论文速读记录 - 202410
 秋意浓,看几篇论文解解乏吧~
秋意浓,看几篇论文解解乏吧~
坚持看论文不容易啊,十月也是多事之秋。看的论文有点少,也有点散,还是要专注一些具体的方向,梳理脉络,整理方案,才是看论文找解决方案的正确思路。
以后的每篇论文解读的后面,会附带一点个人看法/评论,如有冒犯还请见谅。
目录:
-
LATE CHUNKING: CONTEXTUAL CHUNK EMBEDDINGS USING LONG-CONTEXT EMBEDDING MODELS
【RAG中生成文本块向量的“迟分”策略】
-
Multi-Epoch learning with Data Augmentation for Deep Click-Through Rate Prediction
【CTR模型训练时的One-Epoch过拟合现象】 -
DIFFERENTIAL TRANSFORMER
【改造注意力模块使模型更关注关键信息!】 -
Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection
【通过稀疏上下文选择加速RAG】
LATE CHUNKING: CONTEXTUAL CHUNK EMBEDDINGS USING LONG-CONTEXT EMBEDDING MODELS
论文的思路很简单。
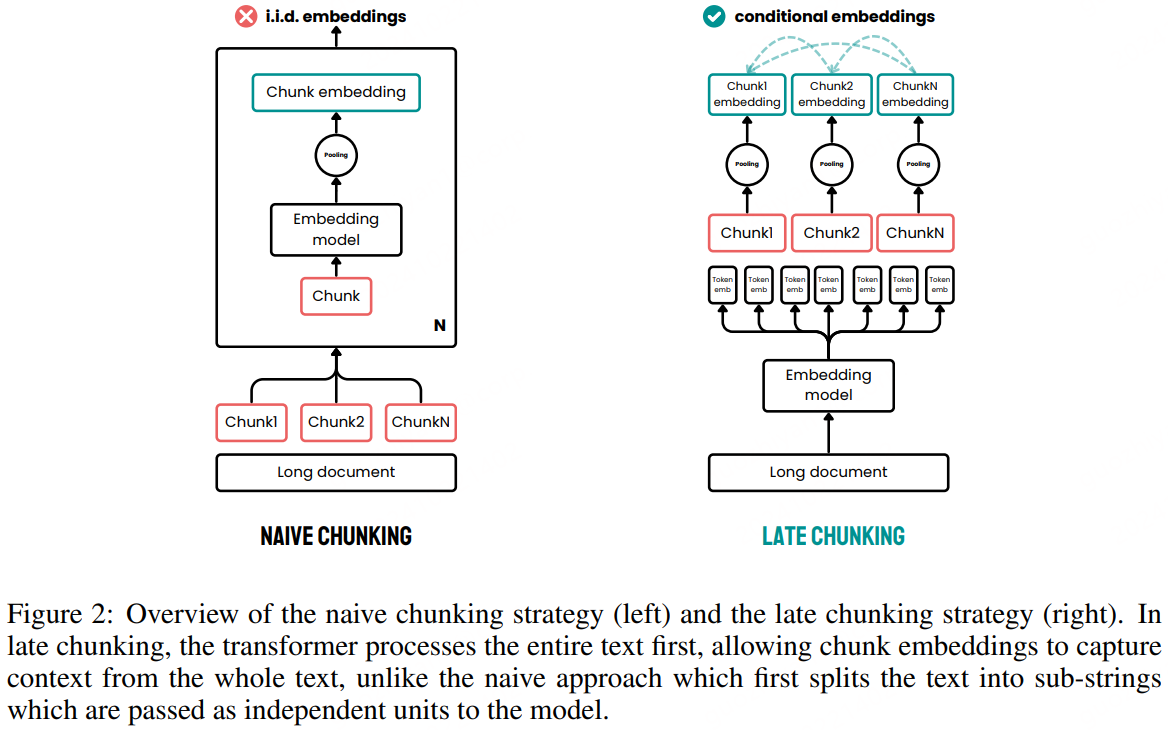
构建RAG系统时,通常会对文本进行分块,检索时也以文本块为粒度进行检索和利用,因此也会对文本块进行向量化处理。按块进行向量化也能避免信息被过度压缩。在传统的“naive chunking”方法中,文本被预先分割成小块,然后分别进行向量化,这可能导致上下文信息的丢失。关于先对长文本分块再逐个向量化的一个缺点:

论文介绍了一种名为“late chunking”的新方法,用于改善长文本的文本块嵌入。late chunking利用长上下文嵌入模型先获取长文本中所有token的向量,然后在token向量的基础上进行分块并池化得到分块的向量。
传统分块后向量化和迟分策略向量化的对比:
浅评:
整体想法还是比较直接、可行的,但是可能对Embedding Model要求更高了,需要能处理更长的输入。
Multi-Epoch learning with Data Augmentation for Deep Click-Through Rate Prediction
这篇论文探讨了在CTR模型中普遍存在的“One-Epoch”现象(可以参考阿里发表的论文《Towards Understanding the Overfitting Phenomenon of Deep Click-Through Rate Prediction Models》),即模型在第二个epoch开始时性能显著下降(发生过拟合),泛化能力变差。
论文分析了One-Epoch中的过拟合问题,发现主要由于数据的稀疏性导致的,主要有两个方面:
- Embedging-Data之间的依赖。数据稀疏通常指离散特征存在长尾问题。由于数据的稀疏性,嵌入向量更容易过拟合,更容易拟合高频而欠拟合低频数据,导致模型在新数据上的泛化能力下降。
- Embedding-MLP之间的依赖。由于数据的高维稀疏性,嵌入层生成的向量作为MLP的输入时,可能无法充分表达原始数据的所有信息,这导致MLP层在学习时可能过度依赖嵌入层的输出。
为了解决One-Epoch问题,论文提出了Multi-Epoch learning with Data Augmentation(MDEA)方法。MEDA通过减少嵌入层对训练数据或MLP层的依赖,以及通过在不同的嵌入空间中训练MLP来实现数据增强。MEDA的做法看起来很简单:每个epoch开始时重新初始化嵌入层的参数。

浅评。
训练CTR模型或者打分模型时这种One-Epoch现象还是比较常见的(当然不一定只是一个epoch),很多时候可能两三个epoch以内就收敛或者出现过拟合现象了。有必要审视一下什么是过拟合。简单的讲,当训练时在训练集损失持续下降而测试集损失开始上升时可以认为出现了过拟合。从模型参数的角度出发又该怎么理解过拟合呢?这篇论文分析One-Epoch现象时的观点挺好的:模型参数过度拟合了训练数据。当然,过度拟合训练数据的原因可能是多样的,比如数据单一、任务简单、模型参数过多。以数据稀疏性为例,这是普遍存在的一个问题。离散特征通常存在长尾问题,一个离散特征的某个取值占据了大头,其他很多取值的样本数量过少。这种情况下模型主要在学习高频类别的嵌入,中低频的嵌入学习的不太充分,也就导致了:高频类别的嵌入更新较多,但也过度拟合了训练数据,中低频的更新较少出现了欠拟合的现象。看来,数据稀疏导致的过拟合问题中不仅有过拟合还伴随着某些参数的欠拟合。过拟合虽然是很常见的一个问题,但是实际中导致该问题的原因还是挺多的,实践中还是要好好分析啊(有时间一定好好分析!🙂)。
DIFFERENTIAL TRANSFORMER
一些实验证明LLM难以从上下文中准确到检索关键信息,经常过度关注不相关的上下文。具体来说,模型分配给正确答案的权重很低,同时过度关注不相关的上下文,最终淹没了正确答案,如下图:
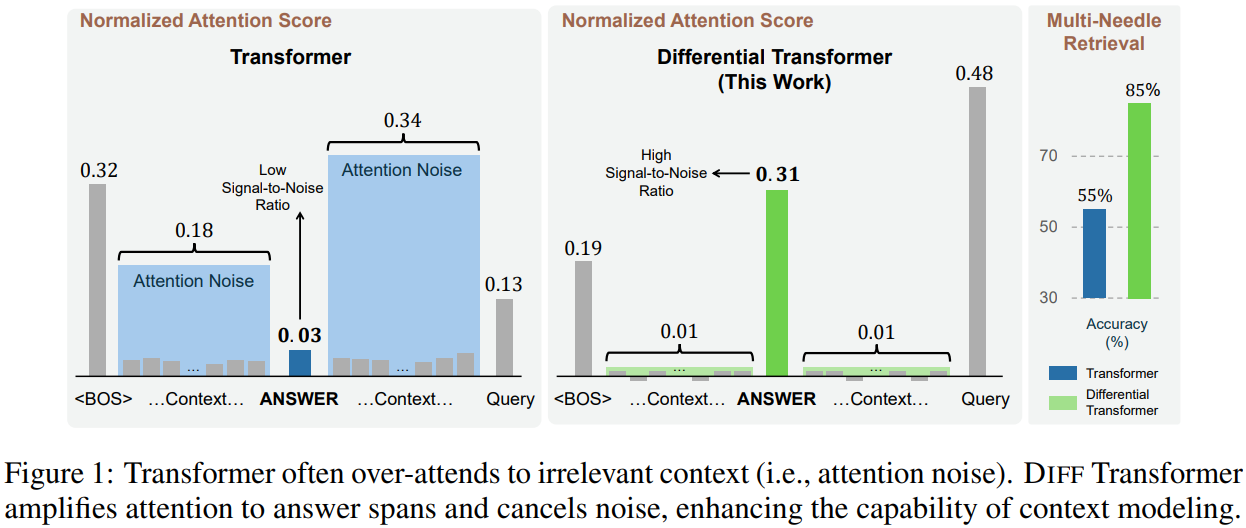
针对这个问题,论文提出了Differential Transformer(DIFF Transformer),对Transformer的注意力模块进行改造,增强对相关上下文的关注,并减少噪声干扰,从而提高模型在各种语言模型任务中的表现,特别是在大规模模型和长上下文处理方面。
DIFF Transformer引入了一种差异注意力机制,通过计算两个独立的softmax注意力矩阵之间的差值来计算注意力分数,从而减少噪声,具体方式如下图所示:
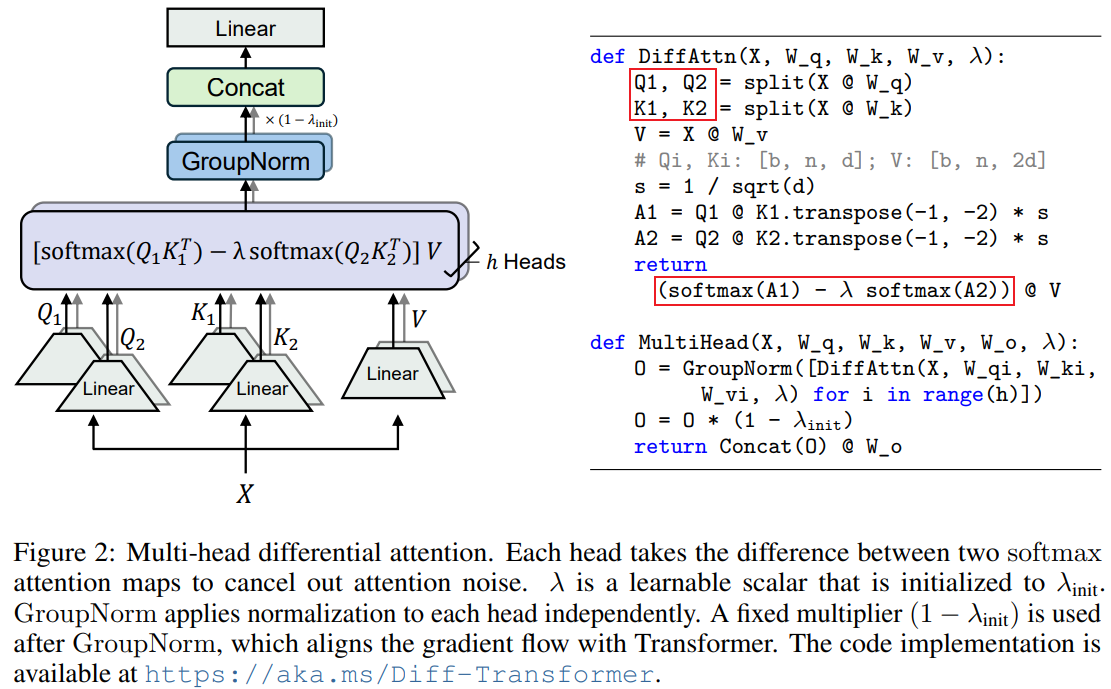
浅评。
论文比较吸引我的一点是其希望模型更关注输入中关键的信息,这个问题是实际应用时常出现的一个问题。为此,之前我也关注过Keyword-attention和匹配矩阵之类的方案,这些方案虽然整体上对效果有一定提升,但是在关键问题上好像并没有太大的缓解。不引入监督信号,只依赖模型自身去学习差异,Diff Attention真的能给关键内容更高的权重吗?或许效果的提升来源于模型参数的增加?要是论文中有在Encoder-Only模型上的实验就好了。
Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection
检索到的上下文过长,是检索增强生成时常见的一个难点,不仅导致输入LLM的上下文过长增大了推理的压力,通常也存在较多不相关的噪音。论文提出了Sparse RAG,通过稀疏性减少计算成本,仅在高度相关的缓存上进行自回归解码,以提高推理效率并改善生成质量。
Sparse RAG通过并行编码检索文档消除了长距离注意力带来的延迟,并使LLMs能够通过自回归方式仅关注高度相关的缓存,这些缓存是通过特殊控制标记提示LLMs选择的。该方法将文档评估和响应生成合并为单一过程,显著减少了解码过程中加载的文档数量,加速了推理过程,并提高了模型对相关上下文的关注,从而提升了生成质量。具体步骤包括:
- 并行编码检索到的文档,消除了检索文档的长距离注意力引入的延迟。
- 使用特殊的控制标记提示LLMs评估每个检索到的上下文的相关性。
- 根据相关性评分,选择性地加载关键值缓存中的文档进行解码。
- 在解码过程中,通过减少加载的文档数量来降低延迟,并提高模型对相关上下文的关注,从而提高生成质量。
这一块主要是对注意力的改进:block-wise注意力 和 每对question-检索文档单独计算位置编码。在这两块的基础上就可以复用评估相关性时的cache了,也就是速度提升的来源。
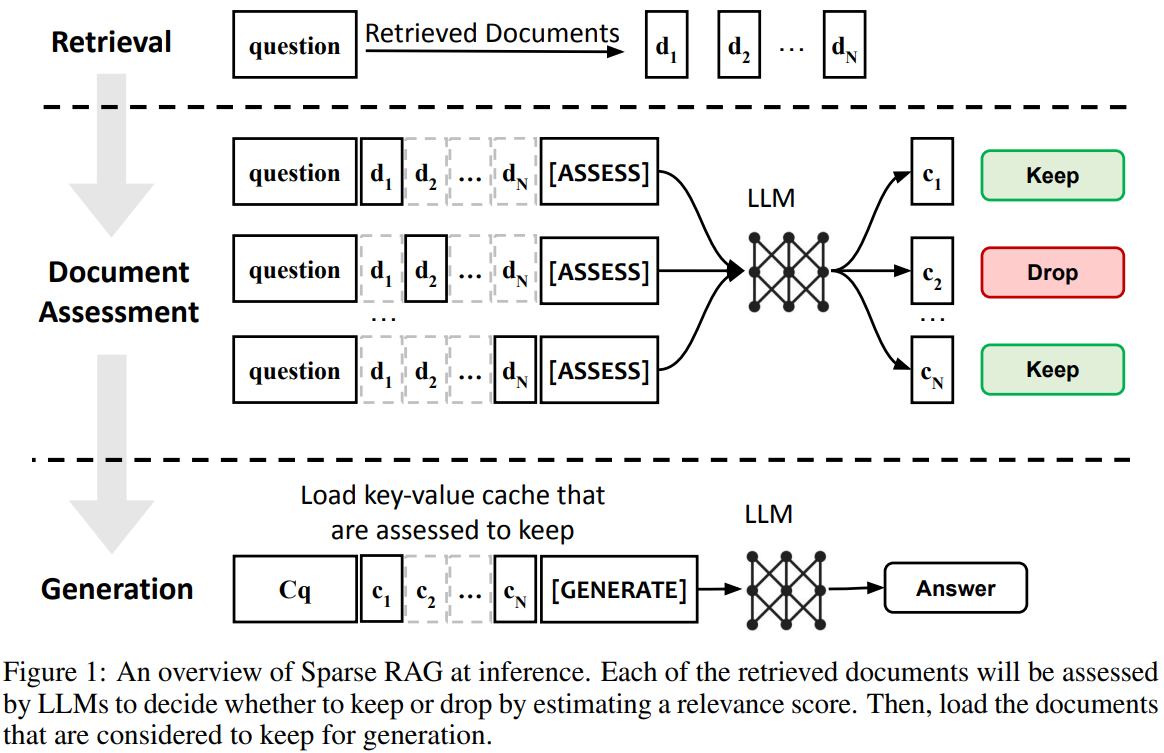
浅评:
这效果是不是等同于在检索后加个排序阶段过滤一些不相关的内容再进行生成?看论文里评估相关性时也是用生成的方式,更多的可能是工程实践上的优化。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号