语言模型文本匹配的主流方法回顾
 探索文本匹配的奥秘,一文尽览文本匹配主流方法
探索文本匹配的奥秘,一文尽览文本匹配主流方法
文本匹配作为一项非常经典的任务,在学界和工业界都有大量的研究和引用,如在检索系统中的各个环节(召回、排序等)。
本文通过一些论文,回顾语言模型文本匹配的工作,介绍一下不同方向文本匹配的主流方法。
探寻文本匹配的魅力,从学术到产业,它无处不在。无论是检索系统的提升还是排序算法的优化,文本匹配一直是研究和应用的热门话题。本文将带您穿越语言模型文本匹配的奇妙世界,探讨不同方向的主流方法。
目录
- 匹配模型
- A Deep Architecture for Matching Short Texts
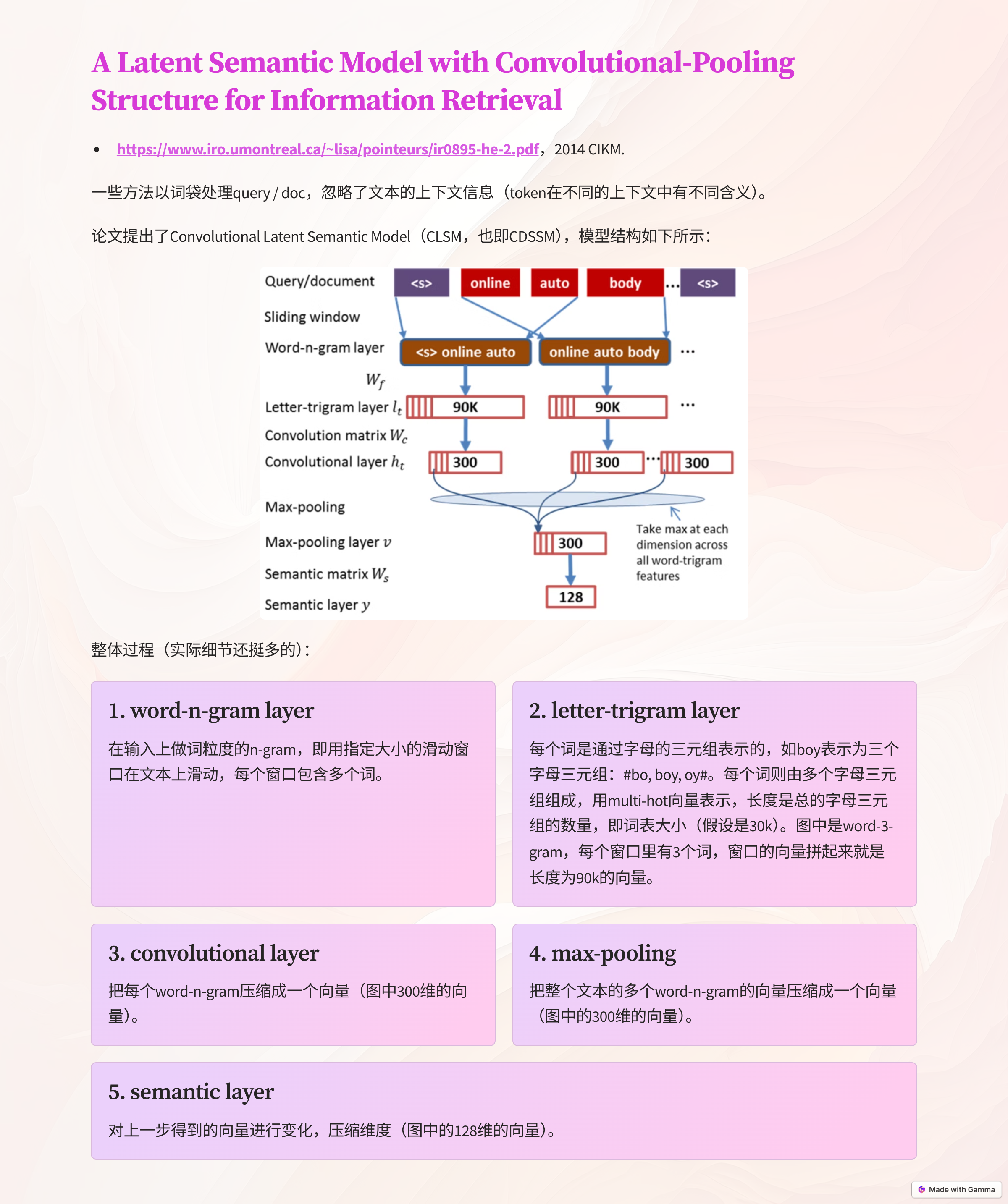
- A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
- A Deep Relevance Matching Model for Ad-hoc Retrieval
- DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval
- 双塔
- Semantic Text Matching for Long-Form Documents
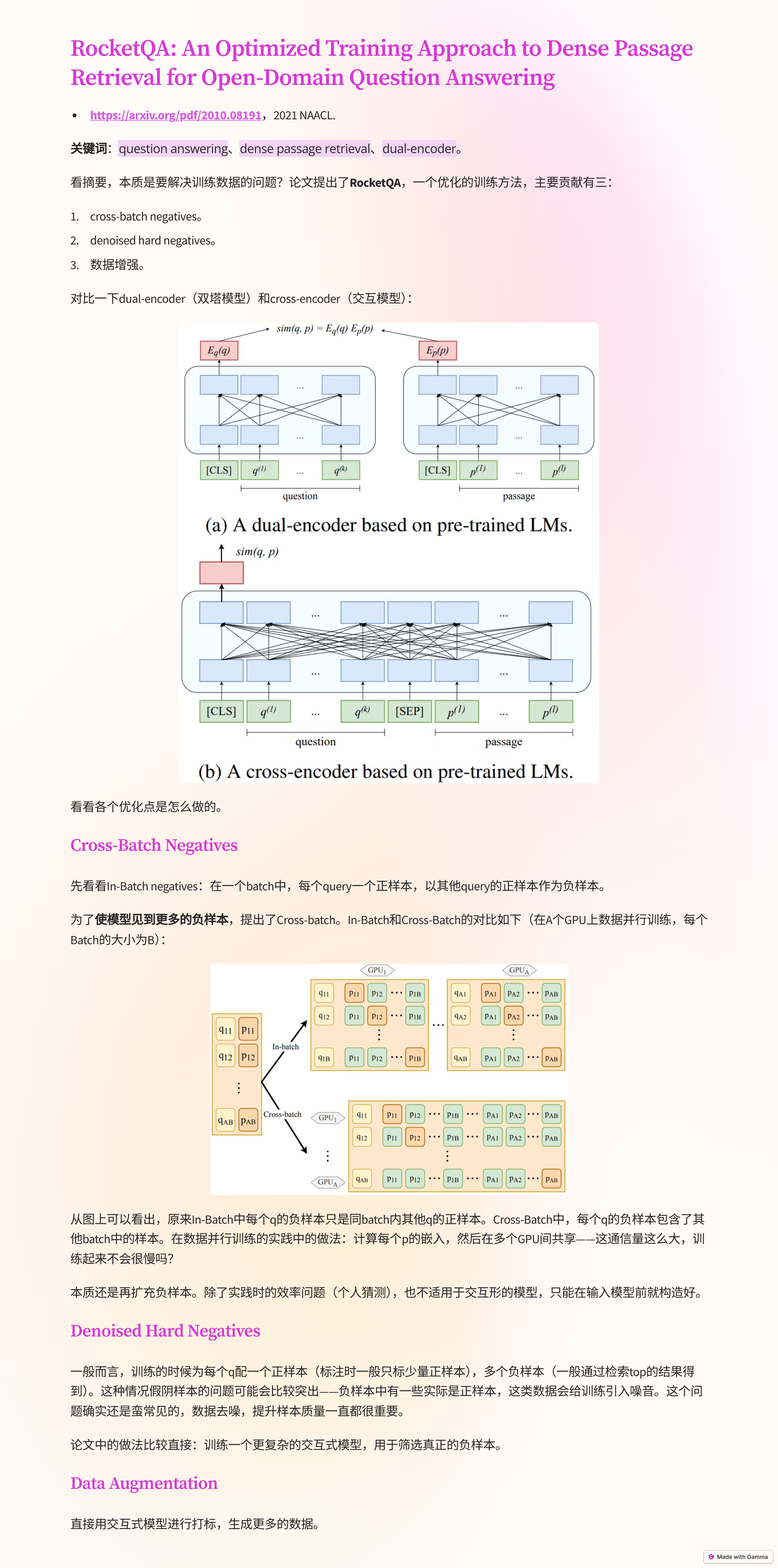
- RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
- PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval
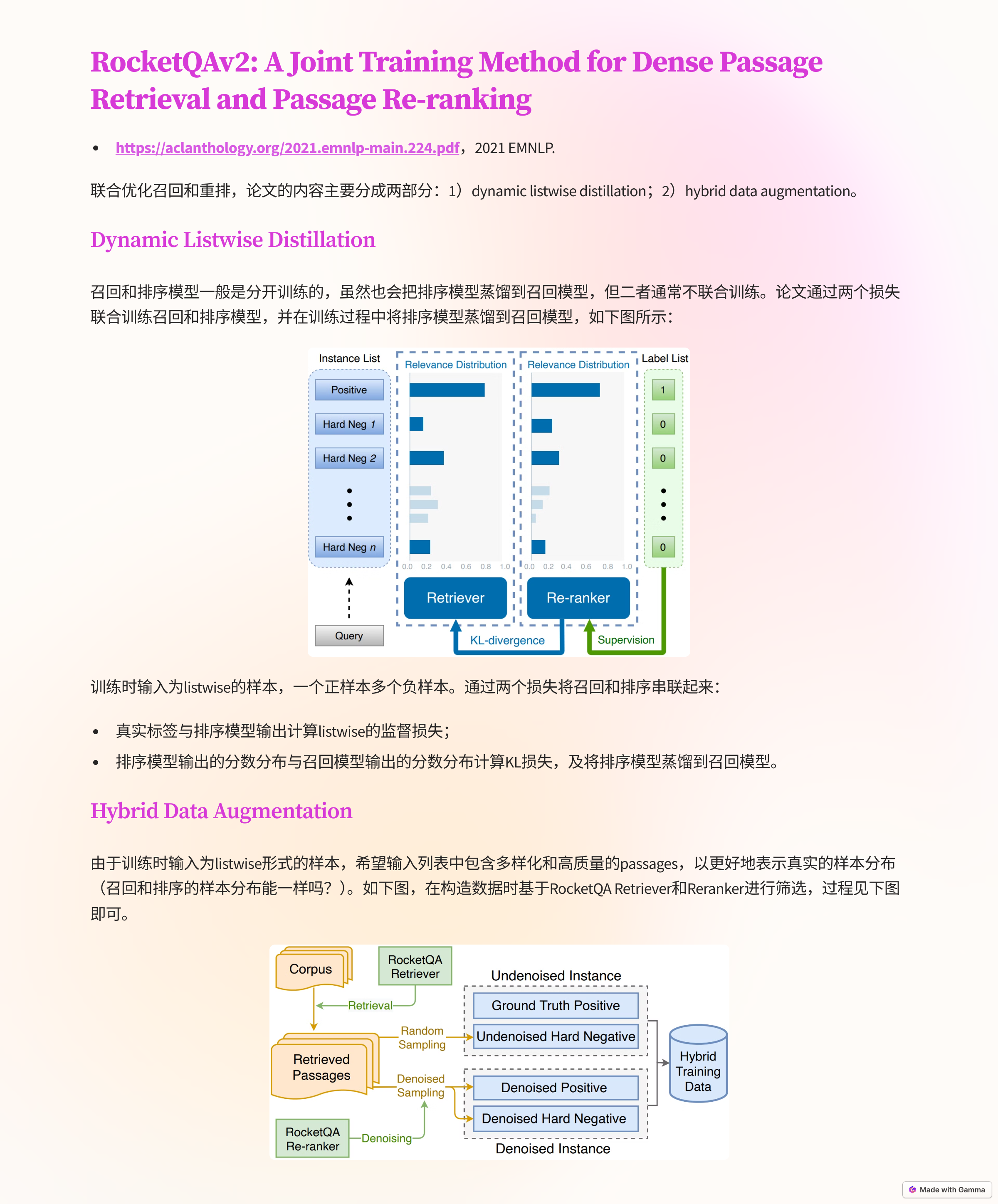
- RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
- Pre-trained Language Model for Web-scale Retrieval in Baidu Search
- 小小的总结
- 交互式
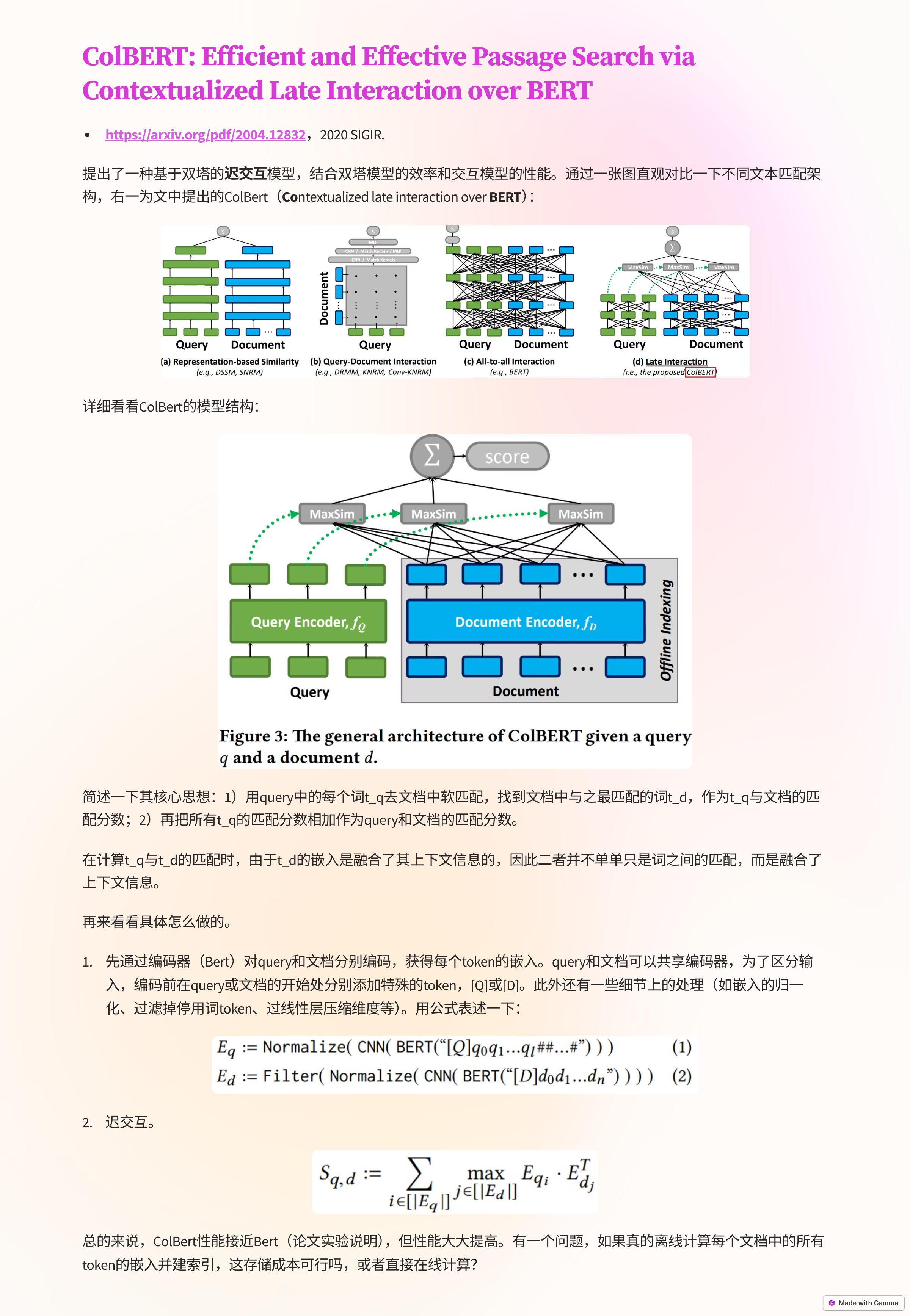
- ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
- ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
- PLAID: An Efficient Engine for Late Interaction Retrieval
PS : 发现一款很棒的AI PPT工具Gamma,本文就是在Gamma的辅助下生成的,希望大家喜欢。
















 浙公网安备 33010602011771号
浙公网安备 33010602011771号