论文速读纪录 - 202408
 新鲜出炉的八月份论文阅读记录
新鲜出炉的八月份论文阅读记录
特别鸣谢kimi,以下论文均在kimi辅助下阅读。
目录
- RMIB: Representation Matching Information Bottleneck for Matching Text Representations
- AttentionRank: Unsupervised keyphrase Extraction using Self and Cross Attentions
- ANSWERING COMPLEX OPEN-DOMAIN QUESTIONS WITH MULTI-HOP DENSE RETRIEVAL
- APPROXIMATE NEAREST NEIGHBOR NEGATIVE CONTRASTIVE LEARNING FOR DENSE TEXT RETRIEVAL
- CogLTX: Applying BERT to Long Texts
- How to Fine-Tune BERT for Text Classification?
- Optimizing E-commerce Search: Toward a Generalizable andRank-Consistent Pre-Ranking Model
RMIB: Representation Matching Information Bottleneck for Matching Text Representations
来自不同域的文本,经过表征后得到的向量表示是不对成的,作者基于信息瓶颈(Information Bottleneck,IB)提出了RMIB,通过匹配文本表示的先验分布来缩小其分布范围,从而优化信息瓶颈。具体的,主要在模型学习过程中增加了以下两项约束:
- 文本表示之间交互的充分性。
- 单一文本表示的不完整性。
看了一眼代码,论文的优化点主要体现在损失函数上,如下图所示:
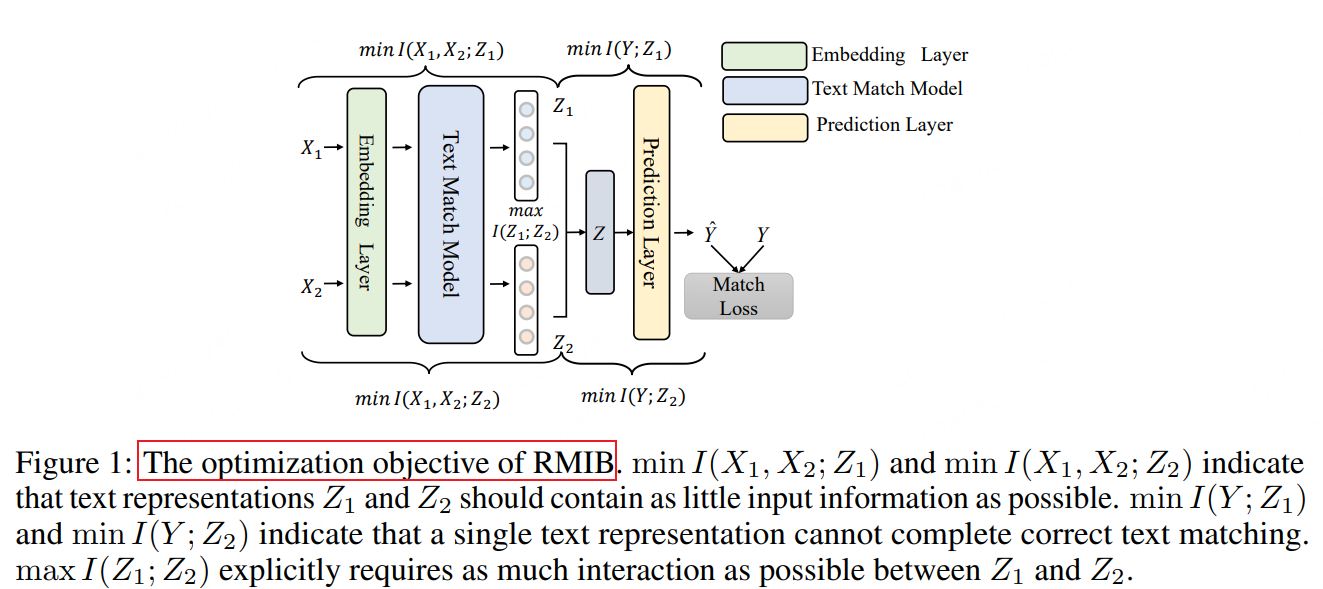
损失函数可以写为:
改写成通俗易懂的:
这篇论文吸引我的是其中提到的非对称文本匹配,概述一下论文中提到的这种场景:
- 领域差异。比如医学领域和计算机科学领域。
- 数据分布差异。同一领域内的数据也可能存在分布差异,比如搜索里用户query偏口语且更短,文档则更规范也更长。
- 任务差异。比如问答,长短文本匹配等。
最近在做文本匹配,刚好遇到了长短文本匹配的问题,感觉这篇论文会有点帮助,后面有时间了可以试一试。🙈
AttentionRank: Unsupervised keyphrase Extraction using Self and Cross Attentions
- 2021 EMNLP
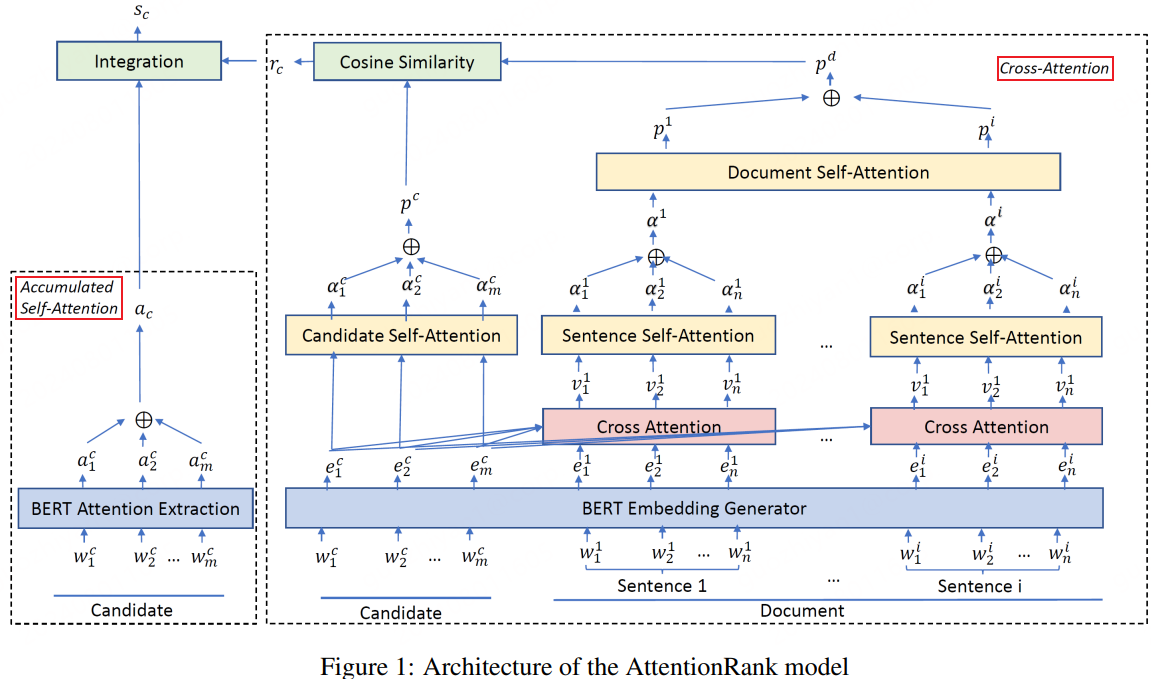
论文提出了一种无监督的关键短语抽取方法AttentionRank,在PLM的基础上计算了两种注意力:
- 自注意力(Self-Attention) :用于确定一个候选短语(通过词性标注,名词作为候选)在句子上下文中的重要性。
- 交叉注意力(Cross-Attention) :计算候选短语与文档内其他句子之间的语义相关性。
整个过程:
- 给定输入的文档,通过PoS标注识别出文本中的名词类的词,再基于NLTK生成名词性的候选短语。
- 通过自注意力计算每个候选短语在句子中的注意力权重。
- 通过交叉注意力计算每个候选短语与文档的注意力权重。
- 结合自注意力权重和交叉注意力权重,计算候选短语最终的权重。
模型结构如下(这图做的有点糙):
ANSWERING COMPLEX OPEN-DOMAIN QUESTIONS WITH MULTI-HOP DENSE RETRIEVAL
- https://arxiv.org/pdf/2009.12756,ICLR 2021, Facebook.
提出了一种多跳稠密检索方法,用于回答开放领域的复杂问题,主要面向的复杂问题是多跳问题。方案是:迭代地编码问题和先前检索到的文档作为查询向量,并使用高效的最大内积搜索(MIPS)方法检索下一个相关文档。大致流程如下:
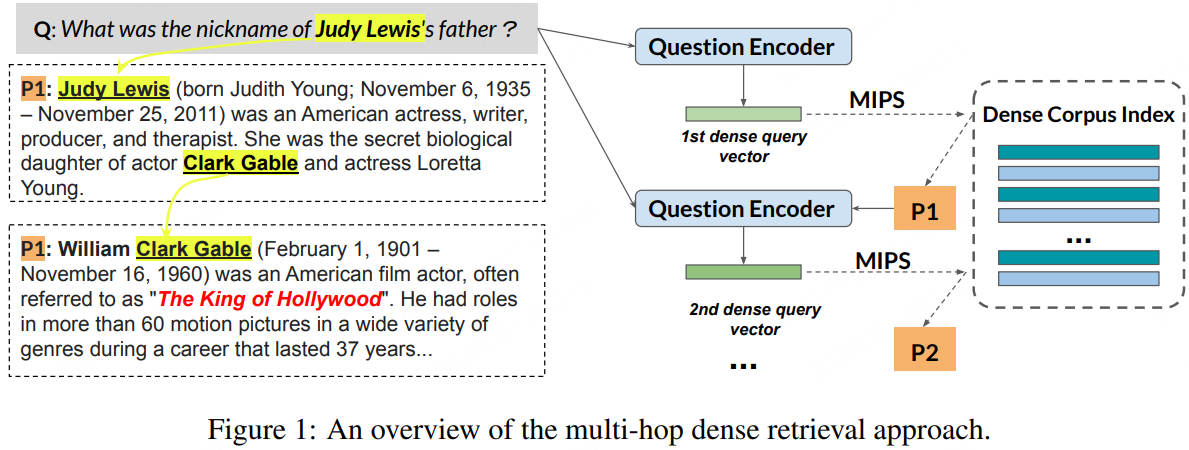
偶然之间看到了这篇论文,虽然是21年的,但感觉已经是“上古”的方法了(自从LLM霸榜问答领域),现在应该基本都上LLM了吧😂~
APPROXIMATE NEAREST NEIGHBOR NEGATIVE CONTRASTIVE LEARNING FOR DENSE TEXT RETRIEVAL
- https://arxiv.org/pdf/2007.00808,2020 Microsoft
针对稠密检索(Dense Retrieval)中一个主要的学习瓶颈问题:DR任务训练时通常采样batch内负采样,这些负样本计算损失时梯度较小,对模型的学习帮助不大,且不同batch间样本分布差异大,导致学习过程中梯度方差大,学习过程不稳定。
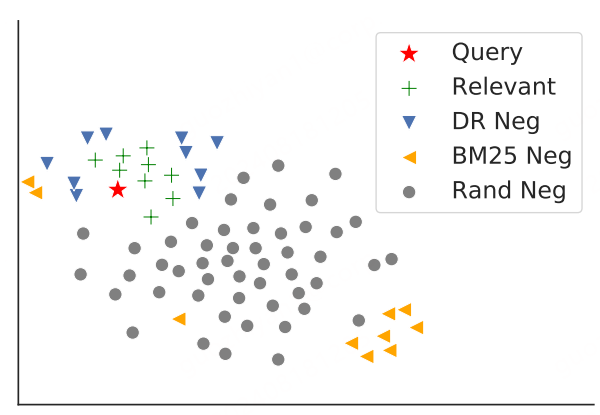
除此之外,DR任务对负样本的要求更高。(插句题外话,在信息漏斗系统中,越靠近底层,越是负样本的艺术?越靠近上层越是特征的艺术?当然是在其他环节构造合理的情况下)DR阶段要能区分各种类型的负样本,如下图所示,DR要能区分相关和不相关,但是不相关可以有很多种维度,比如字面不相关、字面相关但是语义不相关、以及语义上难以区分的不相关。总的来说,DR见过的东西要尽可能全面,接近实际的分布。论文要解决的问题也很直接:batch内负采样太简单,既不符合实际分布,也不利于模型学习。
对此,论文提出了ANCE(Approximate nearest neighbor Negative Contrastive Learning),基于已经优化过的DR模型构建ANN索引来选择全局负样本,训练流程如下:
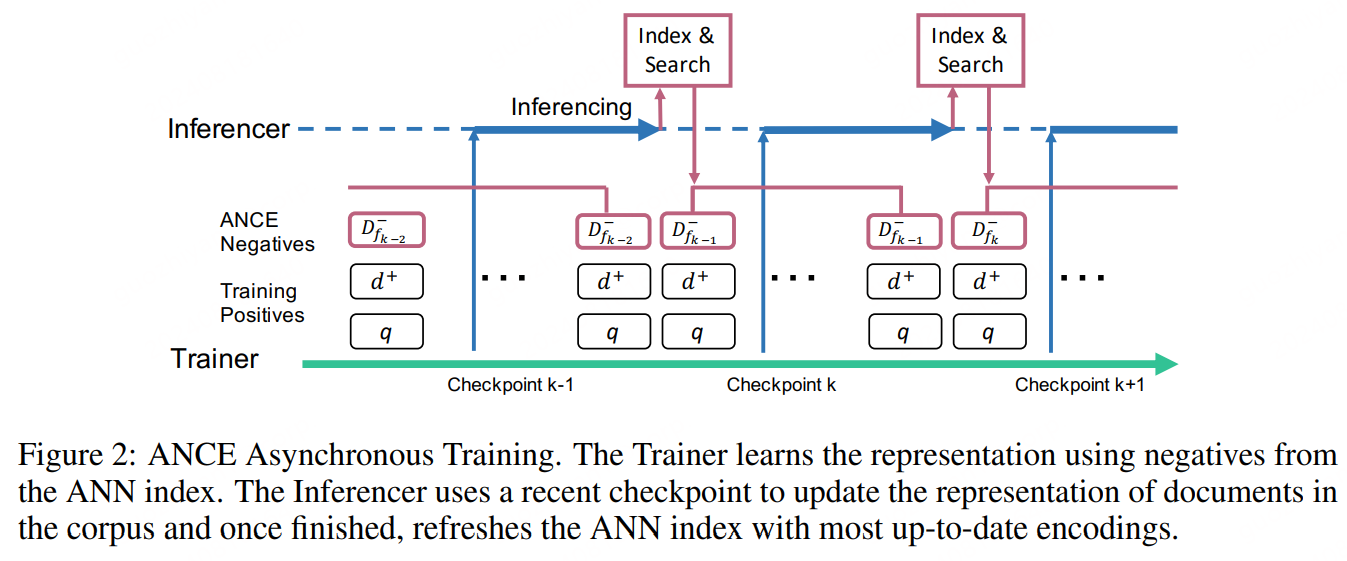
CogLTX: Applying BERT to Long Texts
通常,BERT是难以处理长文本,原因如下:
- 输入长度限制。BERT的输入最大长度通常是512(虽然BERT的位置编码是正余弦的,但训练时输入长度通常是512以内的),关键内容可能出现在512范围之后,或关键内容之间的距离会超过512。

- 时间限制。BERT中的自注意力时间复杂度是长度的平方,长文本的计算复杂度可能是难以接受的。
一些处理长文本的方法:
- 截断法。
- 滑动窗口。将长文本分成多块,分别计算后再池化。
- 压缩法。类似于序列建模,逐步处理并进行压缩。
- 魔改注意力。如稀疏注意力、滑窗注意力(sliding window attention)等。
针对以上问题,论文提出了CogLTX(Cognize Long TeXts),核心思想:类比人类处理信息的方式,CongLTX引入MemRecall从长文本中识别关键的文本块,把这些关键内容作为模型的输入。CogLTX依赖的一个基本假设:对于大部分NLP任务,只依赖源文本中的一部分关键的句子即可。具体的讲:CogLTX引入了MemRecall(是线上可以是另一个BERT模型,与实际要用的BERT模型联合训练)来抽取文本中的关键block。MemRecall的工作流程如下图:
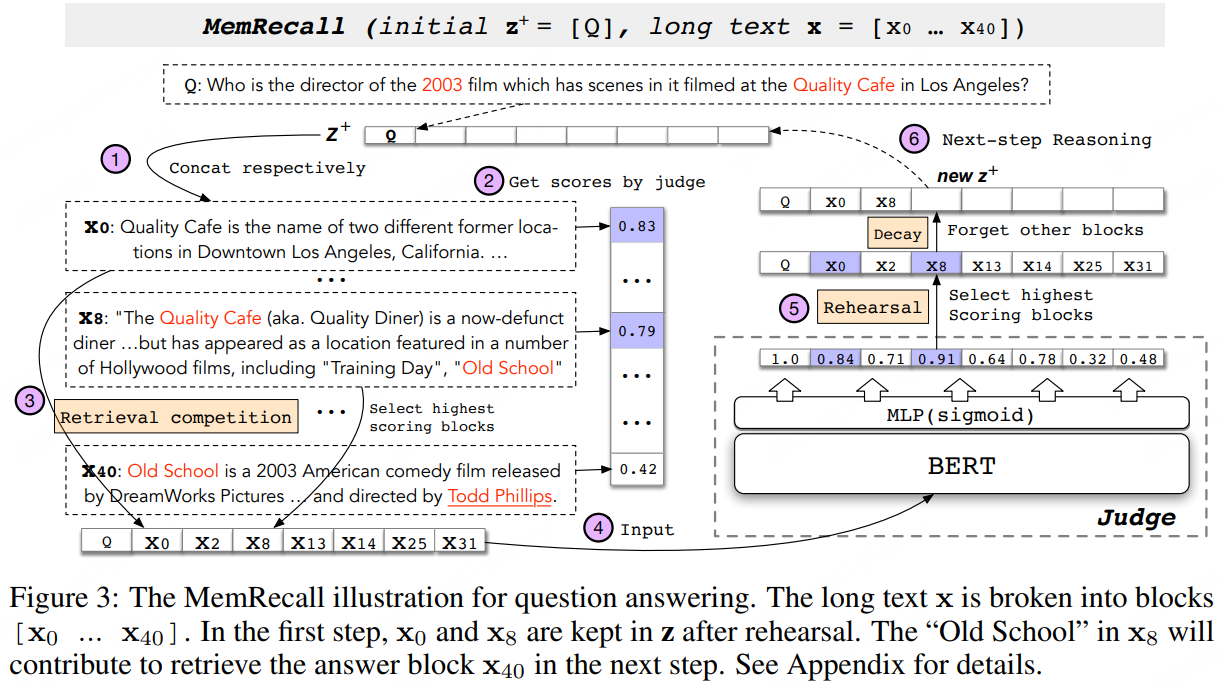
这篇论文积攒了很久,主要是为了解决当时将BERT应用于长文本场景时的一些问题,避免无关内容对目标的影响。虽然现在都开始推更大的模型、更长的上下文了,但是在实际的应用场景中这种小一些的模型还是很有用武之地的。以后有机会的可以实践一下。
How to Fine-Tune BERT for Text Classification?
老早积攒的一篇论文了。BERT在NLP领域的应用无需多言,即使在大模型火热的今天也依然难以替代。作为一个半路出家的NLPer,还是有必要进补一下这些利器的知识的。
BERT作为encoder模型的代表,常用在判别类型的任务中,如文本分类、相似性计算、摘要抽取等任务中,用于学习token或句子级别的表征。这篇论文探讨了如何对BERT模型进行微调,以用于文本分类任务。从一个预训练的BERT开始,到一个适用于目标任务的模型,通常有以下三步:
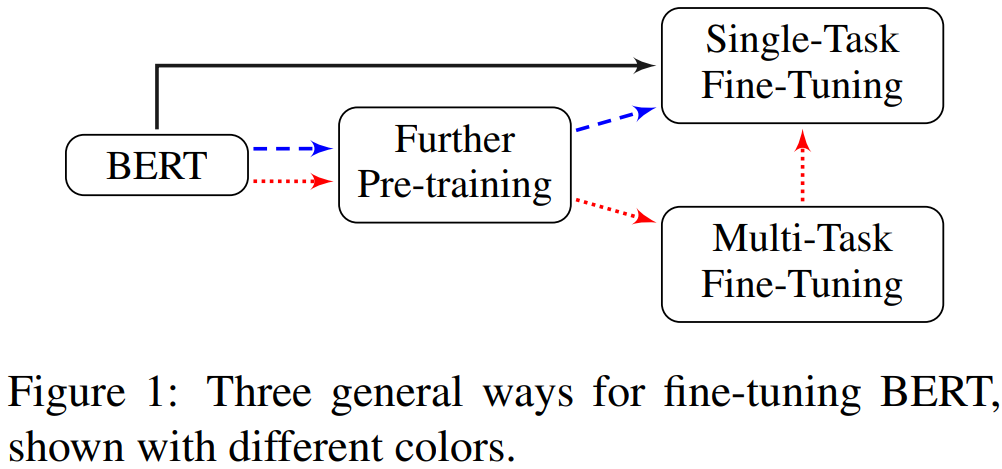
-
再预训练。在目标场景的大量语料下,再来一次预训练,让模型适配目标场景下的数据。这一步的作用比较好理解,预训练的模型一般都是在通用语料下训练的,可能缺乏一些领域内的数据,比如要应用在法律领域,需要通过再预训练让模型理解领域内词汇的含义。
-
多任务微调。用目标域下的不同任务对模型进行微调,更进一步适配任务。为什么要加这个过程呢?其实也可以直接进行下一步骤,但是kimi的提醒下,进行多任务微调有以下作用:
- 提高泛化性:不同任务间共享底层的表示,模型可以学习到跨任务的通用特征,提高模型的泛化能力,避免过拟合。
- 知识迁移:如果某些任务的数据量较小,可以从数据量较大的任务中迁移知识,帮助模型更好地学习和适应小数据任务。
-
最终的微调。在实际应用的任务上进行微调。
Optimizing E-commerce Search: Toward a Generalizable andRank-Consistent Pre-Ranking Model
也是老早积攒的一篇论文了,关于京东商品搜索的粗排阶段的工作。
粗排,一个轻量的模块,在系统流程中主要起过滤(想起了ad-hoc和filter的对比)作用。之前的很多工作中,粗排的目标主要是和排序阶段的排序尽可能一致。针对这个问题,很多工作也做了一些讨论,粗排是否和精排越像越好,这里不做过多讨论。论文提出了可泛化的排序一致性粗排(Generalizable and RAnk-ConsistEnt Pre-Ranking Model ,GRACE)。主要有以下这么几个改进:
- 通过引入多个二分类任务来预测产品是否在rank阶段的前k个结果中,从而实现排序一致性。
- 通过对比学习,对所有产品的表示进行预训练,以提高泛化能力。
- 在特征构建和在线部署方面易于实施。
关于第一个改进的一些看法:
这样考虑还是有道理的,粗排本质上承担的是一个区分好、坏结果的责任,把坏结果过滤掉,把潜在的好结果给后续的环节。 但是其实也容易让人疑惑:对齐排序阶段不是更直接吗?毕竟如果不考虑性能的吗直接把排序模型放在粗排环节效果可能会更好? 那是否粗排就应该对齐精排呢?私以为还是不要过度对齐精排为好。主要有这么几个考虑:1)粗排、精排所处环节不同,输入的样本分布不同;2)点击的样本大概率是好结果,但是曝光未点击的不一定是坏结果,粗排若认为曝光未点击的为坏结果,那么存在位置偏差或其他bias导致的误伤;3)粗排过度以精排为目标,容易导致正反馈,点击对整个链路的影响会越来越大,对缺少点击的好结果及冷启动不友好;4)粗排、精排模型复杂度不一样,弱化粗排的排序能力,强化其好坏区分能力或许更容易优化(?),也算是系统的解耦。
总结
不得不说,自己看的论文还是挺杂的以后还是要逐渐聚焦一点比较好🤣
这些主要是之前一直积攒下来没看到论文,拖延症要不得啊😣
另外,虽然本文是速度纪录,但是也不是特别速😢

