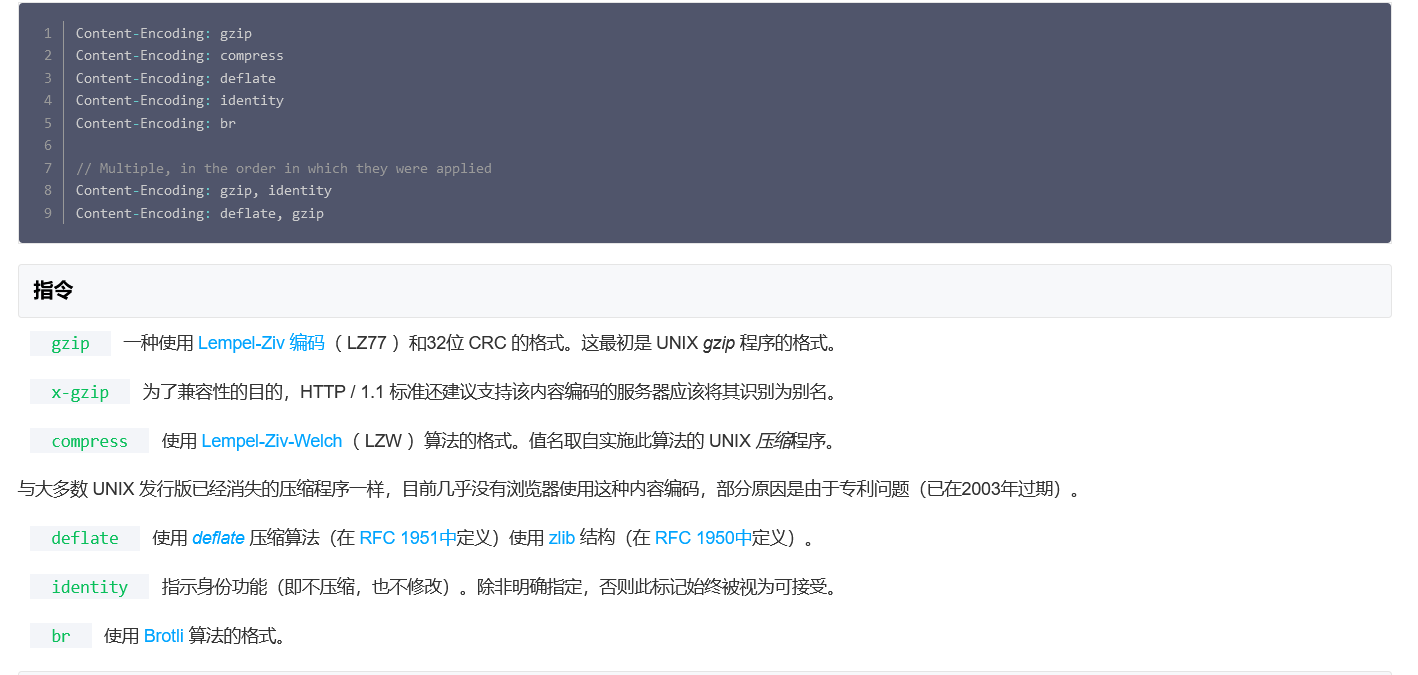
内容编码和传输编码一般都是配合使用的。我们会先使用内容编码,将内容实体进行压缩,然后再通过传输编码分块发送出去。客户端接收到分块的数据,再将数据进行重新整合,还原成最初的数据。此外,传输编码应该是所有 HTTP/1.1 的标准实现,应该都有支持,如果收到无法理解的经过传输编码的报文,应该直接返回 501 Unimplemented 这个状态码来回复即可。
另外再说一下http内容编码和传输编码:
-
https是最外层编码,指出是否应当加密。 -
Transfer-Encoding: chunked是第 2 层编码,指出是否Content-Length不能预知,而采取分块传输,如果结束了会在尾块中告知。 -
Content-Encoding: gzip是第 3 层编码,指出内容是否经过压缩、是否需要解压。 -
Content-Type: text/html; charset=utf-8是最内层编码,告知文件是 Unicode 字符集的UTF-8编码的 HTML 代码,需要用UTF-8码表将1010机器码换算为字符后,再按照 HTML 编程语言来解读和渲染它。当然它也可以是
Content-Type: application/x-gzip,但与第 3 层的区别是,第 3 层的Content-Encoding: gzip压缩表示交给前端时应当不透明地自动解压,前端需要的是没压缩前的东西,而最内层Content-Type: application/x-gzip的意思是,所获取的内容本身就是一个.gz文件。
Content-Encoding: gzip


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!