
DOM介绍
DOM(Document Object Model)解析是官方提供的XML解析方式之一,使用时无需引入第三方包,代码编写简单,方便修改树结构,但是由于DOM解析时是将整个XML文件加载到内存中进行解析,因此当XML文件较大时,使用DOM解析效率会降低,而且可能造成内存溢出。
XML生成
代码如下:
1 public static void write() { 2 3 //文档构建工厂 4 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); 5 try { 6 //文档构建器 7 DocumentBuilder builder = dbf.newDocumentBuilder(); 8 //文档 9 Document doc = builder.newDocument(); 10 //设置xml文件是否独立 11 doc.setXmlStandalone(true); 12 //设置xml文件版本,默认1.0 13 doc.setXmlVersion("1.1"); 14 15 //创建根目录节点 16 Element root = doc.createElement("conpany"); 17 //设置节点属性 18 root.setAttribute("name", "hd"); 19 //添加根节点 20 doc.appendChild(root); 21 22 23 Element department = doc.createElement("department"); 24 department.setAttribute("name", "test"); 25 //设置节点文本 26 department.setTextContent("123456"); 27 //添加到根节点 28 root.appendChild(department); 29 30 // 工厂类,用来获取转换对象 31 TransformerFactory transFactory = TransformerFactory.newInstance(); 32 //转化对象 33 Transformer transFormer = transFactory.newTransformer(); 34 // 设置文档自动换行 35 transFormer.setOutputProperty(OutputKeys.INDENT, "yes"); 36 //设置编码方式,默认UTF-8 37 //transFormer.setOutputProperty(OutputKeys.ENCODING, "GB2312"); 38 //文件源 39 DOMSource domSource = new DOMSource(doc); 40 41 File file = new File("src/doc-write.xml"); 42 if (file.exists()) { 43 file.delete(); 44 } 45 file.createNewFile(); 46 //输出文件流 47 FileOutputStream out = new FileOutputStream(file); 48 49 //结果流 50 StreamResult xmlResult = new StreamResult(out); 51 //转化 52 transFormer.transform(domSource, xmlResult); 53 54 System.out.println("创建生成文件位置===========" + file.getAbsolutePath()); 55 } catch (Exception e) { 56 e.printStackTrace(); 57 } 58 }
输出:创建生成文件位置===========D:\workspace\test-xml\src\doc-write.xml
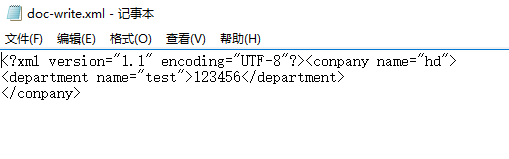
doc-write.xml的内容:
XML解析
需要在src目录中,先存放一个test.xml文件
1 <?xml version="1.0" encoding="UTF-8"?> 2 <conpany name="hd"> 3 <department name="department1"> 4 <employee name="employee1" id="1">123</employee> 5 </department> 6 <department name="department2"> 7 <employee name="employee2" id="2">321</employee> 8 <employee name="employee3" id="3"></employee> 9 </department> 10 <department name="department3"> 11 </department> 12 </conpany>
新建一个TestDom的java类,里面写一个read方法,代码如下:
1 public static void read() { 2 3 DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance(); 4 try { 5 DocumentBuilder builder = builderFactory.newDocumentBuilder(); 6 //输入流 7 InputStream is = TestDom.class.getClassLoader().getResourceAsStream("test.xml"); 8 //文档构建器解析,得到文档 9 Document doc = builder.parse(is); 10 11 //获取根目录,元素 12 Element root = doc.getDocumentElement(); 13 if (root == null) return; 14 15 //获取元素名字 16 System.out.print(root.getNodeName()); 17 //获取元素属性name的值 18 System.out.println("\t" + root.getAttribute("name")); 19 20 //获取根元素下的子节点,此方法获取节点(节点包括:标签间的文本,和空白部分) 21 NodeList departmentNodes = root.getChildNodes(); 22 if (departmentNodes == null) return; 23 24 //遍历节点 25 for (int i = 0; i < departmentNodes.getLength(); i++) { 26 27 Node department = departmentNodes.item(i); 28 if (department != null && department.getNodeType() == Node.ELEMENT_NODE) {//非空白文本标签 29 30 //获取节点名字 31 System.out.print("\t" + department.getNodeName()); 32 //先获取节点属性集,再获取属性name的值 33 System.out.println("\t" + department.getAttributes().getNamedItem("name").getNodeValue()); 34 35 //获取节点下面的所有子节点 36 NodeList employees = department.getChildNodes(); 37 if (employees == null) continue; 38 39 for (int j = 0; j < employees.getLength(); j++) { 40 41 Node employee = employees.item(j); 42 if (employee != null && employee.getNodeType() == Node.ELEMENT_NODE) { 43 44 System.out.print("\t" + "\t" + employee.getNodeName()); 45 System.out.print("\t" + employee.getAttributes().getNamedItem("id").getNodeValue()); 46 System.out.print("\t" + employee.getAttributes().getNamedItem("name").getNodeValue()); 47 System.out.println("\t" + employee.getTextContent().trim()); 48 49 } 50 } 51 } 52 } 53 54 } catch (Exception e) { 55 56 e.printStackTrace(); 57 } 58 59 }
XML修改
新建一个TestDom的java类,里面写一个update方法,代码如下:
1 public static void update() { 2 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); 3 try { 4 DocumentBuilder builder = dbf.newDocumentBuilder(); 5 InputStream is = TestDom.class.getClassLoader().getResourceAsStream("test.xml"); 6 Document doc = builder.parse(is); 7 Element root = doc.getDocumentElement(); 8 if (root == null) return; 9 10 // 修改属性 11 root.setAttribute("name", "hd2"); 12 NodeList departmentNodes = root.getChildNodes(); 13 if (departmentNodes != null) { 14 for (int i = 0; i < departmentNodes.getLength() - 1; i++) { 15 16 Node department = departmentNodes.item(i); 17 if (department.getNodeType() == Node.ELEMENT_NODE) { 18 String departmentName = department.getAttributes().getNamedItem("name").getNodeValue(); 19 if ("department3".equals(departmentName)) { 20 21 // 删除节点 22 root.removeChild(department); 23 } else if ("department2".equals(departmentName)) { 24 25 //新增节点 26 Element newChild = doc.createElement("employee"); 27 newChild.setAttribute("name", "employee4"); 28 newChild.setTextContent("44444"); 29 department.appendChild(newChild); 30 } 31 } 32 } 33 } 34 35 TransformerFactory transFactory = TransformerFactory.newInstance(); 36 Transformer transFormer = transFactory.newTransformer(); 37 transFormer.setOutputProperty(OutputKeys.INDENT, "yes"); 38 DOMSource domSource = new DOMSource(doc); 39 40 File file = new File("src/dom-test.xml"); 41 if (file.exists()) { 42 file.delete(); 43 } 44 file.createNewFile(); 45 46 FileOutputStream out = new FileOutputStream(file); 47 StreamResult xmlResult = new StreamResult(out); 48 transFormer.transform(domSource, xmlResult); 49 50 System.out.println("修改生成文件位置===========" + file.getAbsolutePath()); 51 } catch (Exception e) { 52 e.printStackTrace(); 53 } 54 } 55 56 }
输出:修改生成文件位置===========D:\workspace\test-xml\src\dom-test.xml
doc-test.xml的内容:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号