
Oracle数据库的函数,存储过程,程序包,游标,触发器
Oracle自定义函数
函数的主要特性是它必须返回一个值。创建函数时通过 RETURN 子句指定函数返回值的数据类型。
函数的一些限制:
● 函数只能带有 IN 参数,不能带有 IN OUT 或 OUT 参数。
● 形式参数必须只使用数据库类型,不能使用 PL/SQL 类型。
● 函数的返回类型必须是数据库类型
Create function 函数名称 return 返回值类型 as
Begin
····
End 函数名称;
--创建不带参数函数,返回t_book中书的数量 create function getBookCount return number as begin declare book_count number; begin select count(*) into book_count from t_book; return book_count; end; end getBookCount; --函数调用 set serveroutput on; begin dbms_output.put_line('表t_book中有'||getBookCount()||'本书'); end;
--创建带参数函数,查找某个表的记录数 create function getTableCount(table_name varchar2) return number as begin declare recore_count number; query_sql varchar2(300);--定义sql语句 begin query_sql:='select count(*) from '||table_name; --execute immediate:立即执行该SQL语句 execute immediate query_sql into recore_count; return recore_count; end; end getTableCount; --函数调用 set serveroutput on; begin dbms_output.put_line('表中有'||getTableCount('t_book_log')||'条数据'); end;
CREATE OR REPLACE FUNCTION item_price_rage (price NUMBER)
/* 参数、指定返回类型 */
RETURN varchar2
AS
/* 定义局部变量 */
min_price NUMBER;
max_price NUMBER;
BEGIN
SELECT MAX(ITEMRATE), MIN(ITEMRATE) INTO max_price, min_price
FROM itemfile;
IF price >= min_price AND price <= max_price THEN
RETURN '输入的单价介于最低价与最高价之间';
ELSE
RETURN '超出范围';
END IF;
END;
匿名块执行函数 p NUMBER := 300; MSG varchar2(200); BEGIN MSG := item_price_range(p); DBMS_OUTPUT.PUT_LINE(MSG); END;
SELECT查询调用(因为函数必须有返回值)
SELECT myfunction FROM dual;
Oracle存储过程
存储过程(Stored Procedure),就是一组用于完成特定数据库功能的SQL语句集,该SQL语句集经过编译后存储在数据库系统中。
在使用时候,用户通过指定已经定义的存储过程名字并给出相应的存储过程参数来调用并执行它,从而完成一个或一系列的数据库操作
Oracle存储过程包含三部分:过程声明,执行过程部分,存储过程异常
存储过程创建语法
create [or replace] procedure 存储过程名(param1 in type,param2 out type) as 变量1 类型(值范围); 变量2 类型(值范围); Begin Select count(*) into 变量1 from 表A where列名=param1; If (判断条件) then Select 列名 into 变量2 from 表A where列名=param1; Dbms_output.Put_line(‘打印信息’); Elsif (判断条件) then Dbms_output.Put_line(‘打印信息’); Else Raise 异常名(NO_DATA_FOUND); End if; Exception When others then Rollback; End;
declare 顾名思义就是描述的意思就是在这个下边可以对变量进行声明。
声明变量有大概如下两三种方式
1. v_temp varchar(10)
2.v_temp tablename.property%type(表明属性名%type就是该表属性的类型,这样可以灵活使用)
3.v_stu student%rowtype;(这种类型就是定义一个变量为表数据的行类型用于接受查询的一行数据,注意是一行数据)
-- Created on 2018/9/9 by LENOVO --声明变量,声明一个人的姓名,薪水,地址 declare -- Local variables here --姓名 v_name varchar2(50) :='张三丰'; --薪水 /* v_salary number(6,2);*/ v_salary emp.ename%type; --地址 v_address varchar2(100); v_stu student%rowtype; begin -- Test statements here --dbms_output.put_line('hello world'); v_salary:=1500; --语句赋值操作。
plsql中的复制是:=而不是单个=,单个=是判断是否相等意思
输出操作语句 dbms_output.put_line()
-- Created on 2018/9/9 by LENOVO --声明变量,声明一个人的姓名 declare -- Local variables here --姓名 v_name varchar2(50) '; begin v_name:=:='张三丰; dbms_output.put_line('姓名---〉'||v_name); end;
循环:loop关键词就是循环的意思,不论大家学习哪门语言都会发现循环的特点就是有入口,有出口(不可能让其死循环)。
declare vcc number; begin vcc:=1; loop exit when vcc>10; dbms_output.put_line(vcc); vcc:=vcc+1; end loop; end;
基本结构
CREATE OR REPLACE PROCEDURE 存储过程名字 ( 参数1 IN NUMBER, 参数2 IN NUMBER ) IS 变量1 INTEGER :=0; 变量2 DATE; BEGIN --执行体 END 存储过程名字;
SELECT INTO STATEMENT
将select查询的结果存入到变量中,可以同时将多个列存储多个变量中,必须有一条记录,否则抛出异常(如果没有记录抛出NO_DATA_FOUND)
例子:
BEGIN
SELECT col1,col2 into 变量1,变量2 FROM typestruct where xxx;
EXCEPTION
WHEN NO_DATA_FOUND THEN
xxxx;
END;
IF 判断
IF V_TEST = 1 THEN BEGIN do something END; END IF;
while 循环
WHILE V_TEST=1 LOOP
BEGIN
XXXX
END;
END LOOP;
变量赋值
V_TEST := 123;
在Oracle中对存储过程的调用
过程调用方式一
declare realsal emp.sal%type; realname varchar(40); realjob varchar(40); begin //过程调用开始 realsal:=1100; realname:=''; realjob:='CLERK'; runbyparmeters(realsal,realname,realjob);--必须按顺序 DBMS_OUTPUT.PUT_LINE(REALNAME||' '||REALJOB); END; //过程调用结束
过程调用方式二
declare realsal emp.sal%type; realname varchar(40); realjob varchar(40); begin //过程调用开始 realsal:=1100; realname:=''; realjob:='CLERK'; --指定值对应变量顺序可变 runbyparmeters(sname=>realname,isal=>realsal,sjob=>realjob); DBMS_OUTPUT.PUT_LINE(REALNAME||' '||REALJOB); END; //过程调用结束
过程调用方式三(SQL命令行方式下)
1、SQL>exec proc_emp(‘参数1’,’参数2’);//无返回值过程调用
2、SQL>var vsal number
SQL> exec proc_emp (‘参数1’,:vsal);// 有返回值过程调用
或者:call proc_emp (‘参数1’,:vsal);// 有返回值过程调用
(1)无参存储过程语法
create or replace procedure NoParPro as //声明 ; begin // 执行 ; exception//存储过程异常 ; end;
(2)带参存储过程实例
create or replace procedure queryempname(sfindno emp.empno%type) as sName emp.ename%type; sjob emp.job%type; begin .... exception .... end;
(3)带参数存储过程含赋值方式
create or replace procedure runbyparmeters (isal in emp.sal%type, sname out varchar, sjob in out varchar) as icount number; begin select count(*) into icount from emp where sal>isal and job=sjob; if icount=1 then .... else .... end if; exception when too_many_rows then DBMS_OUTPUT.PUT_LINE('返回值多于1行'); when others then DBMS_OUTPUT.PUT_LINE('在RUNBYPARMETERS过程中出错!'); end;
其中参数IN表示输入参数,是参数的默认模式。
OUT表示返回值参数,类型可以使用任意Oracle中的合法类型。
OUT模式定义的参数只能在过程体内部赋值,表示该参数可以将某个值传递回调用他的过程
IN OUT表示该参数可以向该过程中传递值,也可以将某个值传出去。
Create procedure 存储过程名称 as
Begin
···
End 存储过程名称;
In 只进不出
Out 只出不进
In out 可进可出
--创建存储过程,在t_book表中插入数据,且判断插入的数据是否已经存在 create procedure addBook(bName in varchar2,typeid in number) as begin declare maxId number; n number; begin select count(*) into n from t_book where t_book.bookname=bName; if(n>0) then return; end if; select max(id) into maxId from t_book; insert into t_book values(maxId+1,bName,typeid); commit; end; end addBook; --调用存储过程 execute addBook('vs',1);
--创建存储过程,在t_book表中插入数据,输出插入前后数据条数 create procedure addBook(bName in varchar2,typeid in number,n1 out number,n2 out number) as begin declare maxId number; n number; begin --n1存储执行前数据条数 select count(*) into n1 from t_book; select count(*) into n from t_book where t_book.bookname=bName; if(n>0) then select count(*) into n2 from t_book; return; end if; select max(id) into maxId from t_book; insert into t_book values(maxId+1,bName,typeid); --n2存储执行后数据条数 select count(*) into n2 from t_book; commit; end; end addBook; --返回存储执行前后数据条数 declare n1 number; n2 number; begin addBook('c+++',1,n1,n2); dbms_output.put_line('n1='||n1||',n2='||n2); end;
CREATE OR REPLACE PROCEDURE test (value IN varchar2, value2 OUT NUMBER)
/* 参数,不需指定长度或精度 */
IS
/* 局部变量,省略 DECLARE 关键字,需有长度 */
identity NUMBER;
BEGIN
SELECT ITEMRATE INTO identity
FROM itemFile
WHERE itemcode = value;
IF identity < 200 THEN
value2 := 200;
ELSE
value2 :=50;
END IF;
END;
匿名块执行过程
tvalue2 NUMBER;
BEGIN
test('i202', tvalue2);
DBMS_OUTPUT.PUT_LINE('value2的值为:' || TO_CHAR(value2));
END;
单独执行
EXECUTE myproc('0001');
过程与函数的异同
过程:
作为 PL/SQL 语句执行;
在规范中不包含 RETURN 子句;
不返回任何值(只有输入/输出参数,结果集);
可以包含 RETURN 语句,但是与函数不同,它不能用于返回值。
函数:
作为表达式的一部分调用;
必须在规范中包含 RETURN 子句;
必须返回单个值;
必须包含至少一条 RETURN 语句。
程序包
程序包是一种数据库对象,它是对相关 PL/SQL 类型、子程序、游标、异常、变量和常量的封装。
程序包规范:声明类型、变量、常量、异常、游标和子程序。
程序包主体:用于实现在程序包规范中定义的游标、子程序。
程序包的优点:程序包将相关的功能在逻辑上组织在一起,模块化,信息隐藏和更好的性能。
引入目的:为了有效的管理函数和存储过程,当项目模块很多的时候,用程序包管理就很有效了。
语法
create or replace 包名 as
变量名称1 数据类型1;
变量名称2 数据类型2;
····
····
function 函数名称1(参数列表) return 数据类型1;
function 函数名称2(参数列表) return 数据类型2;
····
····
procedure 存储过程名称1(参数列表);
procedure 存储过程名称2(参数列表);
····
····
end 包名;
--创建包,放置存储过程、函数 create package pkg_book as function getBookCount return number; procedure addBook(bName in varchar2,typeid in number,n1 out number,n2 out number); end pkg_book; --创建包体,实现方法 create package body pkg_book as function getBookCount return number as begin declare book_count number; begin select count(*) into book_count from t_book; return book_count; end; end getBookCount; procedure addBook(bName in varchar2,typeid in number,n1 out number,n2 out number) as begin declare maxId number; n number; begin --n1存储执行前数据条数 select count(*) into n1 from t_book; select count(*) into n from t_book where t_book.bookname=bName; if(n>0) then select count(*) into n2 from t_book; return; end if; select max(id) into maxId from t_book; insert into t_book values(maxId+1,bName,typeid); --n2存储执行后数据条数 select count(*) into n2 from t_book; commit; end; end addBook; end pkg_book; --调用 begin dbms_output.put_line('表中有'||pkg_book.getBookCount||'条记录'); end;
游标
游标是一种 PL/SQL 控制结构,可以对SQL语句的处理进行显式控制,便于对表的数据逐条进行处理。ps.当表中数据量大的时候,不建议使用游标(效率不高,耗费资源),但是它能逐条取数据方法灵活。
游标是记录的指针,利用游标对活动集的更新或删除会反馈到表的记录上。在学习jdbc操作的时候返回的结果集。ResultSet呢其实这里的结果集就可以通过游标来取的
游标的属性:
--%rowcount 整型 获得fetch语句返回的数据行数
--%found 布尔型 最近的fetch语句返回一行数据则为真,否则为假
--%notfound 布尔型 与%found属性的返回值相反
--%isopen 布尔型 游标已经打开则为真,否则为假
--其中%notfound是游标中找不到元素时候返回true,通常用来判断推退出循环。
游标的使用需要有四个步骤
声明------》打开-----》取值-----》关闭
--声明游标:利用关键字 cursor + 任意名字[参数列表(可有可无)] +is +你的sql语句
eg:cursor cur is
select name,age from student;
这里就是声明了一个游标并且给其赋值。
打开游标:open + 游标;
eg:open cur;
这里没有什么可说的就类似于jdbc 的connection的open方法
取值:取值有一个关键字叫做fetch英文翻译来就是抓取的意思 使用方法如下::
fetch +游标名称 into 你定义的变量;就是将抓取的游标赋给你之前定义的其他变量。
因为既然使用了游标肯定是有多行数据。所以一般这里的fetch都是放在loop里边的。
--声明变量接受游标中的数据。 v_name student.name%type; v_num student.age%type; begin --打开游标 open cur; --遍历取值 loop --获取游标中德数据,如果有则赋值变量,否则退出 fetch cur into v_name v_num; exit when cur%notfound dbms_output.put_line('姓名:' || v_name || '年龄:' ||v_num); end loop; --关闭游标 close cur;
关闭游标:当便利完毕关闭游标即可:close +游标名;
上边有个语法叫做exit when cur%notfound dbms_output.put_line('姓名:' || v_name || '年龄:' ||v_num);
这里的属性cur%notfound就是如果游标中没有值返回true,因为每次游标都是向下读取的。读到没有数据就会返回cur%notfound为true。
游标的定义
--显示cursor的处理 declare ---声明cursor,创建和命名一个sql工作区 cursor cursor_name is select real_name from account_hcz; v_realname varchar2(20); begin open cursor_name;---打开cursor,执行sql语句产生的结果集 fetch cursor_name into v_realname;--提取cursor,提取结果集中的记录 dbms_output.put_line(v_realname); close cursor_name;--关闭cursor end;
显式游标是由用户显式声明的游标。根据在游标中定义的查询,查询返回的行集可以包含零或多行,这些行称为活动集。游标将指向活动集中的当前行
显式游标操纵过程:声明、打开、从游标中获取记录、关闭。
用for in 使用cursor
FOR 循环游标:采用遍历方式,自动打开、提取和关闭游标。
DECLARE
/* 定义带参数游标 */
CURSOR cur_para(id varchar2) IS
SELECT books_name FROM books WHERE books_id = id;
BGEIN
/* 调用带参数游标,并以 FOR 循环方式处理 */
FOR cur IN cur_para('0001') LOOP
DBMS_OUTPUT.PUT_LINE(cur.books_id || ' ' || cur.books_id);
END LOOP;
END;
存储过程中游标定义使用
as //定义(游标一个可以遍历的结果集) CURSOR cur_1 IS SELECT area_code,CMCODE,SUM(rmb_amt)/10000 rmb_amt_sn, SUM(usd_amt)/10000 usd_amt_sn FROM BGD_AREA_CM_M_BASE_T WHERE ym >= vs_ym_sn_beg AND ym <= vs_ym_sn_end GROUP BY area_code,CMCODE; begin //执行(常用For语句遍历游标) FOR rec IN cur_1 LOOP UPDATE xxxxxxxxxxx_T SET rmb_amt_sn = rec.rmb_amt_sn,usd_amt_sn = rec.usd_amt_sn WHERE area_code = rec.area_code AND CMCODE = rec.CMCODE AND ym = is_ym; END LOOP;
带参数的显式游标
参数不需指定长度或者精度
CURSOR C_USER(C_ID NUMBER) IS SELECT NAME FROM USER WHERE TYPEID=C_ID; OPEN C_USER(变量值); FETCH C_USER INTO V_NAME; EXIT WHEN FETCH C_USER%NOTFOUND; CLOSE C_USER;
使用显示游标删除或更新记录
定义时:需使用 SELECT ... FOR UPDATE 语句表示事物的锁定;
执行时:需使用 WHERE CURRENT OF curXXX 子句指定游标的当前行。
/* 定义部分 */
CURSOR cur IS
SELECT name FROM deptment FOR UPDATE;
....
/* 执行部分 */
UPDATE deptment SET name=name || '_tt' WHERE CURRENT OF cur;
隐式游标
不需声明,打开和关闭的游标。PL/SQL 为所有的 SQL 数据操纵语句隐式声明游标,它是不能直接命名和控制。
BEGIN FROM cur IN (SELECT name FROM deptment) LOOP DBMS_OUTPUT.PUT_LINE(cur.books_id || ' ' || cur.books_id); END LOOP; END;
触发器简介
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。
因此触发器不需要人为的去调用,也不能调用。
然后,触发器的触发条件其实在你定义的时候就已经设定好了。
这里面需要说明一下,触发器可以分为语句级触发器和行级触发器。
详细的介绍可以参考网上的资料,简单的说就是语句级的触发器可以在某些语句执行前或执行后被触发。而行级触发器则是在定义的了触发的表中的行数据改变时就会被触发一次。
具体举例:
1、 在一个表中定义的语句级的触发器,当这个表被删除时,程序就会自动执行触发器里面定义的操作过程。这个就是删除表的操作就是触发器执行的条件了。
2、 在一个表中定义了行级的触发器,那当这个表中一行数据发生变化的时候,比如删除了一行记录,那触发器也会被自动执行了。
触发器的语法:
create [or replace] tigger 触发器名 触发时间 触发事件 on 表名 [for each row] begin pl/sql语句 end
触发器名:触发器对象的名称。由于触发器是数据库自动执行的,因此该名称只是一个名称,没有实质的用途。
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发器执行;
after:表示在数据库动作之后触发器执行。
触发事件:指明哪些数据库动作会触发此触发器:
insert:数据库插入会触发此触发器;
update:数据库修改会触发此触发器;
delete:数据库删除会触发此触发器。
表 名:数据库触发器所在的表。
for each row:对表的每一行触发器执行一次。如果没有这一选项,则只对整个表执行一次。
功能:
1、 允许/限制对表的修改
2、 自动生成派生列,比如自增字段
3、 强制数据一致性
4、 提供审计和日志记录
5、 防止无效的事务处理
6、 启用复杂的业务逻辑
举例
1)、下面的触发器在更新表tb_emp之前触发,目的是不允许在周末修改表:
create or replace trigger auth_secure before insert or update or DELETE on tb_emp begin IF(to_char(sysdate,'DY')='星期日') THEN RAISE_APPLICATION_ERROR(-20600,'不能在周末修改表tb_emp'); END IF; END; /
2)、使用触发器实现序号自增
创建一个测试表:
create table tab_user( id number(11) primary key, username varchar(50), password varchar(50) );
创建一个序列:
创建一个触发器:
CREATE OR REPLACE TRIGGER MY_TGR BEFORE INSERT ON TAB_USER FOR EACH ROW--对表的每一行触发器执行一次 DECLARE NEXT_ID NUMBER; BEGIN SELECT MY_SEQ.NEXTVAL INTO NEXT_ID FROM DUAL; :NEW.ID := NEXT_ID; --:NEW表示新插入的那条记录 END;
向表插入数据:
insert into tab_user(username,password) values('admin','admin');
insert into tab_user(username,password) values('fgz','fgz');
insert into tab_user(username,password) values('test','test');
COMMIT;
查询表结果:SELECT * FROM TAB_USER;
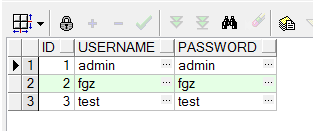
3)、当用户对test表执行DML语句时,将相关信息记录到日志表
--创建测试表 CREATE TABLE test( t_id NUMBER(4), t_name VARCHAR2(20), t_age NUMBER(2), t_sex CHAR ); --创建记录测试表 CREATE TABLE test_log( l_user VARCHAR2(15), l_type VARCHAR2(15), l_date VARCHAR2(30) );
创建触发器:
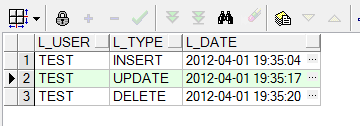
--创建触发器 CREATE OR REPLACE TRIGGER TEST_TRIGGER AFTER DELETE OR INSERT OR UPDATE ON TEST DECLARE V_TYPE TEST_LOG.L_TYPE%TYPE; BEGIN IF INSERTING THEN --INSERT触发 V_TYPE := 'INSERT'; DBMS_OUTPUT.PUT_LINE('记录已经成功插入,并已记录到日志'); ELSIF UPDATING THEN --UPDATE触发 V_TYPE := 'UPDATE'; DBMS_OUTPUT.PUT_LINE('记录已经成功更新,并已记录到日志'); ELSIF DELETING THEN --DELETE触发 V_TYPE := 'DELETE'; DBMS_OUTPUT.PUT_LINE('记录已经成功删除,并已记录到日志'); END IF; INSERT INTO TEST_LOG VALUES (USER, V_TYPE, TO_CHAR(SYSDATE, 'yyyy-mm-dd hh24:mi:ss')); --USER表示当前用户名 END; / --下面我们来分别执行DML语句 INSERT INTO test VALUES(101,'zhao',22,'M'); UPDATE test SET t_age = 30 WHERE t_id = 101; DELETE test WHERE t_id = 101; --然后查看效果 SELECT * FROM test; SELECT * FROM test_log;
运行结果如下:
3)、创建触发器,它将映射emp表中每个部门的总人数和总工资
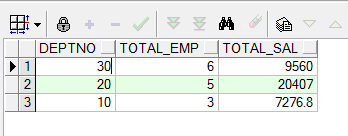
--创建映射表 CREATE TABLE dept_sal AS SELECT deptno, COUNT(empno) total_emp, SUM(sal) total_sal FROM scott.emp GROUP BY deptno; --创建触发器 CREATE OR REPLACE TRIGGER EMP_INFO AFTER INSERT OR UPDATE OR DELETE ON scott.EMP DECLARE CURSOR CUR_EMP IS SELECT DEPTNO, COUNT(EMPNO) AS TOTAL_EMP, SUM(SAL) AS TOTAL_SAL FROM scott.EMP GROUP BY DEPTNO; BEGIN DELETE DEPT_SAL; --触发时首先删除映射表信息 FOR V_EMP IN CUR_EMP LOOP --DBMS_OUTPUT.PUT_LINE(v_emp.deptno || v_emp.total_emp || v_emp.total_sal); --插入数据 INSERT INTO DEPT_SAL VALUES (V_EMP.DEPTNO, V_EMP.TOTAL_EMP, V_EMP.TOTAL_SAL); END LOOP; END; --对emp表进行DML操作 INSERT INTO emp(empno,deptno,sal) VALUES('123','10',10000); SELECT * FROM dept_sal; DELETE EMP WHERE empno=123; SELECT * FROM dept_sal;
显示结果如下:
4)、创建触发器,用来记录表的删除数据
--创建表 CREATE TABLE employee( id VARCHAR2(4) NOT NULL, name VARCHAR2(15) NOT NULL, age NUMBER(2) NOT NULL, sex CHAR NOT NULL ); --插入数据 INSERT INTO employee VALUES('e101','zhao',23,'M'); INSERT INTO employee VALUES('e102','jian',21,'F'); --创建记录表(包含数据记录) CREATE TABLE old_employee AS SELECT * FROM employee; --创建触发器 CREATE OR REPLACE TRIGGER TIG_OLD_EMP AFTER DELETE ON EMPLOYEE FOR EACH ROW --语句级触发,即每一行触发一次 BEGIN INSERT INTO OLD_EMPLOYEE VALUES (:OLD.ID, :OLD.NAME, :OLD.AGE, :OLD.SEX); --:old代表旧值 END; / --下面进行测试 DELETE employee; SELECT * FROM old_employee;
5)、创建触发器,利用视图插入数据
--创建表 CREATE TABLE tab1 (tid NUMBER(4) PRIMARY KEY,tname VARCHAR2(20),tage NUMBER(2)); CREATE TABLE tab2 (tid NUMBER(4),ttel VARCHAR2(15),tadr VARCHAR2(30)); --插入数据 INSERT INTO tab1 VALUES(101,'zhao',22); INSERT INTO tab1 VALUES(102,'yang',20); INSERT INTO tab2 VALUES(101,'13761512841','AnHuiSuZhou'); INSERT INTO tab2 VALUES(102,'13563258514','AnHuiSuZhou'); --创建视图连接两张表 CREATE OR REPLACE VIEW tab_view AS SELECT tab1.tid,tname,ttel,tadr FROM tab1,tab2 WHERE tab1.tid = tab2.tid; --创建触发器 CREATE OR REPLACE TRIGGER TAB_TRIGGER INSTEAD OF INSERT ON TAB_VIEW BEGIN INSERT INTO TAB1 (TID, TNAME) VALUES (:NEW.TID, :NEW.TNAME); INSERT INTO TAB2 (TTEL, TADR) VALUES (:NEW.TTEL, :NEW.TADR); END; / --现在就可以利用视图插入数据 INSERT INTO tab_view VALUES(106,'ljq','13886681288','beijing'); --查询 SELECT * FROM tab_view; SELECT * FROM tab1; SELECT * FROM tab2;
6)、创建触发器,比较emp表中更新的工资
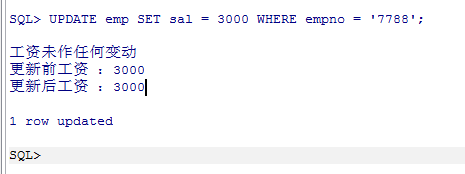
--创建触发器 set serveroutput on; CREATE OR REPLACE TRIGGER SAL_EMP BEFORE UPDATE ON EMP FOR EACH ROW BEGIN IF :OLD.SAL > :NEW.SAL THEN DBMS_OUTPUT.PUT_LINE('工资减少'); ELSIF :OLD.SAL < :NEW.SAL THEN DBMS_OUTPUT.PUT_LINE('工资增加'); ELSE DBMS_OUTPUT.PUT_LINE('工资未作任何变动'); END IF; DBMS_OUTPUT.PUT_LINE('更新前工资 :' || :OLD.SAL); DBMS_OUTPUT.PUT_LINE('更新后工资 :' || :NEW.SAL); END; / --执行UPDATE查看效果 UPDATE emp SET sal = 3000 WHERE empno = '7788';
运行结果如下:
7)、创建触发器,将操作CREATE、DROP存储在log_info表
--创建表 CREATE TABLE log_info( manager_user VARCHAR2(15), manager_date VARCHAR2(15), manager_type VARCHAR2(15), obj_name VARCHAR2(15), obj_type VARCHAR2(15) ); --创建触发器 set serveroutput on; CREATE OR REPLACE TRIGGER TRIG_LOG_INFO AFTER CREATE OR DROP ON SCHEMA BEGIN INSERT INTO LOG_INFO VALUES (USER, SYSDATE, SYS.DICTIONARY_OBJ_NAME, SYS.DICTIONARY_OBJ_OWNER, SYS.DICTIONARY_OBJ_TYPE); END; / --测试语句 CREATE TABLE a(id NUMBER); CREATE TYPE aa AS OBJECT(id NUMBER); DROP TABLE a; DROP TYPE aa; --查看效果 SELECT * FROM log_info; --相关数据字典----------------------------------------------------- SELECT * FROM USER_TRIGGERS; --必须以DBA身份登陆才能使用此数据字典 SELECT * FROM ALL_TRIGGERS;SELECT * FROM DBA_TRIGGERS; --启用和禁用 ALTER TRIGGER trigger_name DISABLE; ALTER TRIGGER trigger_name ENABLE;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号