Pytorch深度学习踩坑记录
写这篇博文的主要目的是记录一下在使用Pytorch做深度学习项目时踩的一些坑,警醒自己,帮助他人😁😀
1 RuntimeError: No CUDA GPUs are available
明明有GPU,而且我的CUDA也装好了,怎么会出这么个错误呢?
为了确保我的显卡和CUDA都没问题,我试了下这个:
import torch
torch.cuda.device_count()
# 1
torch.cuda.is_available()
# True
我又试了下这个:nvidia-smi,也是正常的,那是为什么呢?😦
几经辗转,可能是os.environ['CUDA_VISIBLE_DEVICES']设置的问题,可以使用nvidia-smi查看自己的显卡的编号,例如我有两张显卡,编号为0,1,那么则设置:os.environ['CUDA_VISIBLE_DEVICES'] = "0,1",问题解决😜
2. RuntimeError: CUDA out of memory. Tried to allocate xxx (GPU 0; xxx total capacity; xxx already allocated; xxx free; 7.43 reserved in total by PyTorch)
出现这么个问题,很显然,CPU的现存不够了!😭
要解决这个问题有一个很简单粗暴的方法:加显卡!或者换个现存更大的显卡!那么如果没💰呢?
- 减小训练数据的
batch_size - 一个可能有用的方法:
torch.cuda.empty_cache()。关于这个方法的一些情况可以在About torch.cuda.empty_cache()了解 - 如果你的
CPU、内存很强的化,试试在CPU上训练模型
3. To use CUDA with multiprocessing, you must use the 'spawn' start method
这个错误出现在我使用多进程利用CUDA进行训练的时候。
光从报错来看,似乎提到了该怎么解决这个问题:use the 'spawn' start method,但咋一看还是摸不清头脑,具体该怎么解决这个问题呢?
import torch.multiprocessing as mp
mp.set_start_method('spawn')
if __name__ == "__main__":
...
model = ...
data = ...
train(model, data)
...
关于在pytorch中使用多进程,可以参考官方的说明:MULTIPROCESSING BEST PRACTICES,这这个说明里还给出了一个完整的例子:example。
4. RuntimeError: CUDA error: initialization error
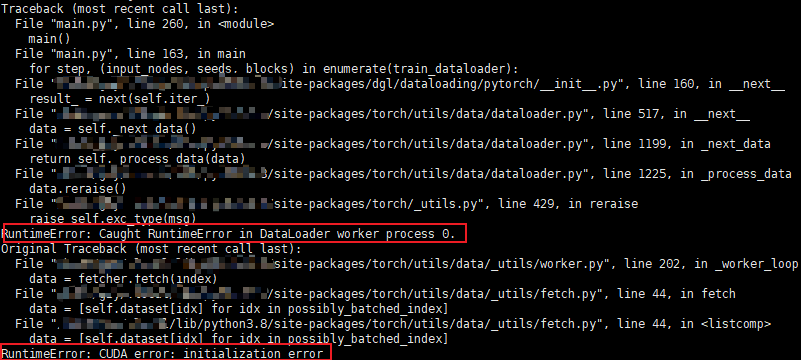
错误来自使用gpu训练模型时,当时使用的是dgl框架训练图神经网络,使用了其中的NodeDataLoader加载节点数据,先是报了Caught RuntimeError in DataLoader worker process 0.的bug,接着就报了CUDA error: initialization error,报错的栈帧如图:
在NodeDataLoader初始化时,有一个num_workers参数,我设置为了4,改成默认值(0)后这个bug就消失了。从错误信息来看,应该是CUDA的初始化问题,而且把num_workers设置为默认值后就正常了,猜测是因为多线程操作问题导致的,具体的没有进行深究,但是在github上找到了这个问题 CUDA error (3): initialization error (multiprocessing) #2517。

