Weka的使用和二次开发(朴素贝叶斯及其属性选择)
这篇博客主要讲解基于Weka平台二次开发一个分类器的方法,基于朴素贝叶斯分类器的二次开发的视频,大家也可以去mooc查看中国地质大学(武汉)蒋良校老师课程的第十四章。
安装和使用
下载去Weka网页下载Weka安装包,Weka是基于Java的数据挖掘软件。如果电脑没有Java jdk环境的,需要下载附带jdk的Weka安装包。
按照打开之和页面如下:
Weka的使用较为简单,点击Explore,首先选择数据集,Weka软件安装完成之后,安装目录下面有个data文件夹包含一部分.arff数据集,可以用于测试。选择一个数据集之和,可以对数据集预处理,之后选择一个分类器,然后选择训练和测试选择,点击Star,给出在数据集上的精度。
二次开发
因为Weka是开源的平台,所以可以使用Weka二次开发。打开Weka的安装路径,选择weka-src.jar文件,复杂到你想要实验的目录下,解压,你就可以在这个软件基础上二次开发了。因为.arff文件数据,在Weka里面的数据类型是Instances,所以需要提前了解Instances的数据类型,网上有一些blog介绍。
打开Java 的IDE,例如eclipse,新建一个Project,选择路径为解压weka-src,新建完成之后如下图。
如何要实现自己的分类器,建议先在weka-src/src/main/java新建一个Package,然后新建一个java文件,实现自己的分类器。
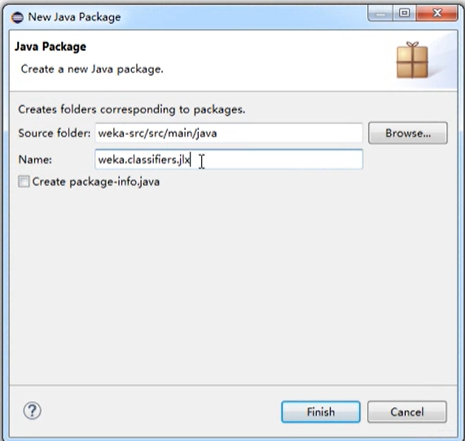
新建一个java包之后,需要在weka.gui包下面GenericPropertiesCreator.props文件加入一行,例如包的名字是gzr,如下:
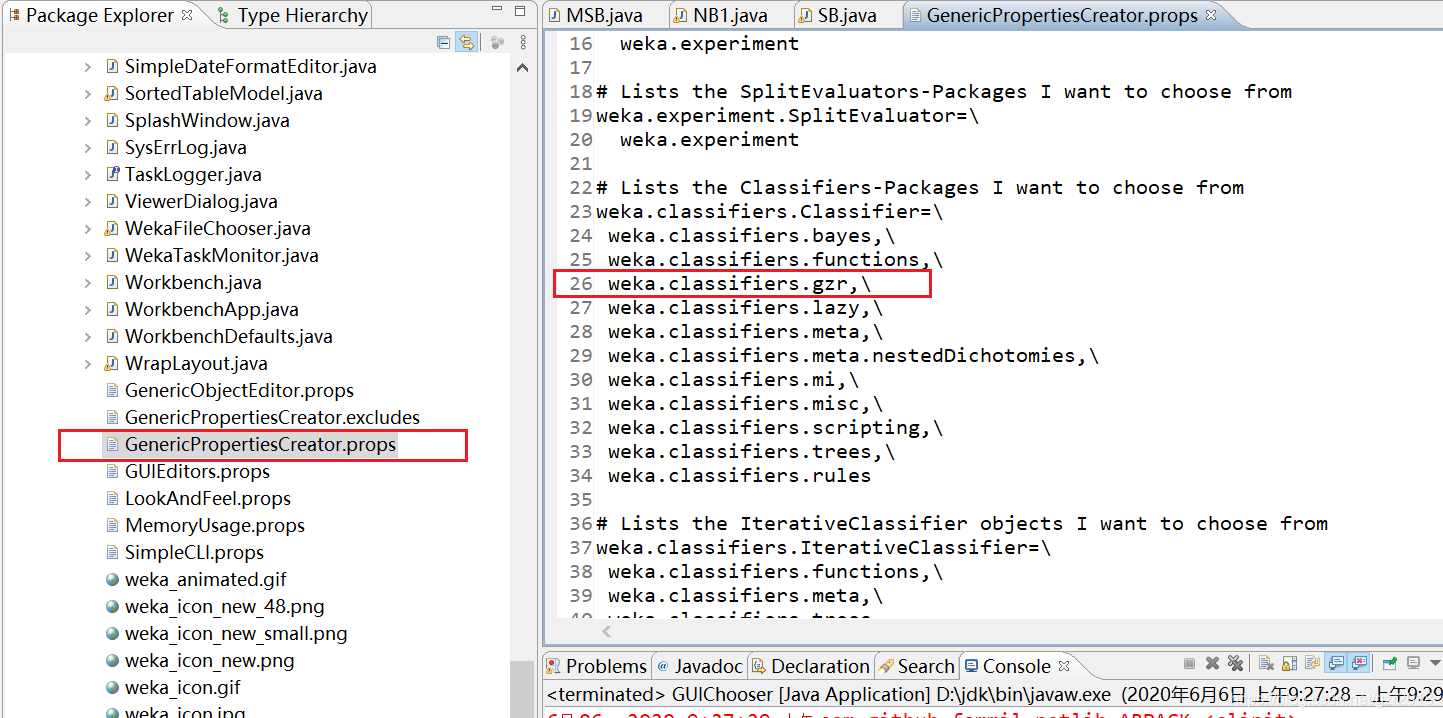
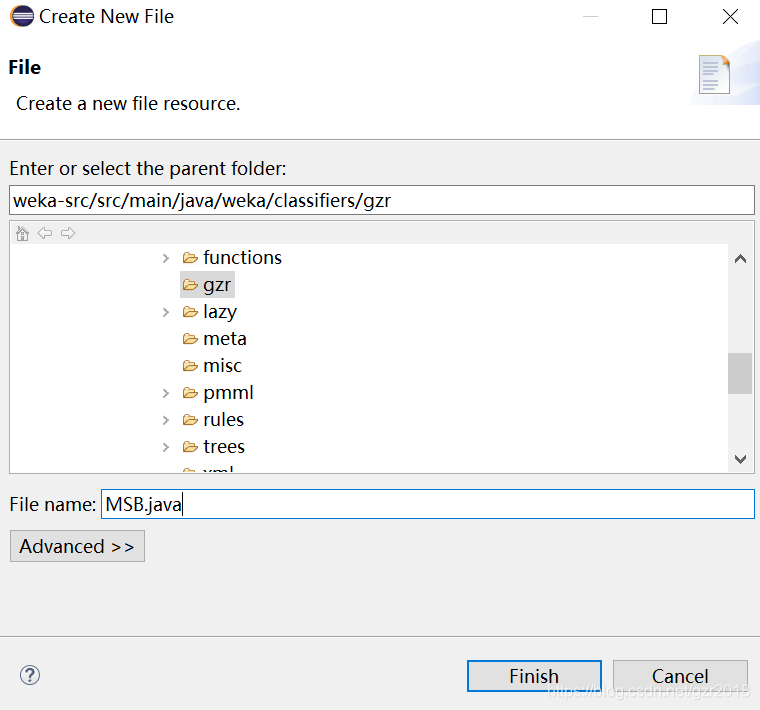
右键新建File,例如我新建一个MSB.java文件。
运行java
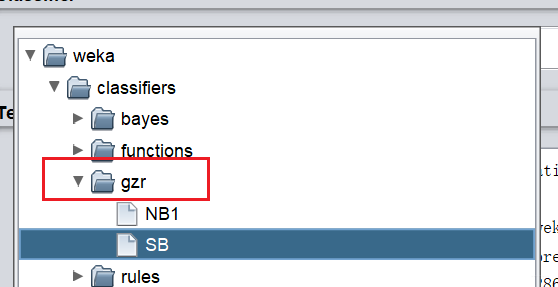
在每个文件里面写入分类器的代码,实现自己的分类器。
分类器只要重载如下两个函数即可:
public void buildClassifier(Instances instances) throws Exception
public double [] distributionForInstance(Instance instance) throws Exception
运行src/main/java/weka.gui/GUIChooser.java文件即可运行程序,测试自己的分类器。
朴素贝叶斯和基于贪心的属性选择的朴素贝叶斯代码
朴素贝叶斯:
package weka.classifiers.gzr;
import weka.core.*;
import weka.classifiers.*;
/**
* Implement the NB1 classifier.
*/
public class NB1 extends AbstractClassifier {
/** The number of class and each attribute value occurs in the dataset */
private double [][] m_ClassAttCounts;
/** The number of each class value occurs in the dataset */
private double [] m_ClassCounts;
/** The number of values for each attribute in the dataset */
private int [] m_NumAttValues;
/** The starting index of each attribute in the dataset */
private int [] m_StartAttIndex;
/** The number of values for all attributes in the dataset */
private int m_TotalAttValues;
/** The number of classes in the dataset */
private int m_NumClasses;
/** The number of attributes including class in the dataset */
private int m_NumAttributes;
/** The number of instances in the dataset */
private int m_NumInstances;
/** The index of the class attribute in the dataset */
private int m_ClassIndex;
public void buildClassifier(Instances instances) throws Exception {
// reset variable
m_NumClasses = instances.numClasses();
m_ClassIndex = instances.classIndex();
m_NumAttributes = instances.numAttributes();
m_NumInstances = instances.numInstances();
m_TotalAttValues = 0;
// allocate space for attribute reference arrays
m_StartAttIndex = new int[m_NumAttributes];
m_NumAttValues = new int[m_NumAttributes];
// set the starting index of each attribute and the number of values for
// each attribute and the total number of values for all attributes(not including class).
for(int i = 0; i < m_NumAttributes; i++) {
if(i != m_ClassIndex) {
m_StartAttIndex[i] = m_TotalAttValues;
m_NumAttValues[i] = instances.attribute(i).numValues();
m_TotalAttValues += m_NumAttValues[i];
}
else {
m_StartAttIndex[i] = -1;
m_NumAttValues[i] = m_NumClasses;
}
}
// allocate space for counts and frequencies
m_ClassCounts = new double[m_NumClasses];
m_ClassAttCounts = new double[m_NumClasses][m_TotalAttValues];
// Calculate the counts
for(int k = 0; k < m_NumInstances; k++) {
int classVal=(int)instances.instance(k).classValue();
m_ClassCounts[classVal] ++;
int[] attIndex = new int[m_NumAttributes];
for(int i = 0; i < m_NumAttributes; i++) {
if(i == m_ClassIndex){
attIndex[i] = -1;
}
else{
attIndex[i] = m_StartAttIndex[i] + (int)instances.instance(k).value(i);
m_ClassAttCounts[classVal][attIndex[i]]++;
}
}
}
}
/**
* Calculates the class membership probabilities for the given test instance
*
* @param instance the instance to be classified
* @return predicted class probability distribution
* @exception Exception if there is a problem generating the prediction
*/
public double [] distributionForInstance(Instance instance) throws Exception {
double [] probs = new double[m_NumClasses];
// store instance's att values in an int array
int[] attIndex = new int[m_NumAttributes];
for(int att = 0; att < m_NumAttributes; att++) {
if(att == m_ClassIndex)
attIndex[att] = -1;
else
attIndex[att] = m_StartAttIndex[att] + (int)instance.value(att);
}
// calculate probabilities for each possible class value
for(int classVal = 0; classVal < m_NumClasses; classVal++) {
probs[classVal]=(m_ClassCounts[classVal]+1.0)/(m_NumInstances+m_NumClasses);
for(int att = 0; att < m_NumAttributes; att++) {
if(attIndex[att]==-1) continue;
probs[classVal]*=(m_ClassAttCounts[classVal][attIndex[att]]+1.0)/(m_ClassCounts[classVal]+m_NumAttValues[att]);
}
}
Utils.normalize(probs);
return probs;
}
public static void main(String [] argv) {
// try {
// System.out.println("here");
// NB1 myNb= new NB1();
// Evaluation eva = new Evaluation(null);
// eva.evaluateModel(myNb, argv);
// System.out.println(eva.correct());
// }
// catch (Exception e) {
// e.printStackTrace();
// System.err.println(e.getMessage());
// }
}
}
基于贪心的属性选择的朴素贝叶斯:
(这个代码之后公开吧)
/*
* SB.java
* @author gzr2018
Copyright 2020 Zhirui Gao
*/
package weka.classifiers.gzr;
import weka.core.*;
import java.util.Vector;
import weka.classifiers.*;
/*
Implement the SN classifier.
*/
public class SB extends AbstractClassifier{
/** The number of class and each attribute value occurs in the data set*/
private double [][] m_ClassAttCounts;
/** The number of each class value occurs in the data set*/
private double [] m_ClassCounts;
/** The number of values for each attribute in the data set*/
private int [] m_NumAttValues;
/** The starting index of each attribute in the data set*/
private int [] m_StartAttIndex;
/** The number of values for all attributes in the data set*/
private int m_TotalAttValues;
/** The number classes in the data set*/
private int m_NumClasses;
/** The number of attributes including class in the data set*/
private int m_NumAttributes;
/** The number of instance in the data set*/
private int m_NumInstances;
/** The index of the class attribute in the data set*/
private int m_ClassIndex;
//最后选择的子集
private Vector<Integer> vector;
/**
* Generates the classifier
* @param instances set of instances serving as training data
* @throws Exception
* @exception Exceptoin if the classifier has not been generated successfully
*/
//选择一个属性子集,n^2复杂度
public void chooseSubset(Instances instances) throws Exception {
buildClassifierTemp(instances);
vector = new Vector<Integer>();
//数组默认为0
int m_NumClass = instances.numClasses();
//计算每一个类出现的次数
int[]cnt_class=new int[m_NumClass];
int max_cnt=0;
for(int i=0;i<instances.numInstances();i++) {
cnt_class[(int) (instances.instance(i).classValue())]++;
max_cnt =Math.max(max_cnt, cnt_class[(int) (instances.instance(i).classValue())]);
}
//得到初始概率,使用最大类的精度
double cur_prob = (1.0*max_cnt)/instances.numInstances();
int temp_id=0;
double temp_prob=0;
for(int i=0;i<instances.numAttributes();i++) {
temp_id=0;temp_prob=0;//init
for(int j=0;j<instances.numAttributes();j++) {
if(j==m_ClassIndex)continue;
if(vector.contains(j)==true)continue;//已经选了当前属性
//尝试加入一个属性j
vector.addElement(j);
double p = getCorretRate(instances);
if(p>temp_prob) {
temp_prob = p;
temp_id = j;
}
//去掉j属性
vector.remove((Integer)j);
}
if(temp_prob+0.0000001>=cur_prob) {
cur_prob = temp_prob;//当前正确率更新
//永久保存到子集中
vector.addElement(temp_id);
}
//已经无法改善子集了
else break;
System.out.println(cur_prob);
}
}
//得到当前属性子集下的正确率
public double getCorretRate(Instances instances) throws Exception {
int cnt=0;//计数变量
int length = instances.numInstances();
for(int i=0;i<length;i++) {
double maxIndex= classifyInstance(instances.instance(i));
//判断预测的类和实际类属性是否一致
if((int)maxIndex==(int)instances.instance(i).classValue()) {
cnt++;
}
}
return cnt*1.0/length;
}
public void buildClassifierTemp(Instances instances) {
//reset variables
m_NumClasses = instances.numClasses();
m_ClassIndex = instances.classIndex();
m_NumAttributes = instances.numAttributes();
m_NumInstances = instances.numInstances();
m_TotalAttValues = 0;
// allocate space for attribute reference arrays
m_StartAttIndex = new int[m_NumAttributes];
m_NumAttValues = new int[m_NumAttributes];
//设置每个属性的开始index,每个属性的不同值的数目,全部属性值的数目(不包括类)
for(int i =0;i < m_NumAttributes;i++) {
//如果为普通属性
if(i != m_ClassIndex) {
m_StartAttIndex[i]= m_TotalAttValues;
m_NumAttValues[i]= instances.attribute(i).numValues();
m_TotalAttValues +=m_NumAttValues[i];
}
else {
m_StartAttIndex[i] = -1;
m_NumAttValues[i] = m_NumClasses;
}
}
//allocate space counts and frequencies
m_ClassCounts = new double[m_NumClasses];
m_ClassAttCounts = new double[m_NumClasses][m_TotalAttValues];
//计算Counts
for(int k = 0;k<m_NumInstances;k++) {
int classVal = (int)instances.instance(k).classValue();
m_ClassCounts[classVal]++;
int [] attIndex = new int [m_NumAttributes];
for (int i = 0; i < m_NumAttributes; i++) {
if(i == m_ClassIndex) {
attIndex[i] = -1;
}
else {
attIndex[i] = m_StartAttIndex[i]+(int)instances.instance(k).value(i);
m_ClassAttCounts[classVal][attIndex[i]]++;
}
}
}
}
public void buildClassifier(Instances instances)throws Exception{
//先调用函数,选择一个合适的子集
chooseSubset(instances);
//buildClassifier可以维持不变,因为不加入一个属性,在计算每一个类的概率把对应属性忽略即可
buildClassifierTemp(instances);
}
/**
* 计算每个给定示例的类成员概率
* @param instance the instance to be classified
* @return predicted class probability distribution
* @exception Exception if there is a problem generating the prediction
*/
public double[] distributionForInstance(Instance instance) throws Exception{
//Definition of local variables
double[] probs = new double[m_NumClasses];
//store instance's attribute values in an int array
int[] attIndex = new int[m_NumAttributes];
for(int att = 0;att<m_NumAttributes;att++) {
if(att==m_ClassIndex)
attIndex[att]=-1;
else {
attIndex[att] = m_StartAttIndex[att]+(int)instance.value(att);
}
}
//计算每一种类的概率
for(int classVal =0;classVal<m_NumClasses;classVal++) {
//由于每一个类的分母都为P(x),所以不用计算
//先计算P(y_i),拉普拉斯纠正
probs[classVal]=(m_ClassCounts[classVal]+1.0)/(m_NumInstances+m_NumClasses);
for(int att=0;att<m_NumAttributes;att++) {
//没有加入的属性不参与计算
if(vector.contains(att)==false)continue;
if(attIndex[att]==-1)continue;
//计算P(a_i|y_i)
probs[classVal]*=(m_ClassAttCounts[classVal][attIndex[att]]+1.0)/(m_ClassCounts[classVal]+m_NumAttValues[att]);
}
}
Utils.normalize(probs);
return probs;
}
/**
* main method for testing this class
*
* @param argv
*/
public static void main(String[] argv) {
runClassifier(new SB(), argv);
}
}
