计算机组成原理学习——存储于IO系统
计算机有五大组成部分,分别是:运算器、控制器、存储器、输入设备和输出设备。
存储器
- 一般把CPU比喻成计算机的“大脑”。大脑思考的东西比喻成寄存器(Register)。寄存器与其说是存储器,其实它更像是CPU本身的一部风,只能存放极其有限的信息,但是速度非常快,和CPU同步。
- 大脑中的记忆,就好比CPU Cache(CPU高速缓存),CPU Cache用的是一种叫做SRAM(Static Random-Access Memory,静态随机存储器)的芯片。
SRAM
- SRAM称作“静态”存储器,因为只要处在通电状态,里面的数据就可以保持存在,而一旦断电,里面的数据就会丢失。由于SRAM的存储密度不高,同样的物理空间下,能够存储的数据有限。但是电路简单,访问速度非常快。
- 在CPU里,通常会有L1、L2、L3这样三层高速缓存。 每块CPU核心都有一块属于自己的L1高速缓存,通常分为指令缓存和数据缓存。L2的Cache同样是每个CPU核心都有的,不过它往往不在CPU核心内部,所以访问速度比L1稍微慢一点,而L3 Cache,则通常是多个CPU核心共用的,尺寸更大一点,访问速度自然也就更慢一点。
- 为了方便记忆,此处做个比喻:
| 缓存 | 比喻 |
|---|---|
| L1 | 短期记忆 |
| L2/L3 | 长期记忆 |
| 内存 | 书架书籍 |
- 大脑(CPU)学习完输出东西:先要调用短期记忆(L1 Cache),在调用之前的长期记忆(L2/L3),还需翻阅书架书籍(内存),最后整合思考(CPU处理和运算)。
DRAM
- 内存用的芯片和Cache不同,它用的是一种叫做DRAM(Dynamic Random Access Memery,动态随机存取存储器)的芯片,相对于SRAM,密度更高,容量更大,更便宜。
- DRAM之所以成为“动态”存储器,是因为DRAM需要不断地“刷新”,才能保持数据被存储起来,由于数据存储在电容里,电容会不断漏电,所以需要定时刷新充电,才能保持数据不丢失。DRAM的数据访问电路和刷新电路都比SRAM更复杂,所以访问延迟时也就更长。
存储器的层次结构
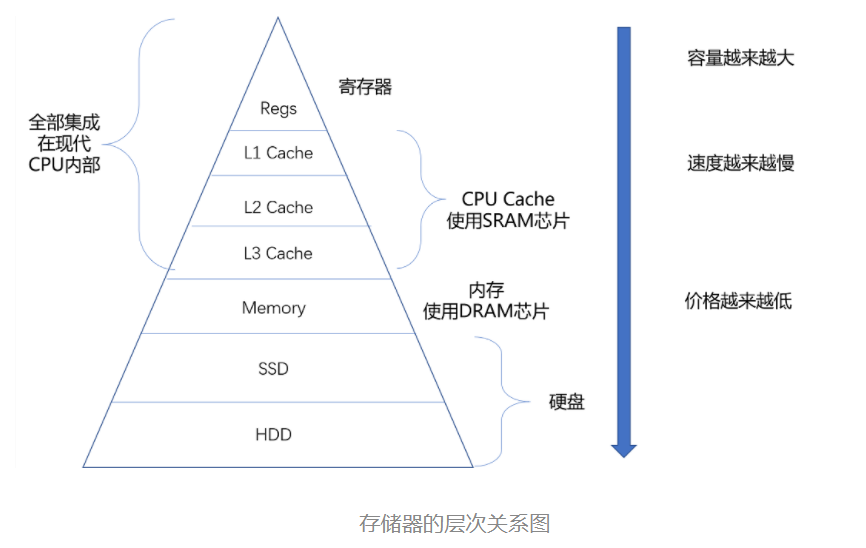
- 从Cache、内存、到SSD和HDD硬盘,一台现代计算机,就用上了所有这些存储器设备。CPU并不是直接和每一种存储器设备打交道,而是每一种存储器设备只和它相邻的存储器设备打交道。如,CPU Cache是从内存里面加载而来,或者需要写回内存,并不会直接写回数据到磁盘,也不会直接从磁盘加载数据到CPU Cache中,而是要先加载到内存,在从内存加载到Cache中。
- 这样,各个存储器只和相邻的一层存储器打交道,并且随着一层层向下,存储器的容量逐层增大,而访问速度逐层变慢,单位存储成本逐层下降,这就是日常所说的存储器层级结构。
理解CPU Cache
- 按照摩尔定律,CPU的访问速度每18个月便会翻一翻,相当于每年增长60%。内存的访问速度虽然不断增长,却远没有那么快,每年只增长7%左右。这样就导致CPU性能和内存访问的差距不断拉大。为了弥补两者之间差异,现代CPU引入了高速缓存。
- 此处CPU Cache指L1-L3 Cache,即特定由SRAM组成的物理芯片。
- 从CPU Cache被加入到CPU里面开始(CPU芯片目前就是如此),内存中的指令、数据被加载到L1-L3 Cache中,而不是直接由CPU访问去拿。在95%的情况下,CPU都需要访问L1-L3Cache,从里面读取指令和数据。
- CPU从内存中读取数据到CPU Cache的过程中,是一小块一小块来读取数据的,而不是按照单个数组元素来读取数据的。这样的一小块数据,在CPU Cache中称为Cache Line(缓存块)。
CPU 高速缓存写入
- 现代CPU,比如Intel CPU通常是多核的,意味着每个CPU核里面都有属于自己的L1、L2的Cache,然后再有多个CPU核共用的L3的Cache、主内存。
- 写入Cache的性能比写入主内存要快,那么写入数据到底是写入Cache还是写入主内存呢?如果直接写入主内存里,Cache里面的数据是否会失效呢?
写直达
- 写直达(Write-Through)策略:每一次数据倒要写入主内存里面。再写直达的策略里面,写入前,会先去判断数据是否已经再Cache里面了。如果数据已经再Cache里了,先把数据写入更新到Cache里面,再写入到主内存里面;如果数据不在Cache里,就只更新主内存。
写回
- 写回(Write-Back)策略:如果发现要写入的数据,就在CPU Cache里面,那么就只是更新CPU Cache里面的数据。同时,会标记CPU Cache里的这个Block是脏(Dirty)的。此处脏——指此时,CPU Cache里面的这个Block的数据,和主内存是不一致的。如果发现,要写入的数据所对应的Cache Block里,放的是别的内存地址的数据,那么就要看一看,那个Cache Block里面的数据有没有标记层脏的。如果是脏的话,要先把这个Cache Block里面的数据,写入到主内存里面。然后,再把当前要写入的数据,写入到Cache里,同时把Cache Block标记成脏的。如果Block里面的数据没有被标记成脏的话,那么直接把数据写入到Cache里面,然后再把Cache Block标记成脏的就好了。
- 在用了写回这个策略之后,在加载内存数据到 Cache 里面的时候,也要多出一步同步脏 Cache 的动作。如果加载内存里面的数据到 Cache 的时候,发现 Cache Block 里面有脏标记,也要先把 Cache Block 里的数据写回到主内存,才能加载数据覆盖掉 Cache。
直接映射Cache(Direct Mapped Cache)
- 读取内存中的数据,首先拿到的数据所在的内存块(Block)的地址。而直接映射Cache采用的策略,就是确保任何一个内存块的地址,始终映射到一个固定的CPU Cache地址(Cache Line)。这个映射关系,通常用mod运算(求余运算)来实现。除直接映射Cache之外,常见的缓存放置策略还有全相连Cache(Funlly Associative Cache)、组相连(Set Associative Cache)。
缓存一致性
- CPU Cache 解决的是内存访问速度和 CPU 的速度差距太大的问题。而多核 CPU 提供的是,在主频难以提升的时候,通过增加 CPU 核心来提升 CPU 的吞吐率的办法。把多核和 CPU Cache 两者一结合,就带来了一个新的挑战。因为 CPU 的每个核各有各的缓存,互相之间的操作又是各自独立的,就会带来缓存一致性(Cache Coherence)的问题。
写传播(Write Propagation)
- 在一个 CPU 核心里, Cache 数据更新,必须能够传播到其他的对应节点的 Cache Line 里。
事务的串行化(Transaction Serialization)
- 在一个 CPU 核心里面的读取和写入,在其他的节点看起来,顺序是一样的。
- 在 CPU Cache 里做到事务串行化,需要做到两点,第一点是一个 CPU 核心对于数据的操作,需要同步通信给到其他 CPU 核心。第二点是,如果两个 CPU 核心里有同一个数据的 Cache,那么对于这个 Cache 数据的更新,需要有一个“锁”的概念。只有拿到了对应 Cache Block 的“锁”之后,才能进行对应的数据更新。下来,引入实现了这两个机制的 MESI 协议。
总线嗅探机制和 MESI 协议
- 总线嗅探(Bus Snooping):要解决缓存一致性问题,首先要解决的是多个 CPU 核心之间的数据传播问题。最常见的一种解决方案呢,叫作总线嗅探。这个策略,本质上就是把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。
- 基于总线嗅探机制,还可以分成很多种不同的缓存一致性协议。MESI 协议室其中最常用的。
- MESI 协议:一种叫作写失效(Write Invalidate)的协议,在写失效协议里,只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 Cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个“失效”版本的 Cache Block,然后把这个也标记成失效的就好了。
内存
- 内存需要被分成固定大小的页(Page),然后再通过虚拟内存地址(Virtual Address)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置。而程序看到的内存地址,都是虚拟内存地址。
简单页表
- 要把虚拟内存地址,映射到物理内存地址,最直观的办法,就是来建一张映射表。这个映射表,能够实现虚拟内存里面的页,到物理内存里面的页的一一映射。这个映射表,在计算机里面,就叫作页表(Page Table)。
内存地址转化
- 把虚拟内存地址,切分成页号和偏移量的组合;
- 从页表里面,查询出虚拟页号,对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
多级页表
- 大部分进程所占用的内存是有限的,需要的页也自然是很有限的,只需要去存那些用到的页之间的映射关系就好了。
- 多级页表就像一个多叉树的数据结构,所以我们常常称它为页表树(Page Table Tree)。多级页表虽然节约了我们的存储空间,却带来了时间上的开销,所以它其实是一个“以时间换空间”的策略。
总线
- 总线,其实就是一组线路。我们的 CPU、内存以及输入和输出设备,都是通过这组线路,进行相互间通信的,又称计算机内部的高速公路。
- 现代的 Intel CPU 的体系结构里面,通常有好几条总线。CPU 和内存以及高速缓存通信的总线,这里面通常有两种总线。这种方式,我们称之为双独立总线(Dual Independent Bus,缩写为 DIB)。CPU 里,有一个快速的本地总线(Local Bus),以及一个速度相对较慢的前端总线(Front-side Bus)。
本地总线(Local Bus)又称后端总线(Back-side Bus)
- 现代的 CPU 里,通常有专门的高速缓存芯片。这里的高速本地总线,就是用来和高速缓存通信的。
前端总线(Front-side Bus)又称处理器总线(Processor Bus)、内存总线(Memory Bus)
- 用来和主内存以及输入输出设备通信的。
输入输出设备
posted on 2022-04-03 21:33 betterLearing 阅读(157) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号