
一、Redis 基础数据类型
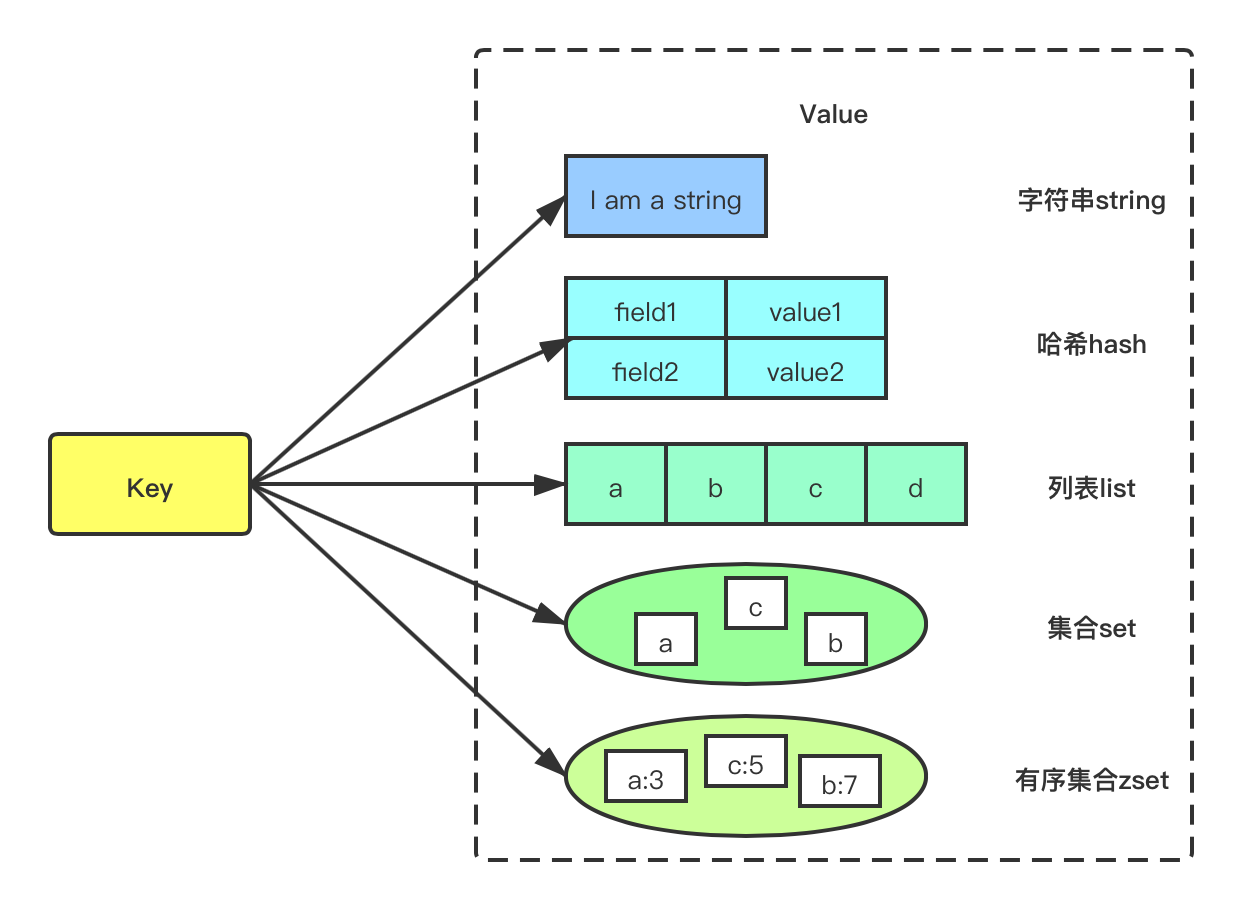
1、string (字符串)
字符串 string 是 Redis 最简单的数据结构。Redis 所有的数据结构都是以唯一的 key 字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。不同类型的数据结构的差异就在于 value 的结构不一样。字符串结构使用非常广泛,一个常见的用途就是缓存用户信息。我们将用户信息结构体使用 JSON 序列化成字符串,然后将序列化后的字符串塞进 Redis 来缓存。同样,取用户信息会经过一次反序列化的过程。
- 字符串常用操作
SET key value //存入字符串键值对 MSET key value [key value ...] //批量存储字符串键值对 SETNX key value //存入一个不存在的字符串键值对 GET key //获取一个字符串键值 MGET key [key ...] //批量获取字符串键值 DEL key [key ...] //删除一个键 EXPIRE key seconds //设置一个键的过期时间(秒)
- 原子加减
INCR key //将key中储存的数字值加1 DECR key //将key中储存的数字值减1 INCRBY key increment //将key所储存的值加上increment DECRBY key decrement //将key所储存的值减去decrement
应用场景
-
单值缓存
SET key value GET key -
对象缓存
1) SET user:1 value(json格式数据) 2) MSET user:1:name zhuge user:1:balance 1888 MGET user:1:name user:1:balance
-
分布式锁
SETNX product:10001 true //返回1代表获取锁成功 SETNX product:10001 true //返回0代表获取锁失败 。。。执行业务操作 DEL product:10001 //执行完业务释放锁 SET product:10001 true ex 10 nx //防止程序意外终止导致死锁
-
计数器
INCR article:readcount:{文章id} GET article:readcount:{文章id} -
Web集群session共享
spring session + redis实现session共享
-
分布式系统全局序列号
INCRBY orderId 1000 //redis批量生成序列号提升性能
2、hash (哈希)
Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同 Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
- Hash常用操作
HSET key field value //存储一个哈希表key的键值 HSETNX key field value //存储一个不存在的哈希表key的键值 HMSET key field value [field value ...] //在一个哈希表key中存储多个键值对 HGET key field //获取哈希表key对应的field键值 HMGET key field [field ...] //批量获取哈希表key中多个field键值 HDEL key field [field ...] //删除哈希表key中的field键值 HLEN key //返回哈希表key中field的数量 HGETALL key //返回哈希表key中所有的键值 HINCRBY key field increment //为哈希表key中field键的值加上增量increment
应用场景
-
对象缓存
- 电商购物车
-
1)以用户id为key 2)商品id为field 3)商品数量为value 购物车操作 添加商品 hset cart:1001 10088 1 增加数量 hincrby cart:1001 10088 1 商品总数 hlen cart:1001 删除商品 hdel cart:1001 10088 获取购物车所有商品 hgetall cart:1001
3、list (列表)
Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n),这点让人非常意外。 当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
- list常用操作
LPUSH key value [value ...] //将一个或多个值value插入到key列表的表头(最左边) RPUSH key value [value ...] //将一个或多个值value插入到key列表的表尾(最右边) LPOP key //移除并返回key列表的头元素 RPOP key //移除并返回key列表的尾元素 LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定 BLPOP key [key ...] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待 BRPOP key [key ...] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
应用场景
- 常用数据结构
Stack(栈) = LPUSH + LPOP Queue(队列)= LPUSH + RPOP Blocking MQ(阻塞队列)= LPUSH + BRPOP
- 微博消息和微信公号消息
我关注了MacTalk,备胎说车等大V 1)MacTalk发微博,消息ID为10018 LPUSH msg:{我-ID} 10018 2)备胎说车发微博,消息ID为10086 LPUSH msg:{我-ID} 10086 3)查看最新微博消息 LRANGE msg:{我-ID} 0 4
4、set (集合)
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL。 当集合中最后一个元素移除之后,数据结构自动删除,内存被回收。
-
Set常用操作
SADD key member [member ...] //往集合key中存入元素,元素存在则忽略, 若key不存在则新建 SREM key member [member ...] //从集合key中删除元素 SMEMBERS key //获取集合key中所有元素 SCARD key //获取集合key的元素个数 SISMEMBER key member //判断member元素是否存在于集合key中 SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除 SPOP key [count] //从集合key中选出count个元素,元素从key中删除
-
Set运算操作
SINTER key [key ...] //交集运算 SINTERSTORE destination key [key ..] //将交集结果存入新集合destination中 SUNION key [key ..] //并集运算 SUNIONSTORE destination key [key ...] //将并集结果存入新集合destination中 SDIFF key [key ...] //差集运算 SDIFFSTORE destination key [key ...] //将差集结果存入新集合destination中
应用场景
-
微信抽奖小程序
1)点击参与抽奖加入集合 SADD key {userlD} 2)查看参与抽奖所有用户 SMEMBERS key 3)抽取count名中奖者 SRANDMEMBER key [count] / SPOP key [count]
-
微信微博点赞,收藏,标签
1) 点赞 SADD like:{消息ID} {用户ID} 2) 取消点赞 SREM like:{消息ID} {用户ID} 3) 检查用户是否点过赞 SISMEMBER like:{消息ID} {用户ID} 4) 获取点赞的用户列表 SMEMBERS like:{消息ID} 5) 获取点赞用户数 SCARD like:{消息ID}
-
集合操作实现微博微信关注模型
5、zset (有序集合)
zset 似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。
zset 还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。我们可以对成绩按分数进行排序就可以得到他的名次。
-
ZSet常用操作
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素 ZREM key member [member …] //从有序集合key中删除元素 ZSCORE key member //返回有序集合key中元素member的分值 ZINCRBY key increment member //为有序集合key中元素member的分值加上increment ZCARD key //返回有序集合key中元素个数 ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素 ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素
-
Zset集合操作
ZUNIONSTORE destkey numkeys key [key ...] //并集计算 ZINTERSTORE destkey numkeys key [key …] //交集计算
应用场景
- Zset集合操作实现排行榜
1)点击新闻 ZINCRBY hotNews:20190819 1 守护香港 2)展示当日排行前十 ZREVRANGE hotNews:20190819 0 9 WITHSCORES 3)七日搜索榜单计算 ZUNIONSTORE hotNews:20190813-20190819 7 hotNews:20190813 hotNews:20190814... hotNews:20190819 4)展示七日排行前十 ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES
其他高级命令
1、keys:全量遍历键
用来列出所有满足特定正则字符串规则的key,当redis数据量比较大时,性能比较差,要避免使用
2、scan:渐进式遍历键
SCAN cursor [MATCH pattern] [COUNT count]
scan 参数提供了三个参数,第一个是 cursor 整数值(hash桶的索引值),第二个是 key 的正则模式, 第三个是一次遍历的key的数量(参考值,底层遍历的数量不一定),并不是符合条件的结果数量。第 一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历 到返回的 cursor 值为 0 时结束。
注意:但是scan并非完美无瑕, 如果在scan的过程中如果有键的变化(增加、 删除、 修改) ,那 么遍历效果可能会碰到如下问题: 新增的键可能没有遍历到, 遍历出了重复的键等情况, 也就是说 scan并不能保证完整的遍历出来所有的键, 这些是我们在开发时需要考虑的。
127.0.0.1:6379> SCAN 0 match s* count 3 1) "8" 2) 1) "s1001" 2) "s10" 127.0.0.1:6379> SCAN 8 match s* count 3 1) "12" 2) 1) "s7" 2) "s9" 3) "s5" 4) "s2" 127.0.0.1:6379> SCAN 12 match s* count 3 1) "18" 2) 1) "sa" 2) "sb" 127.0.0.1:6379> SCAN 18 match s* count 3 1) "26" 2) 1) "ss" 127.0.0.1:6379> SCAN 26 match s* count 3 1) "1" 2) 1) "s4" 2) "sabc" 127.0.0.1:6379> SCAN 1 match s* count 3 1) "13" 2) 1) "s3" 2) "s6" 127.0.0.1:6379> SCAN 13 match s* count 3 1) "11" 2) 1) "s1" 2) "sc" 127.0.0.1:6379> SCAN 11 match s* count 3 1) "31" 2) 1) "s8" 2) "sdiff" 127.0.0.1:6379> SCAN 31 match s* count 3 1) "0" 2) (empty list or set)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号