
路由
首先,来看个问题:

如图所示:当我们想一个集群保存文档时,文档该存储到哪个节点呢? 是随机吗? 是轮询吗?
实际上,在ELasticsearch中,会采用计算的方式来确定存储到哪个节点,计算公式如下:
shard = hash(routing) % number_of_primary_shards
- routing值是一个任意字符串,它默认是_id但也可以自定义。
- 这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数 的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
这就是为什么创建了主分片后,不能修改的原因。
文档的写操作
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
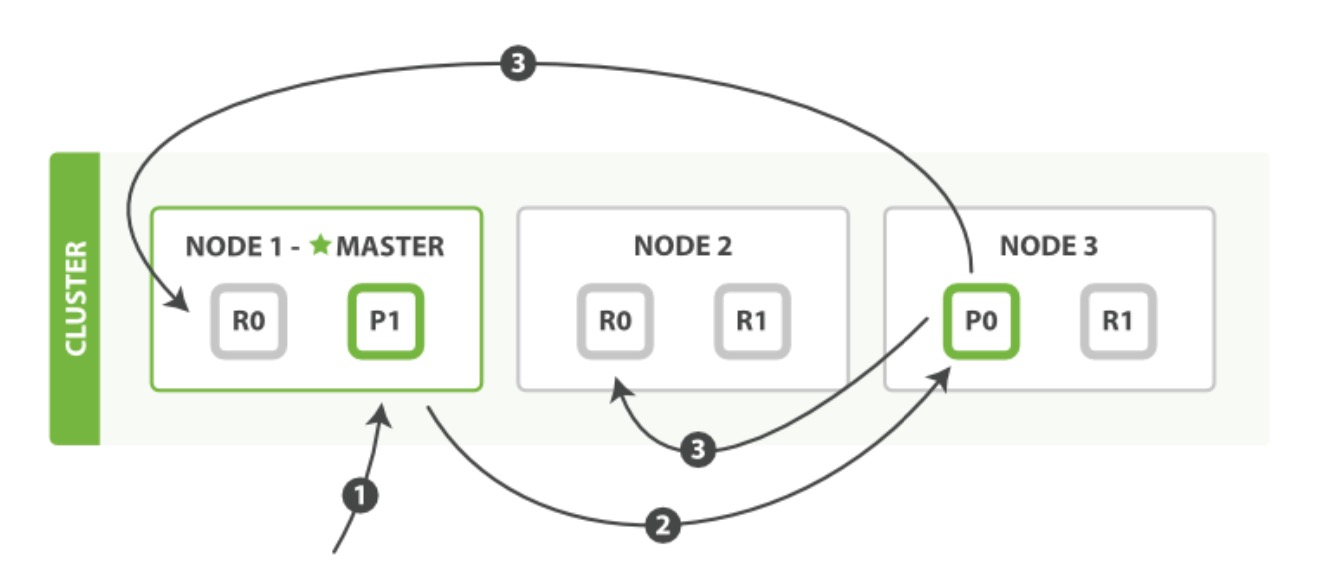
下面我们罗列在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
- 客户端给Node 1发送新建、索引或删除请求。
- 节点使用文档的_id确定文档属于分片0。它转发请求到Node 3,分片0位于这个节点上。
- Node 3 在主分片上执行请求,如果成功,它转发请求到相应的位于 Node 1 和 Node 2 的复制节点上。当所有的复制节点报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。
搜索文档(单个文档)
文档能够从主分片或任意一个复制分片被检索。

下面我们罗列在主分片或复制分片上检索一个文档必要的顺序步骤:
- 客户端给Node 1发送get请求。
- 节点使用文档的 _id 确定文档属于分片 0 。分片 0 对应的复制分片在三个节点上都有。此时,它转发请求到Node 2。
- Node 2 返回文档(document)给 Node 1 然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。 可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到复制分片上。这时复制分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和复制分片都是可用的。
全文搜索
对于全文搜索而言,文档可能分散在各个节点上,那么在分布式的情况下,如何搜索文档呢?
搜索,分为2个阶段,搜索(query)+取回(fetch)。
搜索(query)
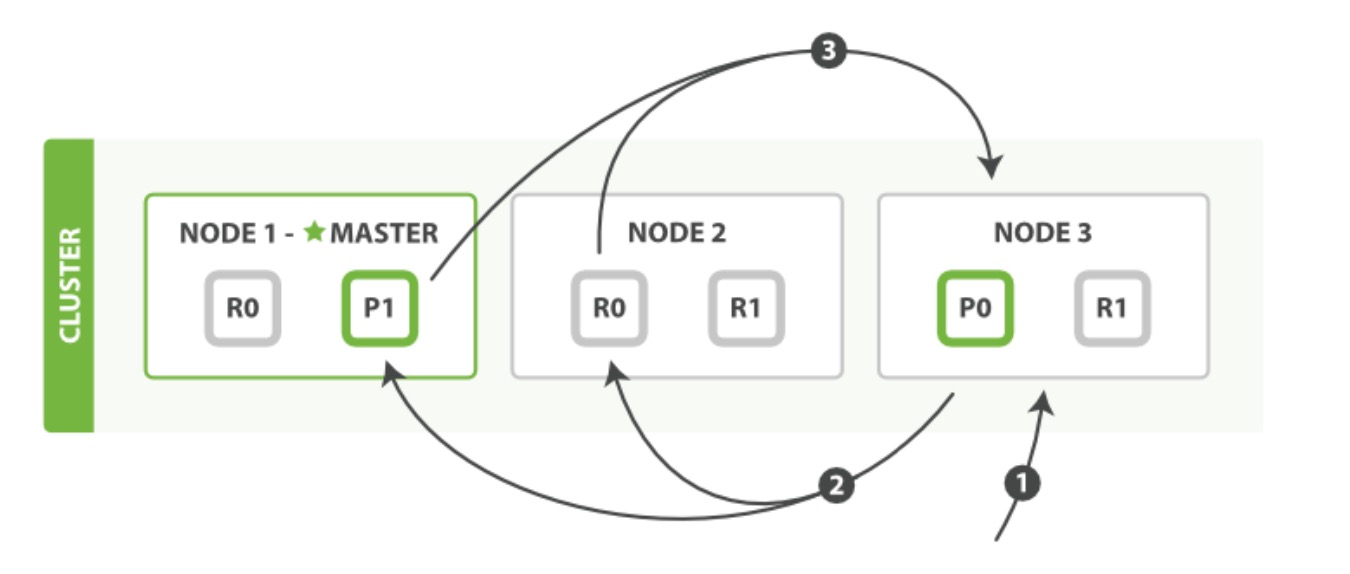
查询阶段包含以下三步:
- 客户端发送一个search(搜索)请求给 Node 3创建了一个长度为from+size的空优先级队
- Node 3 转发这个搜索请求到索引中每个分片的原本或副本。每个分片在本地执行这个查询并且结果将结果到一个大小为 from+size 的有序本地优先队列里去。
- 每个分片返回document的ID和它优先队列里的所有document的排序值给协调节点Node 3。Node 3把这些值合并到自己的优先队列里产生全局排序结果。
取回(fetch)
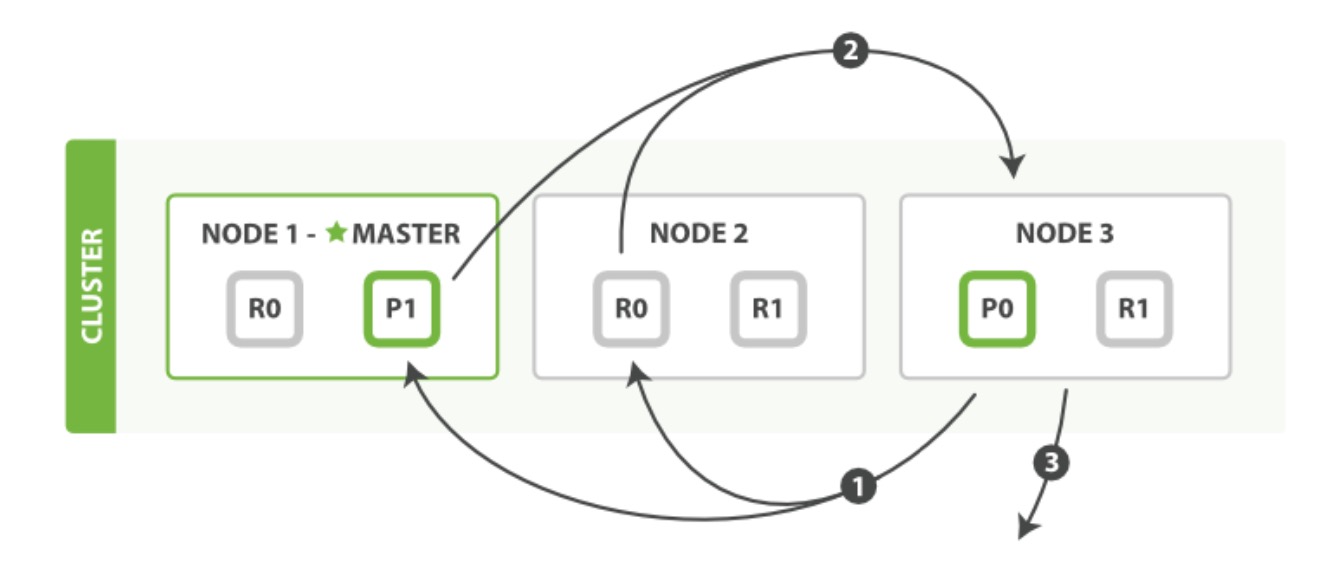
分发阶段由以下步骤构成:
- 协调节点辨别出哪个document需要取回,并且向相关分片发出 GET 请求。
- 每个分片加载document并且根据需要 enrich 它们,然后再将document返回协调节点。
- 一旦所有的document都被取回,协调节点会将结果返回给客户端。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号