带领域变异的多模态优化差分进化算法(DE/NCDE/NSDE/)
文献《Differential Evolution with Neighborhood Mutation for Multimodal Optimization》核心技术点总结,网上几乎没有关于多模DE算法的博文,主要是自己复习总结,也和大家一起学习。文章现在读不难,依然记得大一的我,要理解一篇这种文章,简直太难了,看那篇DE文章就不知道看了多久。
DE(Differential Evolution)回顾
DE是一种模拟生物进化的随机模型,通过反复迭代,使得那些适应环境的个体被保存了下来。DE保留了基于种群的全局搜索策略,采用实数编码、基于差分的简单变异操作和一对一的竞争生存策略,降低了遗传操作的复杂性。同时,DE特有的记忆能力使其可以动态跟踪当前的搜索情况,以调整其搜索策略,具有较强的全局收敛能力和鲁棒性。
DE 算法主要用于求解连续变量的全局优化问题,其主要工作步骤与其他进化算法基本一致,主要包括变异(Mutation)、交叉(Crossover)、选择(Selection)三种操作。算法的基本思想是从某一随机产生的初始群体开始,利用从种群中随机选取的两个个体(\(r_1,r_2\))的差向量作为第三个个体的随机变化源(\(r_1-r_2\)),将差向量加权后(权重\(F\))按照一定的规则与第三个个体求和(\(r_3+F(r_1-r_2)\))而产生变异个体,该操作称为变异。然后,变异个体与某个预先决定的目标个体(种群中第\(i\)个个体)进行参数混合,生成试验个体\(i'\),这一过程称之为交叉。如果试验个体\(i'\)的适应度值优于目标个体\(i\)的适应度值,则在下一代中试验个体取代目标个体,否则目标个体仍保存下来,该操作称为选择(利用\(Fitness函数\))。在每一代的进化过程中,每一个体矢量作为目标个体一次,算法通过不断地迭代计算,保留优良个体,淘汰劣质个体,引导搜索过程向全局最优解逼近。
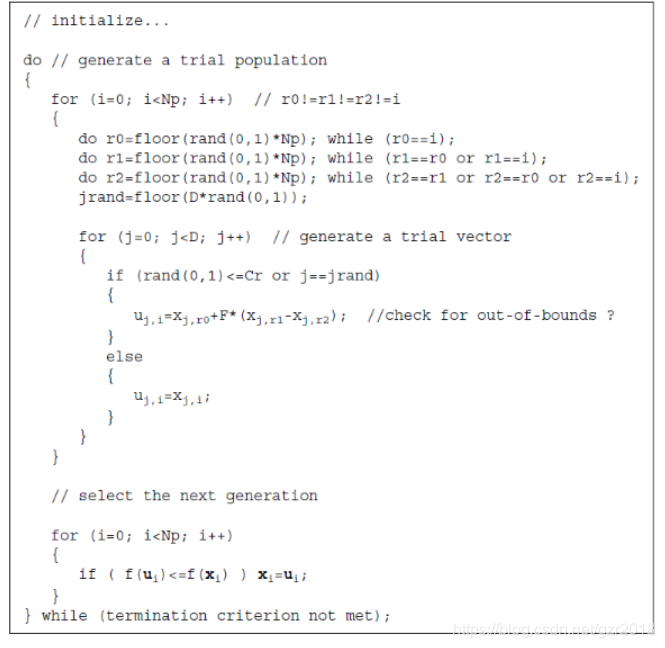
C语言伪代码
niching
小生境技术:在一个种群中形成子种群,每个子种群目标是找到一个最优解,整个种群找到多组最优解。CDE和SDE都是使用niching技术的DE。
CDE(Crowding DE )
CDE策略是使用标准DE生成子代,这个子代和当前种群中最相似的个体比较,保留更优的个体。标准DE的是把尝试的个体与父代比较,选择保留更优的个体。所以CDE就是一种拥挤策略,少保留相似的。

SDE(Species-Based DE)
首先确定几个名词:
- radius parameter \(r_s\):Euclidean distance from the center of a species to its boundary.
- species seed:The center of a species.
利用种群相似度分组,平均复杂度\(O(N^2)\)
- SDE就是把种群利用相似度分组,首先按照适应度排序,把第一个最优个体作为第一个种群的中心,其他个体如果和中心距离小于\(r_s\),则归纳到同一组,否则剩下的按照相同方式分组。
- 对每个种群,执行全局DE:
如果一个种群数量小于\(m\),那么随机生成新的个体加入其中,需要满足半径参数要求。
如果子代个体fitness和species seed相同,则用随机个体取代该子代个体。

带领域的DE(Neighborhood Based Differential Evolution)
在标准DE中,运行任意两个个体形成差分向量,这种策略对于单个全局最优解表现很好,但是对于多模问题,如果使用全局DE,在最终搜索阶段对多峰优化所需的多个局部收敛是无效的。虽然niching技术解决了一部分这种问题,但是例如SDE这种技术太过依赖niching的参数设置。
领域DE的一个最重要的概念就是领域变异(neighborhood mutation)。
在邻域变异中,差分向量的生成仅限于用欧几里德距离度量的若干个相似个体。核心思想是:
对于NP个个体,计算每个个体距离最近的\(m\)个个体,形成一个子种群,在子种群中选择\(r_1,r_2,r_3\)三个不同个体,和第i个个体选择形成子代\(u_i\)。再使用差分小生境策略选择NP个最佳个体。

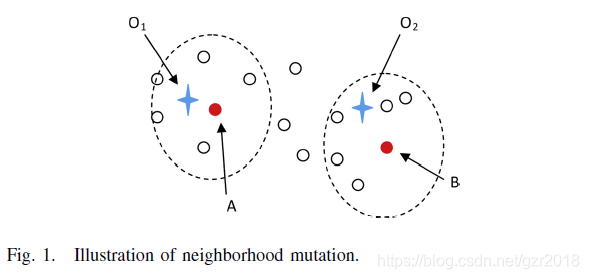
下图展示为什么领域变异更加有效,A和B是当前点,\(O_1和O_2\)是两个peak,对于A,B点使用领域内的差分变异向量更可能locate到\(O_1和O_2\).
核心算法1:NCDE(the neighborhood based crowding DE)
首先生成NP个初始解,对于每个个体,找到\(m\)个最为相似的个体形成子种群\(subpop_i\),在\(subpop_i\)中找到\(r_1,r_2,r_3\),使用DE得到\(u_i\),计算\(u_i\)到整个种群其他个体的距离,比较和\(u_i\)距离最近的个体的适应度,如果\(u_i\)更优,则取代。相比CDE,NCDE只是加入了领域变异,十分简单。

核心算法2:NSDE(the neighborhood based speciation DE)
首先生成NP个初始解,适应度排序,确定未处理的最优个体,找到距离最相近的\(m\)个个体形成新的种群,在当前种群中移除处理了的个体,直到当前种群为空。对于每个种群执行全局DE,如果孩子适应度和父亲一样,用随机个体取代孩子。最后保留NP个更优的个体组合成下一代种群。相比SDE,也只是加入了一个领域变异,不需要确定参数r了。

updata matlab代码
由于有"学友"在csdn上询问代码的事情,代码我就给出来吧!原始代码的是实验室学长们的,后来自己修修改改,可读性估计蛮差了,但是也有一些自己的注释。如果对matlab熟悉的话,应该还好,当然首先是对DE和ncsd已经nsde算法流程很熟悉。
现在的学习方向和这已经偏差很多的,但是这类优化算法还是特别有意思的。记得g老师说“优化加学习,必成必杀技”,哈哈!
博客园好像上传的文件不能共享下载,放到scdn上,关注即可下载!
code link
