
SQL查询效率(Oracle)
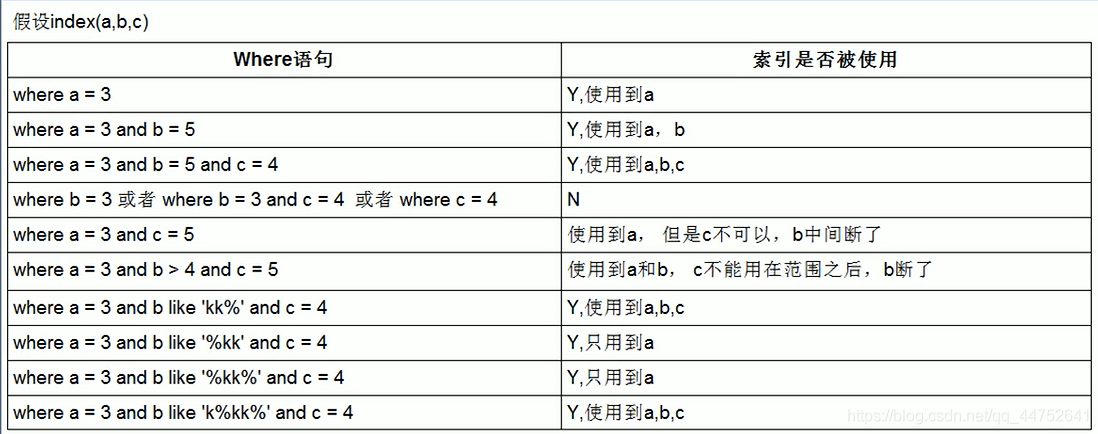
联合查询什么时候索引能用到
提高SQL查询效率
选择最优效率的表名顺序
1.Oracle的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表driving table)将被最先处理
2.在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表最为基础表。
3.如果有三个以上的表连接查询,那就需要选择交叉表(intersection table)作为基础表,交叉表是指那个被其它表所引用的表
WHERE子句中的连接顺序
1.Oracle采用自下而上的顺序解析WHERE子句
2.由上述原理推导,表之间的连接必须写在其他WHERE条件之前
3.那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾
SELECT子句避免使用*
Oracle在解析的过程中,会将"*"依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间
减少访问数据库的次数
Oracle在内部执行了许多工作,解析SQL语句,估算索引的利用率,绑定变量,读数据块等
能用一句SQL得到结果最好(要乐观)
考虑整合一些简单的数据库访问
使用DECODE函数来减少处理时间
使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表
删除重复记录
//高效的删除重复记录的方法(表示看不懂)
DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID) FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
用TRUNCATE替代DELETE
TRUNCATE属于DDL语句,不会在回滚段(rollback segments)存放可以被恢复的信息
注意!当你决心干掉一张表的所有数据时,再去考虑用它吧
合理的COMMIT
使用COMMIT后可以释放回滚段上用于恢复数据的信息,被程序语句获得的锁,redo log buffer中的空间以及Oracle为管理上述3中资源中的内部花费
用Where子句多于Having子句
避免使用Having子句,Having只会在检索出所有记录之后才对结果集进行过滤,这个处理需要排序,总计等操作
通过Where子句限制记录的数目,那就能减少这方面的开销
(非oracle中)on,where,having这三个都可以加条件的子句中,on是最先执行,where次之,having最后,因为on是先把把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按道理说速度是最快的
where应该比having快点的,因为它过滤数据后才进行sum
在两个表连接时采用on的,所以一个表的时候,就剩下where跟having比较了
Where和Having比较
在单表查询统计的情况下,如果要过滤的条件没有涉及的到要计算的字段,那么它们的结果是一样的
只是where可以使用rushmore技术,而having就不能。在速度上后者要慢。涉及的要计算的字段,where的作用时间是在计算之前完成的,而having就是在计算后才起作用的
多表联接查询时,on比where更早起作用,系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where进行过滤,然后再计算,计算完后由having过滤
明白各个条件限制关键词在什么时候起作用,然后再决定放在那里
考虑内部函数
复杂的SQL往往牺牲了执行效率,能够掌握上面的运用SQL函数解决问题的方法实际工作中是非常有意义的
使用表的别名
当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个Colunm上,这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误
EXISTS的使用
//高效
SELECT * FROM EMP WHERE EMPNO > 0 AND EXISTS (SELECTDEPTNO FROM DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO AND LOC = 'MELB'
//低效
SELECT * FROM EMP WHERE EMPNO > 0 AND DEPTNO IN(SELECT DEPTNO FROM DEPT WHERE LOC = 'MELB'
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联结。在这种情况下EXISTS(或NOT EXISTS)通常将提高查询效率
在子查询中,NOT IN子句将执行一个内部的排序和合并,无论那种情况下NOT IN都是最低效的(因为它对子查询中的表执行了一个全表遍历)
为了避免使用NOT IN,我们可以把它改写成外连接(Outer Joins)或者NOT EXISTS
利用索引
索引是表的一个概念部分,用来提高检索数据的效率。Oracle使用了一个复杂的自平衡B-tree结构。通常通过索引查询数据比全表扫描要快。
当Oracle找出执行查询和Update语句的最佳路径时,Oracle优化器将使用索引,同样在联结多个表时使用索引也可以提高效率
使用索引的另一个好处是它提供了主键的唯一性验证。(那些LONG或LONG RAW数据类型,你几乎可以索引所有列)。通常,在大型表中使用索引特别有效,当然你也会发现在使用小表时,使用索引同样能提高效率
索引能使查询效率得到提高,但是我们也必须注意到它的代价。索引需要空间来存储,也需要定时维护,每当有记录在表中增减或索引列被修改时,索引本身也会被修改。这意味着每条记录的INSERT,DELTE,UPDATE将为此多付出4,5次的磁盘I/O
因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢,定期重构索引是有必要的
ALTER INDEX <INDEXNAME> REBUILD <TABLESPACENAME>
大写SQL
Oracle总是先解析SQL语句,把小写的字母转换成大写的再执行
索引列使用原则
避免在索引列上使用NOT,NOT会产生在和在索引列上使用函数相同的影响
当Oracle遇到"NOT"时,他就会停止使用索引转而执行全表扫描
避免在索引列上使用计算。WHERE子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描
低效:SELECT ... FROM DEPT WHERE SAL*12 >25000
高效:SELECT ... FROM DEPT WHERE SAL > 25000/12
用大于等于替代大于
SELECT * FROM EMP WHERE DEPTNO > =4 //高效
SELECT * FROM EMP WHERE DEPTNO > 3 //低效
两者的区别在于,前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3并且向前扫描到第一个大于3的记录
适用于索引列的UNION替换OR
SELECT LOC_ID,LOG_DESC,REGION FROM LOCAITON WHERE LOC_ID=10 UNION SELECT LOC_ID,LOC_DESC,REGION FROM LOCATION WHERE REGION = 'MELBOURNE'//高效
SELECT LOC_ID,LOC_DESC,REGION FROM LOCATION WHERE LOC_ID= 10 OR REGION = 'MELBURNE' //低效
通常情况下,用UNION替换WHERE子句中的OR将会起到较好的效果
对索引列使用OR将造成全表扫描
以上规则只针对多个索引列有效,如果有column没有被索引,查询效率可能会因为你没有选择OR而降低
上面例子中,LOC_ID和REGION上面都建有索引
避免在索引列上使用IS NULL和IS NOT NULL
SELECT ... FROM DEPARTMENT WHERE DEPT_CODE IS NOT NULL //低效,索引失败
SELECT .. FROM DEPARTMENT WHERE DEPT_CODE > = 0 //高效,索引有效
避免在索引中使用任何可以为空的列,Oracle将无法使用该索引
对于单列索引,如果列包含空值,索引中将不存在此记录
对于复合索引,如果每个列都为空,索引中同样不存在此记录。如果至少有要一个列不为空,则记录存在于索引中
总是使用索引的第一个列
如果索引总是建立在多个列上,只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引
当仅引用索引的第二个列时,优化器使用了全表扫描而忽略了索引
如果可以,用UNION-ALL替换UNION
当SQL语句需要UNION两个查询结果集合时,这两个结果集合会以UNION-ALL的方式被合并,然后在输出最终结果前进行排序
如果用UNION ALL替代UNION,这样排序就不是必要的了,效率就会因此得到提高。
需要注意的是,UNION ALL将重复输出两个结果集合中相同记录,因此各位还是要从业务需求分析使用UNION ALL的可行性
UNION将对结果结合排序,这个操作会使用到SORT_AREA_SIZE这块内存,对于这块内存的优化也是相当重要的。
用WHERE替代ORDER BY
ORDER BY子句只在两种两种严格的条件下使用索引//a.ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序//b.ORDER BY中所有的列必须定义为非空
WHERE子句使用的索引和ORDER BY子句中使用的索引不能并列
以表DEPT为例子
表DEPT包含以下列:
=============
DEPT_CODE PK NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL
=============
SELECT DEPT_CODE FROM DEPT ORDER BY DEPT_TYPE //低效,索引未使用
SELECT DEPT_CODE FROM DEPT WHERE DEPT_TYPE > 0 //高效,索引已经使用
避免改变索引列的类型
当比较不同类型的数据时,ORACLE自动对列进行简单的类型转换,例如:EMPNO是一个数值类型的索引列:SELECT ... FROM EMP WHERE EMPNO = '123'。实际上,经过ORACLE类型转化为:SELECT ... FROM EMP WHERE EMPNO =TO_NUMBER('123')
需要当心的WHERE子句
'!='将不适用索引,记住,索引只能告诉你什么存在于表中,而不能告诉你什么不存在于表中
‘||’是字符连接函数,就像其他函数那样,停用了索引
‘+’是数字函数,就像其他数学函数那样,停用了索引
相同的索引列不能互相比较,这将会启用全表扫描
避免使用耗费资源的操作
带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎执行耗费资源的排序(SORT)功能
DISTINCT需要一次排序操作,而其他的至少需要执行两次排序。通常,带有 UNION, MINUS , INTERSECT的SQL语句都可以用其他方式重写
如果你的数据库的SORT_AREA_SIZE调配得好。使用UNION , MINUS, INTERSECT也是可以考虑的, 毕竟它们的可读性很强
优化GROUP BY
低效: SELECT JOB , AVG(SAL) FROM EMP GROUP BY JOB HAVING JOB = ‘PRESIDENT' OR JOB =‘MANAGER'
高效: SELECT JOB , AVG(SAL) FROM EMP WHERE JOB = ‘PRESIDENT'OR JOB = ‘MANAGER' GROUP BY JOB
提高GROUP BY 语句的效率,可以通过将不需要的记录在GROUP BY 之前过滤掉。下面两个查询返回相同结果但第二个明显就快了许多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号