
哈希表介绍
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
通常,我们把这个关键字称为 Key,把对应的记录称为 Value,所以也可以说是通过 Key 访问一个映射表来得到 Value 的地址。而这个映射表,也叫作散列函数或者哈希函数,存放记录的数组叫作散列表。
其中有个特殊情况,就是通过不同的 Key,可能访问到同一个地址,这种现象叫作碰撞(Collision)。而通过某个 Key 一定会得到唯一的 Value 地址。
目前,这个哈希函数比较常用的实现方法比较多,通常需要考虑几个因素:关键字的长度、哈希表的大小、关键字的分布情况、记录的查找频率,等等。
哈希函数
-
直接寻址法:取关键字或关键字的某个线性函数值为散列地址。
-
数字分析法:通过对数据的分析,发现数据中冲突较少的部分,并构造散列地址。例如同学们的学号,通常同一届学生的学号,其中前面的部分差别不太大,所以用后面的部分来构造散列地址。
-
平方取中法:当无法确定关键字里哪几位的分布相对比较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为散列地址。这是因为:计算平方之后的中间几位和关键字中的每一位都相关,所以不同的关键字会以较高的概率产生不同的散列地址。
-
取随机数法:使用一个随机函数,取关键字的随机值作为散列地址,这种方式通常用于关键字长度不同的场合。
-
除留取余法:取关键字被某个不大于散列表的表长 n 的数 m 除后所得的余数 p 为散列地址。这种方式也可以在用过其他方法后再使用。该函数对 m 的选择很重要,一般取素数或者直接用 n。
哈希冲突
散列表为什么会产生冲突呢?前面提到过,有时不同的 Key 通过哈希函数可能会得到相同的地址,这在我们操作时可能会对数据造成覆盖、丢失。之所以产生冲突是由于哈希函数有时对不同的 Key 计算之后获得了相同的地址。
冲突的处理方式也有很多,下面介绍几种。
-
开放地址法(也叫开放寻址法):实际上就是当需要存储值时,对Key哈希之后,发现这个地址已经有值了,这时该怎么办?不能放在这个地址,不然之前的映射会被覆盖。这时对计算出来的地址进行一个探测再哈希,比如往后移动一个地址,如果没人占用,就用这个地址。如果超过最大长度,则可以对总长度取余。这里移动的地址是产生冲突时的增列序量。
-
再哈希法:在产生冲突之后,使用关键字的其他部分继续计算地址,如果还是有冲突,则继续使用其他部分再计算地址。这种方式的缺点是时间增加了。
-
链地址法:链地址法其实就是对Key通过哈希之后落在同一个地址上的值,做一个链表。其实在很多高级语言的实现当中,也是使用这种方式处理冲突的,我们会在后面着重学习这种方式。
-
建立一个公共溢出区:这种方式是建立一个公共溢出区,当地址存在冲突时,把新的地址放在公共溢出区里。
散列表的存储结构
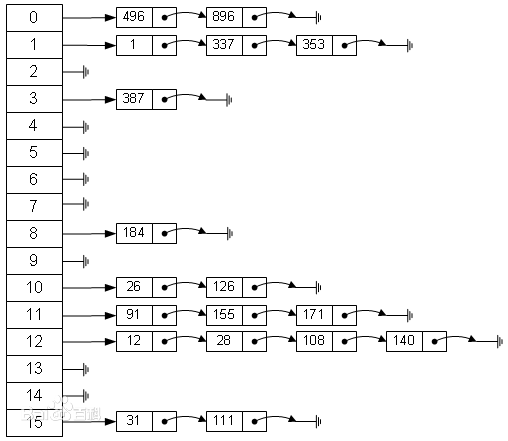
一个好的散列表设计,除了需要选择一个性能较好的哈希函数,否则冲突是无法避免的,所以通常还需要有一个好的冲突处理方式。这里我们选择除留取余法作为哈希函数,选择链地址法作为冲突处理方式。
具体存储结构如下
哈希表应用
参考:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号