

Redis的持久化之RDB
1.什么是Redis的持久化
Redis是一种高级key-value数据库,是一个高性能的(key/value)分布式内存数据库,基于内存运行并支持持久化的NoSQL数据库,所以Redis的所有数据都是保存在内存中,为了Redis提供了一种机制可以把数据保存到磁盘上(可永久保存的存储设备中),以便数据恢复和永久保存,而这种机制就是持久化。
redis提供两种方式进行持久化,一种是RDB持久化,另外一种是AOF(append only file)持久化
2.RDB
2.1什么是RDB
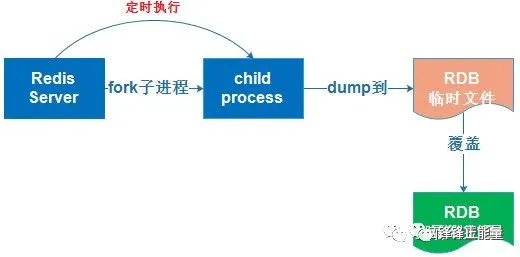
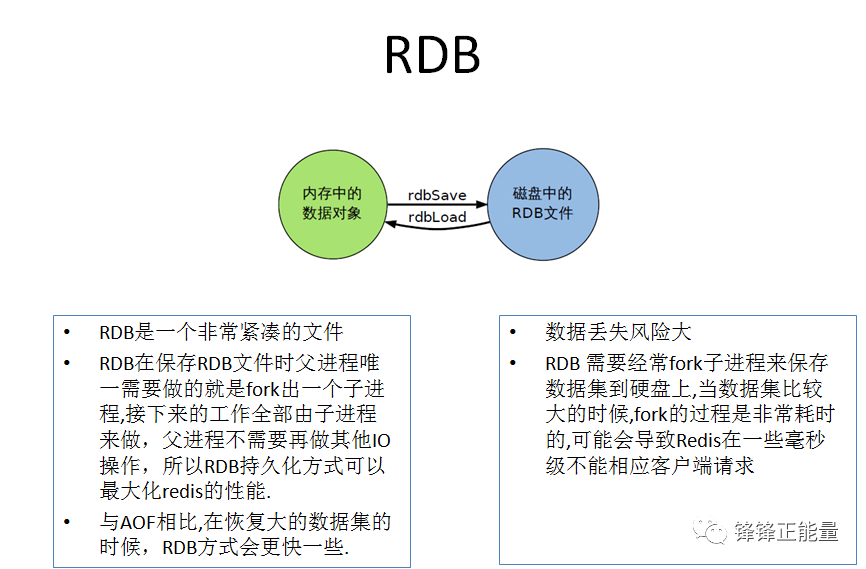
1.RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。(在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里)
2.实现类似照片记录效果的方式,就是把某一时刻的数据和状态以文件的形式写到磁盘上,也就是快照。这样一来即使故障宕机,快照文件也不会丢失,数据的可靠性也就得到了保证
3.这个快照文件就称为RDB文件(dump.rdb)其中,RDB就是Redis DataBase的缩写;
4.Redis的数据都在内存中,保存备份时它执行的是全量快照,也就是说,把内存中的所有数据都记录到磁盘中,一锅端。
2.2RDB持久化的原理
RDB持久化的原理:是Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
备注:Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
2.3RDB2触发机制的方式
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,那么就应该有一种触发机制,是实现这个过程。对于RDB来说,提供了三种机制:save、bgsave、自动化
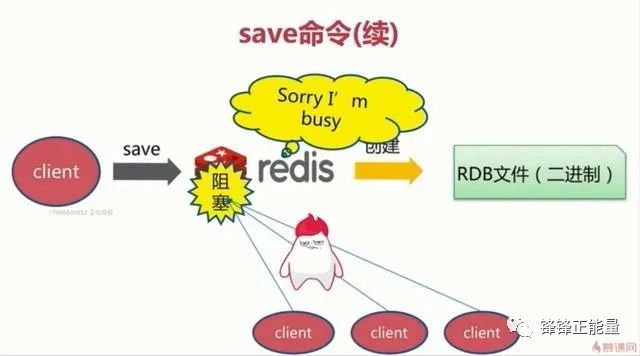
2.3.1save触发方式
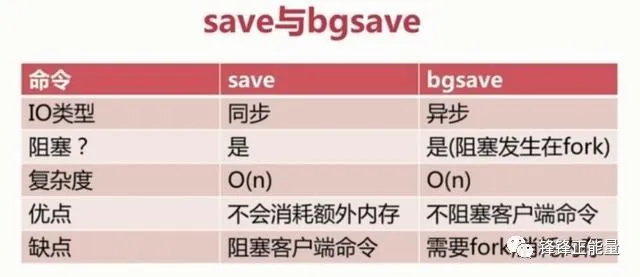
save触发方式会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止(save时只管保存,其它不管,全部阻塞)具体流程如下
2.3.2bgsave触发方式
使用bgsave触发方式时Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求,可以通过lastsave命令获取最后一次成功执行快照的时间
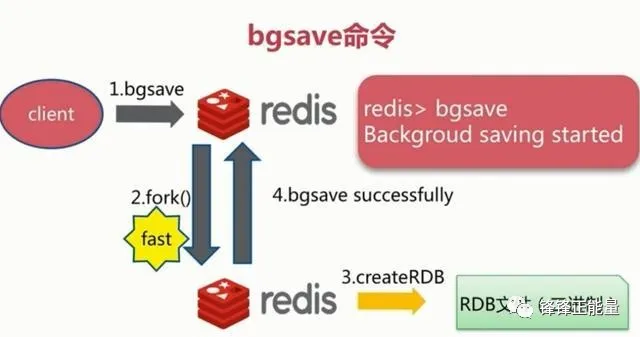
具体执行过程:是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。在实际开发中基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
*save与bgsave对比:
2.3.3自动触发
自动触发是由我们的配置redis.conf文件来完成的在redis.conf配置文件中,里面有如下配置

①save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。 比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。如果不需要持久化, 那么你可以注释掉所有的 save 行来停用保存功能默认如下配置: #表示900 秒内如果至少有 1 个 key 的值变化,则保存save 900 1#表示300 秒内如果至少有 10 个 key 的值变化,则保存save 300 10#表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000 ②stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败, Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上, 否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了 ③rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。 ④rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验, 但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。 ⑤dbfilename :设置快照的文件名,默认是 dump.rdb ⑥dir:设置快照文件的存放路径,设置快照文件的存放路径, 这个配置项一定是个目录,而不能是文件名
2.4RDB 的优势和劣势
2.4.1RDB的优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
(4)适合大规模的数据恢复
(5)对数据完整性和一致性要求不高
2.4.2RDB的劣势
(1)在一定间隔时间做一次备份,所以如果redis意外down掉的话,就
会丢失最后一次快照后的所有修改
(2)Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
2.5如何恢复与停止
恢复:
备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
CONFIG GET dir获取目录
停止
动态所有停止RDB保存规则的方法:redis-cli config set save ""
2.6RDB总结



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!