
Pod生命周期和健康检查
Pod生命周期和健康检查
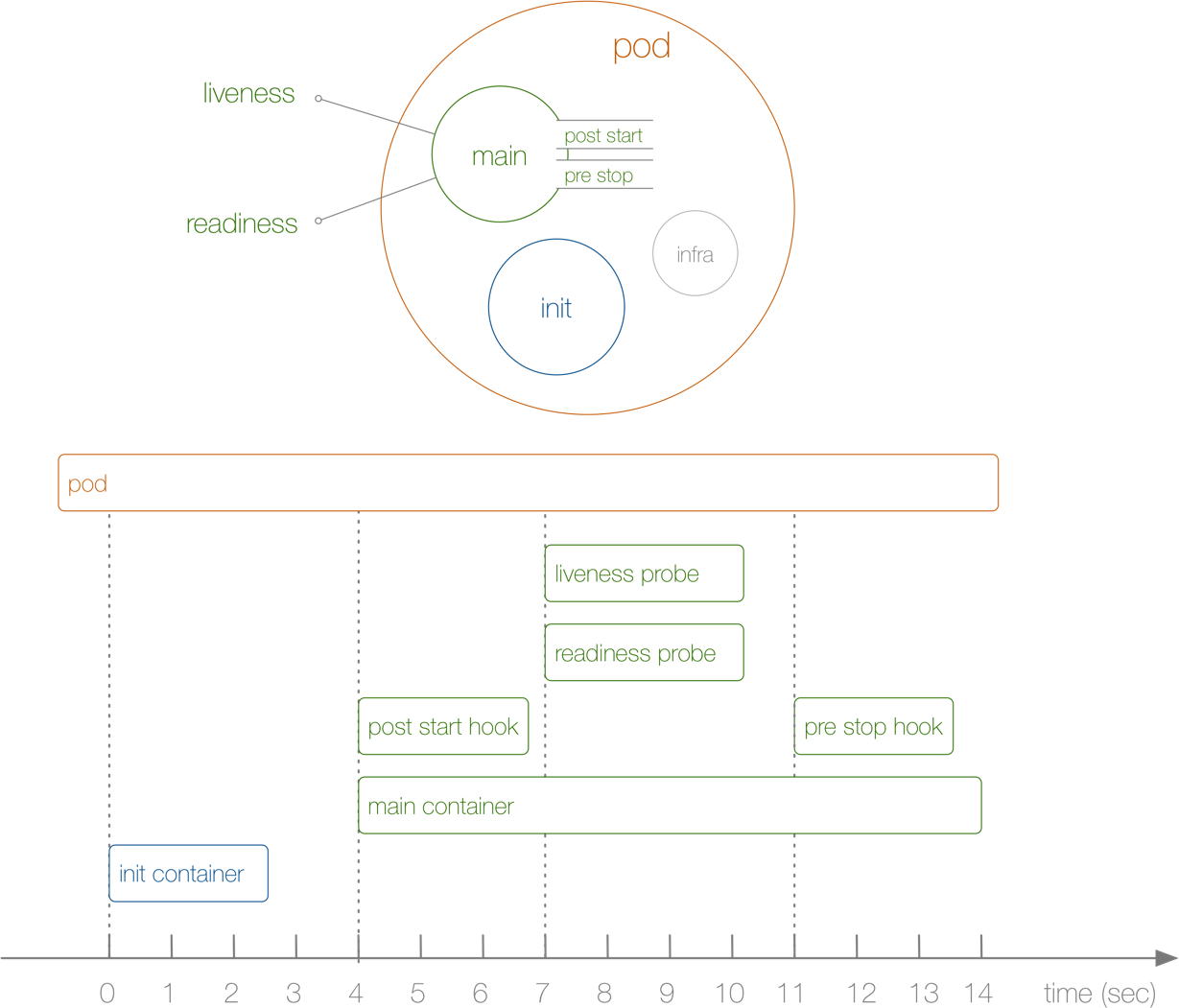
Pod的生命周期涵盖了前面所说的PostStart 和 PreStop在内
Pod phase
Pod的status定义在 PodStatus对象中,其中有一个phase字段。
Pod的运行阶段是Pod在其生命周期中的简单宏观概述。
下面是phase可能的值:
- Pending 挂起:该状态标识Pod没有调度到节点上,可能下载镜像耗费时间,容器还未启动。
- Running 运行中: Pod已经绑定到一个节点上,Pod中的容器已经全部创建,至少有一个容器正在运行,或者证处于启动状态或重启状态。
- Succeeded 成功: Pod中所有的容器都被成功终止,并且不会被重启。
- Failed 失败:Pod中的所有容器都已经终止了,并且至少有一个容器是因为失败终止。容器退出状态非0或被系统终止。
- Unknown 未知: 因为某些原因无法取得Pod状态,通常因为与Pod所在节点失去通信造成失联。
Pod 状态
Pod 有一个 PodStatus 对象,其中包含一个 PodCondition 数组。 PodCondition 数组的每个元素都有一个 type 字段和一个 status 字段。type 字段是字符串,可能的值有 PodScheduled、Ready、Initialized 和 Unschedulable。status 字段是一个字符串,可能的值有 True、False 和 Unknown。
Pod健康检查
查看官网文档,探针是有kubelet对容器状态的一种定期监控和检查,要执行诊断,kubelet可以调用由容器实现的Handler。有三种执行方式:
- HTTPGetAction(http):对指定端口和路径上的容器的IP地址执行HTTP Get请求。如果状态码大于等于200且小于400,则认为诊断成功。
- ExecAction(exec): 在容器内部执行指定命令,执行后退出状态码为0则诊断成功。
- TCPSocketAction(tcp:): kubelet 对指定容器IP和Port进行TCP检查,如果端口打开,则被认为诊断成功
诊断状态有三种:
- 成功: 容器状态健康,通过了检测
- 失败: 容器未通过诊断
- 未知: 诊断失败,不会采取任何行动
容器探针
供kubelet对容器诊断的探针有两种:
- LivenessProbe: 存活探针,指容器是否正在运行。如果检测失败,则kubelet会杀死容器,并且容器会受重启策略的影响而是否重启, 如果容器不提供探针,则默认状态为success。
- ReadnessProbe: 就绪探针,指容器是否准备就绪,接受服务请求。如果就绪探针失败,端点控制器将从与Pod匹配的所有service的端点中移除该Pod的IP 地址。初始延迟之前的就绪状态默认是Failure,如果容器不提供就绪探针,则默认状态为Success。
什么时候选择livenessProbe 存活探针和readnessProbe就绪探针?
如果容器中的进程能够在出现服务故障的时候自动崩溃,那么这种时候是不需要提供livenessProbe ,kubelet将根据Pod的restartPolicy自动执行正确的操作
如果希望容器在探测失败时被杀死并重新启动,那么请指定一个livenessPRobe存活探针,并指定restartPolicy为Always或OnFailure。
如果要在探测成功才开始向Pod发送流量,就需要指定一个readnessProbe 。在这种情况下,就绪探针可能和存活探针同时存在,这种情况下的readnessProbe意味容器在没有接受到任何 流量的情况下启动,并且只有在探针成功后才接收流量。如果希望容器能够自行维护,那就指定一个readnessProbe探针,和livenessProbe探测不同的端点。
注意,如果只想在pod被删除时能够排除请求,则不一定需要使用就绪探针;在删除Pod时,Pod将自动将自身置于未完成状态,无论是否有就绪探针。当等待Pod中的容器停止时,Pod仍处于未完成状态。
模板 使用exec方式
apiVersion: v1
kind: Pod
metadata:
name: probe
spec:
containers:
- name: probe
image: busybox
argx:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5 #等待容器启动5秒后发起探针
periodSeconds: 5 #发起探针的间隔5秒一次
使用kubectl 部署这个yaml文件,创建一个Pod,可以发现在启动完成后等待5秒后开始发起探针诊断,每隔5秒后发起一次诊断,而这里使用的是exec方式,在30秒后容器会执行删除/tmp/healthy 文件操作,这之后再发起探针诊断则诊断失败,容器将被kubelet 杀掉然后重启。
livenessProbe和readnessProbe一起使用
apiVersion: v1
kind: Pod
metadata:
name: probe-http
label:
app: probe-http
sepc:
containers:
- name: probe-http
image: nginx
containerPort:
- name: http
port: 80
livenessProbe:
# 当没有定义 "host" 时,使用 "PodIP"
# host: my-host
# 当没有定义 "scheme" 时,使用 "HTTP" scheme 只允许 "HTTP" 和 "HTTPS"
# scheme: HTTPS
path: / #路径可以是想要检查的能访问到的任何路径,如:/healthy
port: 80
# httpHeaders: 设置http请求头
# - name: X-Custom-Header
# value: Awesome
initialDelaySeconds: 15
timeoutSeconds: 1 #超时时间
readnessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 20
从上面的YAML文件我们可以看出readiness probe的配置跟liveness probe很像,基本上一致的。唯一的不同是使用readinessProbe而不是livenessProbe。两者如果同时使用的话就可以确保流量不会到达还未准备好的容器,准备好过后,如果应用程序出现了错误,则会重新启动容器。
探针参数:
* timeoutSeconds:探测超时时间,默认1秒,最小1秒。
* successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是 1,但是如果是`liveness`则必须是 1。最小值是 1。
* failureThreshold:探测成功后,最少连续探测失败多少次才被认定为失败。默认是 3,最小值是 1。
重启策略
PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为 Always。 restartPolicy 适用于 Pod 中的所有容器。restartPolicy 仅指通过同一节点上的 kubelet 重新启动容器。失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒…)重新启动,并在成功执行十分钟后重置。如 Pod 文档 中所述,一旦绑定到一个节点,Pod 将永远不会重新绑定到另一个节点。
restartPolicy:
- Always 容器失效时,kubelet 自动重启该容器
- OnFailure 容器终止运行且退出码不为0时重启
- Never 不论状态为何, kubelet 都不重启该容器
Pod 的生命
一般来说,Pod 不会消失,直到人为销毁他们。这可能是一个人或控制器。这个规则的唯一例外是成功或失败的 phase 超过一段时间(由 master 确定)的Pod将过期并被自动销毁。
有三种可用的控制器:
- 使用 Job 运行预期会终止的 Pod,例如批量计算。Job 仅适用于重启策略为
OnFailure或Never的 Pod。 - 对预期不会终止的 Pod 使用 ReplicationController、ReplicaSet 和 Deployment ,例如 Web 服务器。 ReplicationController 仅适用于具有
restartPolicy为 Always 的 Pod。 - 提供特定于机器的系统服务,使用 DaemonSet 为每台机器运行一个 Pod 。
所有这三种类型的控制器都包含一个 PodTemplate。建议创建适当的控制器,让它们来创建 Pod,而不是直接自己创建 Pod。这是因为单独的 Pod 在机器故障的情况下没有办法自动复原,而控制器却可以。
如果节点死亡或与集群的其余部分断开连接,则 Kubernetes 将应用一个策略将丢失节点上的所有 Pod 的 phase 设置为 Failed
