深入浅出Kafka(三)之消费者
1.Kafka消费者概述
1.消息消费者,向 Kafka broker 取消息的客户端
2.与生产者对应的是消费者, 应用程序可以通过KafkaConsumer来订阅主题, 并从订阅的topic中拉取消息。 每个消费者都有一 个对应的消费组。 当消息发布到主题后, 只会被投递给订阅它的每个消费组中的一 个消费者
3.单播消费:一条消息只能被某一个消费者消费的模式,类似queue模式,只需让所有消费者在同一个消费组里即可
4.多播消费:一条消息能被多个消费者消费的模式,类似publish-subscribe模式费,针对Kafka同一条消息只能被同一个消费组下的某一个消费者消费的特性,
要实现多播只要保证这些消费者属于不同的消费组即可
1.1Kafka 消费方式
1. pull(拉)模 式:consumer采用从broker中主动拉取数据, consumer 可以根据的消费能力以适当的速率消费消息。Kafka采用这种方式,缺点:如 果Kafka没有数据,消费者可能会陷入循环中,一直返回空数据。
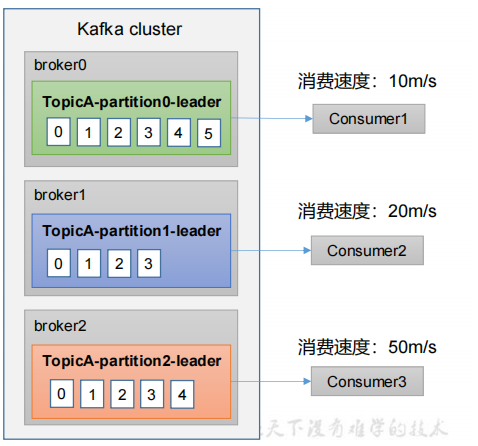
2.push(推)模式:Kafka没有采用这种方式,因为由broker决定消息发送速率,而且每个消费者的消费速率也不同,所以很难适应所有消费者的消费速率。
例如推送的速度是50m/s,Consumer1、Consumer2就来不及处理消息
3. 对于 Kafka 而言,pull 模式更合适,它可简化 broker 的设计,consumer 可自主控制消费消息的速率,同时 consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义
4.pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直等待数据到达。为了避免这种情况,可以在拉取请求中 设置允许消费者请求在等待数据到达的“长轮询”中进行阻塞(并且可选地等待到给定的字节数,以确保大的传输大小)
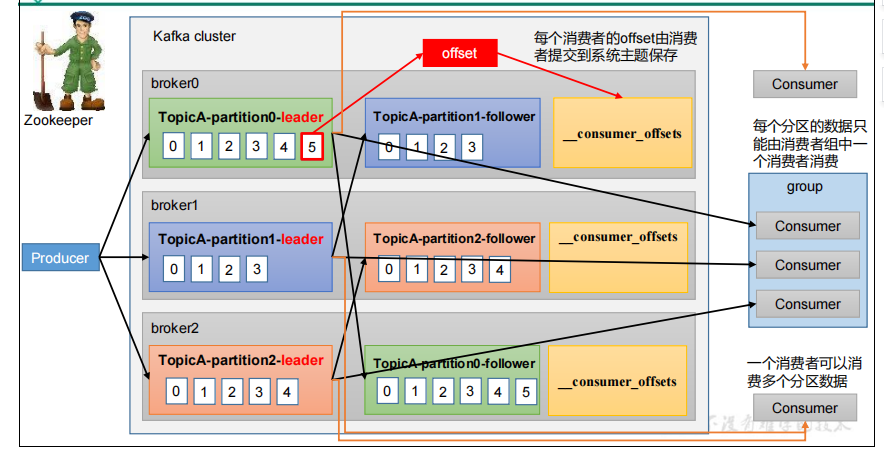
2. 消费者总体工作流程
3.消费者组原理
kafka使用一种消费者组(Consumer Group)机制,就同时实现了传统消息引擎系统的两大模型:如果所有的消费者实例都属于一个消费者组那就是点对点模型,如果所有消费者实例各自是独立的消费者那就是发布订阅模型。
3.1消费者组Consumer Group
1.消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同
2.每个Consumer属于一个特定的Consumer Group,并且每个消费者Consumer都有一个group id,group id相同的多个消费者自动成为一个消费者组;
3.所有的消费者都属于某个消费者组,对于某个分区而言,即消费者组是逻辑上的一个订阅者
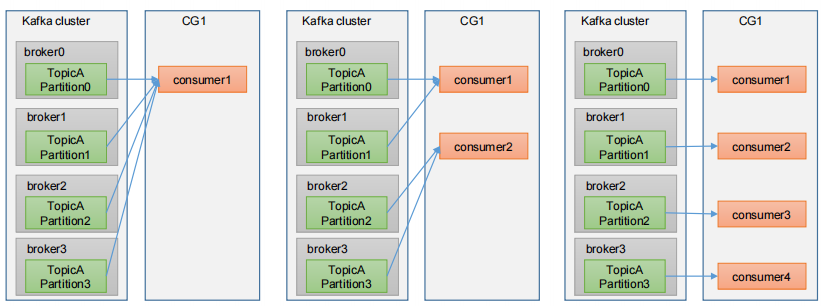
4.消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响
5.一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息
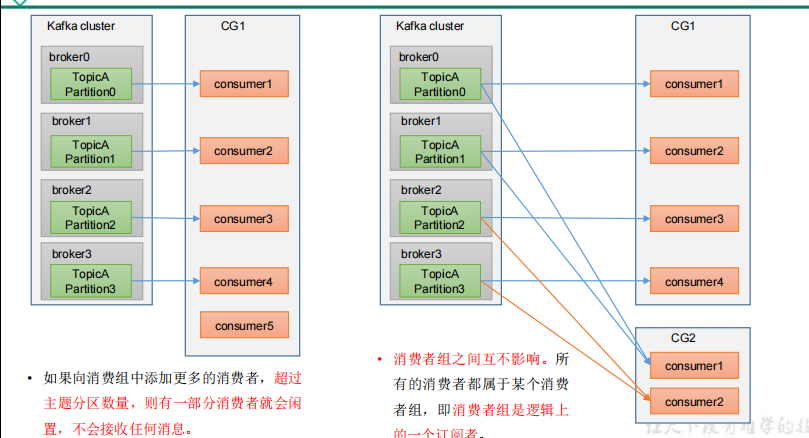
6.如果向消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息
3.2消费者组初始化流程
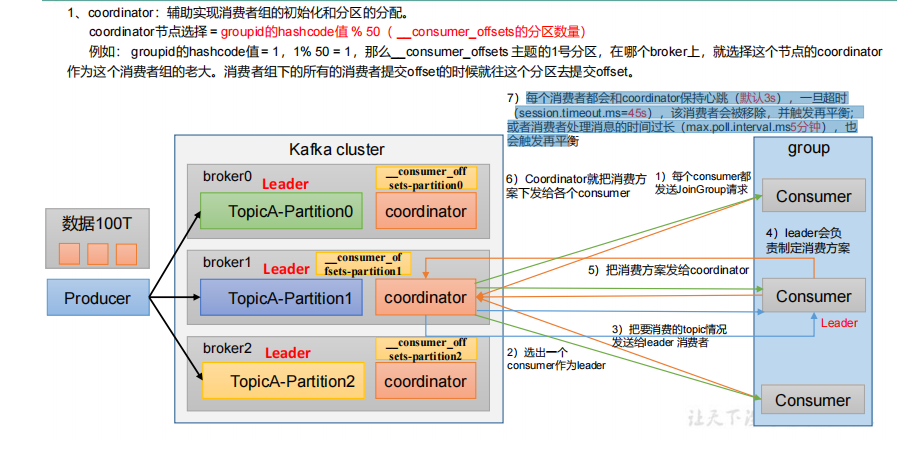
3.2.1 coordinator的选择
3.2.2消费者组的初始化和分区的分配
1.根据coordinator选择公式选择 协调器coordinator节点 ,然后每个consumer启动时会向kafka集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器GroupCoordinator,并跟其建立网络连接
2.在成功加入到消费组之后,每个consumer都给coordinator发送JoinGroup请求,
3.由coordinator节点选出一个consumer作为消费者leader 节点.
4.然后coordinator节点把所有消费者以及把要消费的topic情况发送给leader 消费者
5.消费者leader会负责制定消费方案(消费者如何消费消息,消费那个分区等信息),把消费方案发给coordinator
6.Coordinator就把消费方案下发给各个consumer
7.每个消费者都会和coordinator保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;或者消费者处理消息的时间过长(max.poll.interval.ms5分钟),也会触发再平横.
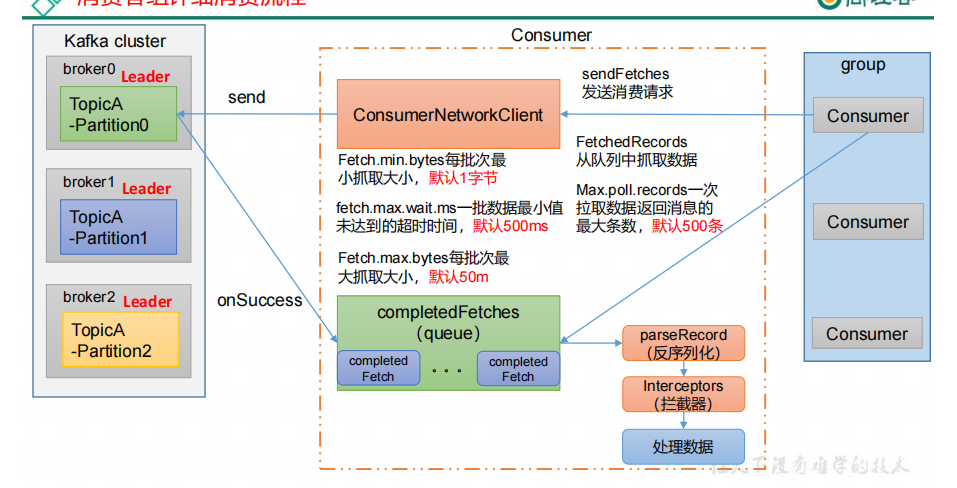
1.Fetch.min.bytes:每批次最小抓取大小,默认1字节
2.fetch.max.wait.ms:一批数据最小值未达到的超时时间,默认500ms
1)latest(默认) :只消费自己启动之后发送到主题的消息,earliest:第一次从头开始消费,以后按照消费offset记录继续消费,
2)auto.offset.reset最好不要设置为latest,因为如果分区内的数据未被消费过,这时消费者上线.会导致消费者无法消费到前面的数据,(当然也得看应用场景,如果认为这种情况的数据就该丢失,那当我没说)
3)auto.offset.reset设置为earliest时,可能会有重复消费的问题,这就需要消费者端做数据去重处理
3.3消费者常用API
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.Arrays; import java.util.Properties; public class MsgConsumer { private final static String TOPIC_NAME = "my-replicated-topic"; private final static String CONSUMER_GROUP_NAME = "testGroup"; public static void main(String[] args) { Properties props = new Properties(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094"); // 消费分组名 props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);
// 是否自动提交offset,默认就是true props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); // 自动提交offset的间隔时间 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); //props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); /* 当消费主题的是一个新的消费组,或者指定offset的消费方式,offset不存在,那么应该如何消费 latest(默认) :只消费自己启动之后发送到主题的消息 earliest:第一次从头开始消费,以后按照消费offset记录继续消费,这个需要区别于consumer.seekToBeginning(每次都从头开始消费) */ //props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); /* consumer给broker发送心跳的间隔时间,broker接收到心跳如果此时有rebalance发生会通过心跳响应将 rebalance方案下发给consumer,这个时间可以稍微短一点 */ props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000); /* 服务端broker多久感知不到一个consumer心跳就认为他故障了,会将其踢出消费组, 对应的Partition也会被重新分配给其他consumer,默认是10秒 */ props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000); //一次poll最大拉取消息的条数,如果消费者处理速度很快,可以设置大点,如果处理速度一般,可以设置小点 props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500); /* 如果两次poll操作间隔超过了这个时间,broker就会认为这个consumer处理能力太弱, 会将其踢出消费组,将分区分配给别的consumer消费 */ props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList(TOPIC_NAME)); // 消费指定分区 //consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0))); //消息回溯消费 /*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0))); consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));*/ //指定offset消费 /*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0))); consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);*/ //从指定时间点开始消费 /*List<PartitionInfo> topicPartitions = consumer.partitionsFor(TOPIC_NAME); //从1小时前开始消费 long fetchDataTime = new Date().getTime() - 1000 * 60 * 60; Map<TopicPartition, Long> map = new HashMap<>(); for (PartitionInfo par : topicPartitions) { map.put(new TopicPartition(topicName, par.partition()), fetchDataTime); } Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map); for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) { TopicPartition key = entry.getKey(); OffsetAndTimestamp value = entry.getValue(); if (key == null || value == null) continue; Long offset = value.offset(); System.out.println("partition-" + key.partition() + "|offset-" + offset); System.out.println(); //根据消费里的timestamp确定offset if (value != null) { consumer.assign(Arrays.asList(key)); consumer.seek(key, offset); } }*/ while (true) { /* * poll() API 是拉取消息的长轮询 */ ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n", record.partition(), record.offset(), record.key(), record.value()); } /*if (records.count() > 0) { // 手动同步提交offset,当前线程会阻塞直到offset提交成功 // 一般使用同步提交,因为提交之后一般也没有什么逻辑代码了 consumer.commitSync(); // 手动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后面的程序逻辑 consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { if (exception != null) { System.err.println("Commit failed for " + offsets); System.err.println("Commit failed exception: " + exception.getStackTrace()); } } }); }*/ } } }
3.4 生产经验——分区的分配以及再平衡
1、一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据,所以就需要分区的分配以及再平衡
3.4.1分区分配策略
1.Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。可以通过配置参数partition.assignment.strategy,修改消费者与订阅主题之间的分区分配策略
3.4.2分区分配策略之Range 以及再平衡
1.Range 是对每个 topic 而言的。首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序
2.通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区
3.例如1:假如现在有 7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2,
4.7/3 = 2 余 1 ,除不尽,那么 消费者 C0 便会多消费 1 个分区。假如 8/3=2余2,除不尽,那么C0和C1分别多消费一个
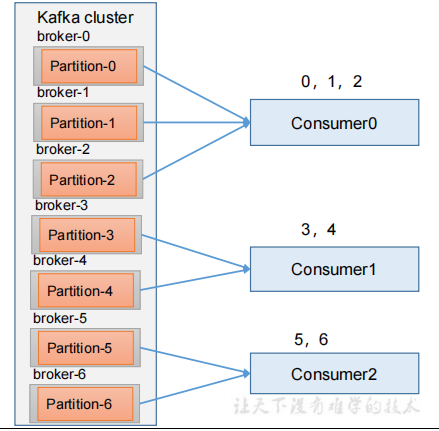
5.注意:如果只是针对 1 个 topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有 N 多个 topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费 N 个分区。容易产生数据倾斜
5.分区分配策略Range的再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)45s(session.timeout.ms=45s)消费者都会和coordinator保持心跳(默认3s)不能超过45s,一旦超时该消费者会被移除
3.4.3分区分配策略之RoundRobin以及再平衡
1.RoundRobin 针对集群中所有Topic而言,RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者
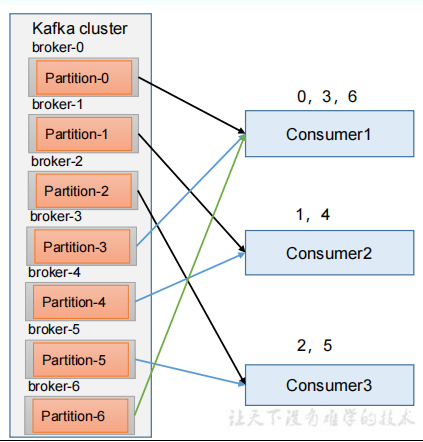
2.分区分配策略RoundRobin的再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)
结果:1 号消费者消费到 2、5 号分区的数据,2 号消费者消费到 4、1 号分区的数据, 0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 、6 和 3 号分区数据,分别由 1 号消费者或者 2 号消费者消费。
3.4.4分区分配策略之Sticky以及再平衡
4.offset 位移
4.1offset的默认维护位置
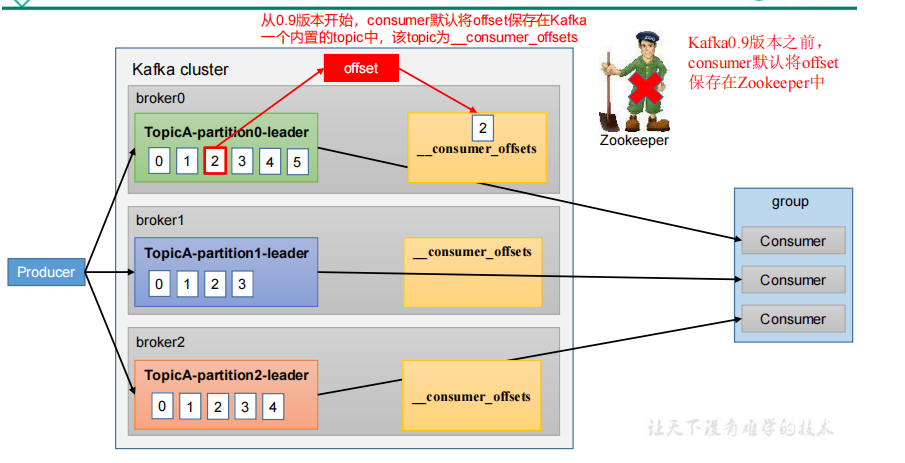
1.从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets;
2.Kafka0.9版本之前,consumer默认将offset保存在Zookeeper中
3.__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行清理,也就是每个 group.id+topic+分区号就保留最新数据
4.每个consumer会定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets
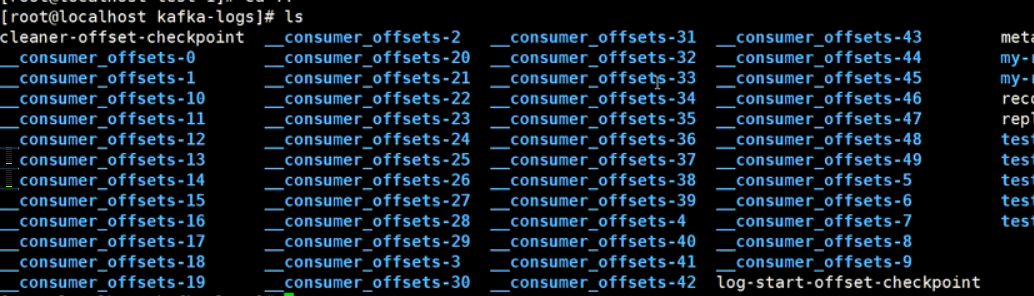
5.因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发
4.2 自动提交 offset
1.为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能
2.消费者会每隔一段时间地自动向服务器提交偏移量;
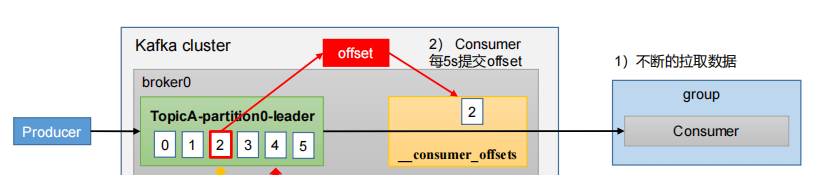
3.自动提交offset的相关参数:
4.2.1 重复消费
1.问题: 自动提交offset引起引起重复消费问题;已经消费了数据,但是 offset 没提交
2.问题的发生: Consumer每5s提交offset 如果提交offset后的2s,consumer挂了, 再次重启consumer,则从上一次提交的offset处继续消费,导致重复消费
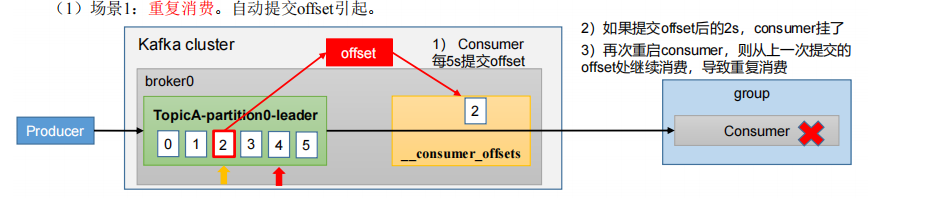
3.问题解决方案: 怎么能做到既不漏消费(后面讲)也不重复消费呢?详看消费者事务
4.3手动提交 offset
1.虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
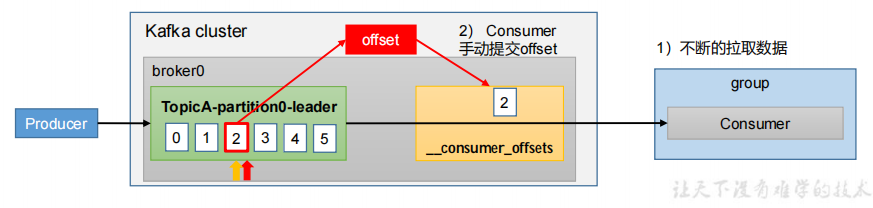
4.3.1commitSync(同步提交)
4.3.2commitAsync(异步提交)
4.3.3 漏消费
1.问题: 手动提交offset引起引起漏消费问题;先提交 offset 后消费,有可能会造成数据的漏消费
2.问题的发生: 当offset被提交时,数据还在内存中未落盘,此时刚好消费者线程被kill掉或者挂了,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。

3.问题解决方案: 怎么能做到既不漏消费(后面讲)也不重复消费呢?详看消费者事务
4.4.指定 Offset 消费
1 .当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
2.auto.offset.reset = earliest | latest | none 默认是 latest
(1)earliest:自动将偏移量重置为最早的偏移量,--from-beginning。
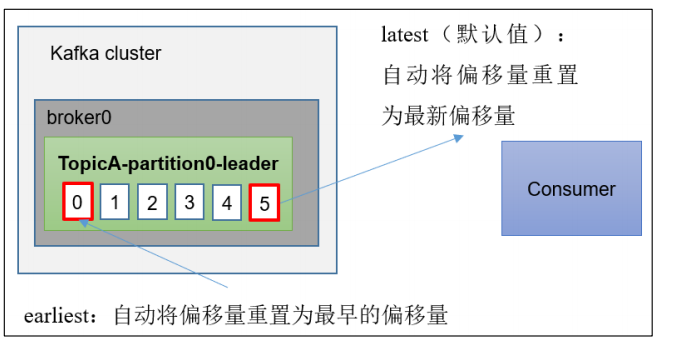
3.如何实现
Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map); for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) { TopicPartition key = entry.getKey(); OffsetAndTimestamp value = entry.getValue(); if (key == null || value == null) continue; Long offset = value.offset(); System.out.println("partition-" + key.partition() + "|offset-" + offset); System.out.println(); //根据消费里的timestamp确定offset if (value != null) { consumer.assign(Arrays.asList(key)); consumer.seek(key, offset); } }*/
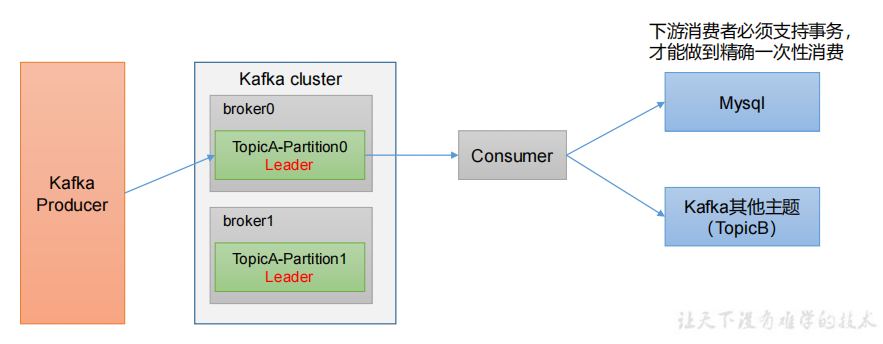
5.生产经验——消费者事务
6.生产经验——数据积压(消费者如何提高吞吐量)
1.情况1:由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致broker积压大量未消费消息。
2.情况2:线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息
3.情况1解决方案:可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。
4.情况2解决方案:
1)如果是Kafka消费能力不足:则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数 = 分区数(两者缺一不可)
2)如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压
3)优化参数1:fetch.max.bytes :默认 Default: 52428800(50m)消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (brokerconfig)or max.message.bytes (topic config)影响
4)优化参数2:max.poll.records:一次 poll 拉取数据返回消息的最大条数,默认是 500 条


 浙公网安备 33010602011771号
浙公网安备 33010602011771号