离线环境CentOS部署CDH集群手册
前言
本文说明
本文主要讲解基于离线环境下,利用三台服务器部署CDH集群方案。三台服务可以是物理机组成的同网段CentOS系统,也可以是私有云组成的同网段CentOS系统。
本版约定
Linux版本:CentOS 7.6
CDH版本:CDH-5.16.1
CM版本:cloudera-manager-centos7-cm5.16.1_x86_64
资源包
- CentOS 7.6镜像:CentOS-7-x86_64-DVD-1810.iso
- JDK: jdk-8u162-linux-x64.tar.gz
- MySQL & Connector:
mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
mysql-connector-java-5.1.47.jar - Cloudera-Manager & CDH:
cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel
manifest.json - Kafka:
KAFKA-1.2.0.jar
KAFKA-2.1.1-1.2.1.1.p0.18-el7.parcel
KAFKA-2.1.1-1.2.1.1.p0.18-el7.parcel.sha
manifest-kafka.json - Spark2
SPARK2_ON_YARN-2.3.0.cloudera2.jar
SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101-el7.parcel
SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101-el7.parcel.sha
manifest_spark.json - Sqoop
hive-hcatalog-core.jar
hive-jdbc.jar
java-json.jar
前提说明
- 大数据组件默认安装模式下,数据都存储在根目录所拥有的磁盘空间,而Linxu默认给根目录50G,后期会报空间不足。建议一开始把分给服务器磁盘空间的90%分给根目录下或者给根目录扩展磁盘。
参考网址:https://www.cnblogs.com/mytangyh/p/15061101.html
https://www.cnblogs.com/myvic/p/6816924.html
https://blog.csdn.net/qq_31708763/article/details/86506959 - 由于离线模式,实际安装过程需要安装一些小的插件程序,一般通过yum命令,而这些插件需要网上下载,由于离线模式,这边直接通过挂载iso镜像,让yum从镜像中查找插件程序进行安装。参考网址:https://blog.csdn.net/fdsafdafdsfds/article/details/87082700
- 根据Linux目录规则,本次软件包和安装目录都放在此目录下:/opt
- 规化服务器
| 服务器名称 | 子服务 | 服务器 master | 服务器 worker01 | 服务器 worker02 |
|---|---|---|---|---|
| HDFS | NameNode | ✔ | ||
| HDFS | DateNode | ✔ | ✔ | ✔ |
| HDFS | SecondaryNameNode | ✔ | ||
| Hive | Hive | ✔ | ✔ | ✔ |
| Hue | Hue | ✔ | ||
| Impala | Impala | ✔ | ✔ | ✔ |
| Kafka | Kafka | ✔ | ✔ | ✔ |
| Zookeeper | Zookeeper Server | ✔ | ✔ | ✔ |
部署步骤(特别说明,下面是以root用户操作,假设三台服务器采用固定IP,分别是192.168.0.101、192.168.0.102、192.168.0.103)
一、配置hosts文件(所有节点)
- 进入hosts文件配置
vim /etc/hosts
- 添加下面的内容,三个节点都需要(此处按照官网案例,三段式结构:IP,全名称,别名):
192.168.0.101 master.com.cn master
192.168.0.102 worker01.com.cn worker01
192.168.0.103 worker02.com.cn worker02
- 每个节点,分别设置相应的主机名称,与上面添加的内容相呼应:(保证这边的设置名称与后面安装的CDH中主机名称保持一致)
举例master节点:
hostnamectl set-hostname master.com.cn
举例worker01节点:
hostnamectl set-hostname worker01.com.cn
举例worker02节点:
hostnamectl set-hostname worker02.com.cn
二、配置免密登入(所有节点)
参考网址:略
- 每台机器先使用ssh命令(ssh 主机别名),以在主目录产生一个.ssh 文件夹:
ssh master
然后输入no即可
- 每台机器均进入~/.ssh 目录进行操作
cd ~/.ssh
- 输入下面命令,根据提示,一路回车,产生公钥和密钥
ssh-keygen -t rsa
- 将每台机器上的id_rsa.pub公钥内容复制到authorized_keys文件中:(cp命令:cp 源文件 目标文件)
cp id_rsa.pub authorized_keys
- 将所有的authorized_keys文件进行合并(最简单的方法是将其余两台worker主机的文件内容追加到master主机上),worker01和worker02分别执行:
cat ~/.ssh/authorized_keys | ssh -p 22 root@master 'cat >> ~/.ssh/authorized_keys'
上述命令解释:
cat 待复制内容
| (管道符号)
ssh 端口命令前缀 远程端口(根据实际情况) 目标主机用户@目标主机名称
cat >>(追加到) 目标文件
- 将master上的authorized_keys文件分发到其他主机上
scp -P 22 ~/.ssh/authorized_keys root@worker01:~/.ssh/
scp -P 22 ~/.ssh/authorized_keys root@worker02:~/.ssh/
三、关闭防火墙及清空规则(所有节点)
systemctl stop firewalld
systemctl disable firewalld
iptables -F
四、关闭selinux(所有节点)
vi /etc/selinux/config
# 将SELINUX=enforcing改为SELINUX=disabled
设置后需要重启才能⽣效
reboot
五、设置时区及时钟同步(主从结构)
如果是基于私有云搭建集群,默认时钟同步已经做好。如果发现存在时间差,获取私有云中固定的那台时钟同步IP,三个节点先进行一次手动同步,在通过定时任务,进行定时同步。
如果纯物理机,按照如下操作:
- 修改时区(所有节点),设置成东八区,即亚洲/上海
timedatectl set-timezone Asia/Shanghai
- 安装NTP服务(所有节点)
yum install -y ntp
- 编辑获取时间来源(主节点)
进入ntp.conf文件中
vi /etc/ntp.conf
添加内容(定位到都是server那几行)
#server指定ntp服务器的地址 将当前主机作为时间服务器
#fudge设置时间服务器的层级 stratum 0~15 ,0:表示顶级 , 10:通常用于给局域网主机提供时间服务
#注意:fudge必须和server一块用, 而且是在server的下一行
server 127.127.1.0 #use local clock
fudge 127.127.1.0 stratum 10
#允许哪些⽹段的机器来同步时间
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
- 从节点对应文件相应位置添加内容,指向主节点IP
server 127.127.1.0 #use local clock
fudge 127.127.1.0 stratum 10
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
- Ntpd服务启动(主节点)
#启动
systemctl start ntpd
#查看当前状态
systemctl status ntpd
- 从节点禁用NTP服务(从节点)
#停止
systemctl stop ntpd
#禁用
systemctl disable ntpd
#查看当前状态
systemctl status ntpd
- 手动同步时钟(从节点)
/usr/sbin/ntpdate master
- 定时同步时间(从节点)
#编辑crontab
crontab -e
#进入文件添加定时任务,每天凌晨定时执行同步主节点名称
00 00 * * * /usr/sbin/ntpdate master
六、部署JDK(所有节点)
- 安装前检查是否已存在JDK,如果则卸载原有的
#查询当前所有安装的jdk版本,通过rpm命令查看
rpm -qa | grep jdk
上述命令输出了如下jdk
copy-jdk-configs-3.3-10.el7_5.noarch
java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
#通过rpm命令卸载
rpm -e --nodeps copy-jdk-configs-3.3-10.el7_5.noarch
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
#直到都卸载完毕,再次利用查看命令检查是否都卸载完毕
rpm -qa|grep jdk
- 安装JDK
解压JDK到/opt目录下,(并修改文件的所有者和所有者组为root)
tar -zxvf /opt/package/jdk-8u162-linux-x64.tar.gz -C /opt/
chown root:root /opt/jdk1.8.0_162/ -R
- 配置JDK环境
#进入/etc/profile文件
vim /etc/profile
在profile文件末尾添加JDK路径
#输出JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_162
#java的bin路径追加到原来PATH路径,并输出
export PATH=$PATH:$JAVA_HOME/bin
让修改后的文件生效
source /etc/profile
- 测试JDK是否安装成功,如果出现相应的版本(自己安装的那个)、运行环境版本、虚拟机,就说明成功
java -version
- 将主节点的JDK和环境配置文件分发到worker01、worker02两台主机
#发送jdk
scp -P 22 -r /opt/jdk1.8.0_162/ @worker01:/opt/
scp -P 22 -r /opt/jdk1.8.0_162/ @worker02:/opt/
#发送配置文件
scp -P 22 -r /etc/profile @worker01:/etc/profile
scp -P 22 -r /etc/profile @worker02:/etc/profile
七、部署MySQL(主节点)
假设:设置MySQL的用户名和密码都是root。实际部署请正确设置。
- 卸载原有MySQL,
#rpm命令删除几种默认mysql类型数据库
rpm -qa | grep -E 'mariadb|mysql'
rpm -qa | grep -E 'mariadb|mysql' | xargs rpm -e --nodeps
rpm -qa | grep -E 'mariadb|mysql'
- 安装MySQL
#创建目录
mkdir /opt/mysql -p
#复制MySQL至指定位置并解压
tar -xvf /opt/package/mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar -C /opt/mysql/
#进入指定目录并安装
cd /opt/mysql/
#rpm命令执行安装
rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
如果出现依赖检测失败,请安装相应的依赖,利用yum install包。
- 启动MySQL、查看MySQL、设置开自启动
systemctl start mysqld
systemctl status mysqld
systemctl enable mysqld
- 修改root密码
#在日志文件中查看mysql的root用户默认密码
grep 'temporary password' /var/log/mysqld.log
#如下,默认密码为root@localhost: 后面的内容,即:Lo)Kust_F4ek
2022-01-13T14:44:29.262863Z 1 [Note] A temporary password is generated for root@localhost: Lo)Kust_F4ek
- 取消密码策略检测,不然设置root这种简单密码无法设置成功,最后修改密码为root
#修改/etc/my.cnf文件
vim /etc/my.cnf
#在文件中添加以下内容以禁用密码策略
validate_password=off
#重新启动mysql服务
systemctl restart mysqld
#进入mysql,
mysql -uroot -p
#并输入第一步中获取的密码
Lo)Kust_F4ek
#修改密码为root
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
- 修改数据库编码为utf-8,修改上传文件大小限制。
在/etc/my.cnf 文件中添加以下内容
character_set_server=utf8
init_connect='SET NAMES utf8'
max_allowed_packet = 128M
- 添加 root 用户的远程登录权限
#进入mysql
mysql -uroot -proot
#修改root的远程访问权限,提供给客户端访问能力
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
# flush privileges:刷新MySQL的系统权限,使其即时生效,否则就重启服务器
FLUSH PRIVILEGES;
- 在MySQL中创建用户及数据库:下面的数据库实例为后面安装大数据服务组件准备,一些大数据组件初始化需要元数据,得提前为它们准备实例和对应的用户名。
进入MySQL,创建用户及数据库,复制如下命令
create database cmf DEFAULT CHARACTER SET utf8;
grant all on cmf.* TO 'cmf'@'%' IDENTIFIED BY 'cmf';
create database amon DEFAULT CHARACTER SET utf8;
grant all on amon.* TO 'amon'@'%' IDENTIFIED BY 'amon';
create database oozie DEFAULT CHARACTER SET utf8;
grant all on oozie .* TO oozie @'%' IDENTIFIED BY 'oozie';
create database hive DEFAULT CHARACTER SET utf8;
grant all on hive.* TO hive@'%' IDENTIFIED BY 'hive';
flush privileges;
exit;
- 部署MySQL JDBC jar(所有节点)
#若目录/usr/share/java/不存在则创建
mkdir -p /usr/share/java/
#复制MySQL连接器至相应的目录
cp /opt/package/mysql-connector-java-5.1.47.jar /usr/share/java/mysql-connector-java.jar
#发送至两外两台服务器
scp -P 22 -r /opt/package/mysql-connector-java-5.1.47.jar @worker02:/usr/share/java/mysql-connector-java.jar
scp -P 22 -r /opt/package/mysql-connector-java-5.1.47.jar @worker01:/usr/share/java/mysql-connector-java.jar
八、部署CM服务
- 离线部署Server 和 Agent (主从结构)
说明:Server部署在主节点,Agent部署所有节点包括主节点。
#创建目录并解压(所有节点)
mkdir -p /opt/cloudera-manager
tar -zxvf /opt/package/cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz -C /opt/cloudera-manager/
#分发解压后的cm目录:
scp -r -P 22 /opt/cloudera-manager/ @worker01:/opt/
scp -r -P 22 /opt/cloudera-manager/ @worker02:/opt/
#修改Agent配置,指向主节点(所有节点)
sed -i "s/server_host=localhost/server_host=master/g" /opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-agent/config.ini
#解释:其实/opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-agent/config.ini文件中server_host等于的对象改成master
- 修改Server配置(主节点)
#进入server对应的数据库设置文件
vim /opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-server/db.properties
#进行修改如下选项,下面的cmf就是前面数据库那会创建的实例
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=master
com.cloudera.cmf.db.name=cmf
com.cloudera.cmf.db.user=cmf
com.cloudera.cmf.db.password=cmf
com.cloudera.cmf.db.setupType=EXTERNAL
#上述文件保存完后再发送其他节点
scp -P 22 /opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-server/db.properties @worker01:/opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-server/
scp -P 22 /opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-server/db.properties @worker02:/opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-server/
#创建用户(所有节点):用户是cloudera-scm
useradd --system --home=/opt/cloudera-manager/cm-5.16.1/run/cloudera-scm-server/ --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
#修改用户及用户组(所有节点)
chown -R cloudera-scm:cloudera-scm /opt/cloudera-manager
- 部署离线Parcel源(主节点)
#创建离线源目录
mkdir -p /opt/cloudera/parcel-repo
#移动离线源到目录,并修改文件名称
cp /opt/package/CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel /opt/cloudera/parcel-repo/
cp /opt/package/CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha /opt/cloudera/parcel-repo/
cp /opt/package/manifest.json /opt/cloudera/parcel-repo/
#目录修改用户及用户组
chown -R cloudera-scm:cloudera-scm /opt/cloudera
#创建组件安装目录、用户及用户组(所有节点)
mkdir -p /opt/cloudera/parcels
chown -R cloudera-scm:cloudera-scm /opt/cloudera
- 启动并监控日志(可以省略)
补充参数(所有节点)
#说明:swappiness是Linux内核参数,控制换出运行时内存的相对权重。swappiness参数值可设置范围在0到100之间。 低参数值会让内核尽量少用交换,更高参数值会使内核更多的去使用交换空间。
#cat << EOF >> 命令说明:再文件尾添加内容。
cat << EOF >> /etc/sysctl.conf
vm.swappiness=10
EOF
#关闭THP
#说明:Transparent HugePages是在运行时动态分配内存的,而标准的HugePages是在系统启动时预先分配内存,并在系统运行时不再改变。因为Transparent HugePages是在运行时动态分配内存的,所以会带来在运行时内存分配延误。
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
#使文件成为可执行文件(命令:chmod +x)
chmod +x /etc/rc.d/rc.local
- 启动server(主节点)
/opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-server start
#立马查看输出日志:(tail -100f 查看文件最后一百行日志,且可以不断看到后面持续打印的日志)
tail -100f /opt/cloudera-manager/cm-5.16.1/log/cloudera-scm-server/cloudera-scm-server.log
-
启动Web界面。前置条件:前面的日志输出正常,比如看到成功启动了web容器,7180端口输出等。
在windows桌面,打开浏览器,网址:主机IP:7180
默认账号和密码:admin/admin -
启动所有的Agent(所有节点)
#回到Linux命令行输入界面
/opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-agent start
#立马查看输出日志:(tail -100f 查看文件最后一百行日志,且可以不断看到后面持续打印的日志)
tail -100f /opt/cloudera-manager/cm-5.16.1/log/cloudera-scm-agent/cloudera-scm-agent.log
- 帮助命令(正常情况就不需要执行)
#如需要关闭agent服务,可以执行:
/opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-agent stop
#如需要关闭server服务,可以执行(一般先停agent后停server):
/opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-server stop
CDH的集群部署,进入window浏览器,刚才登入地址。只截取重要图片
- 基础安装
1.接收条款和协议
2.选择免费列(免费 在许可证哪一行可以看到)
3.继续
4.为CDH集权安装指定主机,名称那一列选中我们的三台主机。如果没有,可以通过搜索 “master,worker01,worker02” 。
5.集群安装,选择CDH版本,选择我们的
![]()
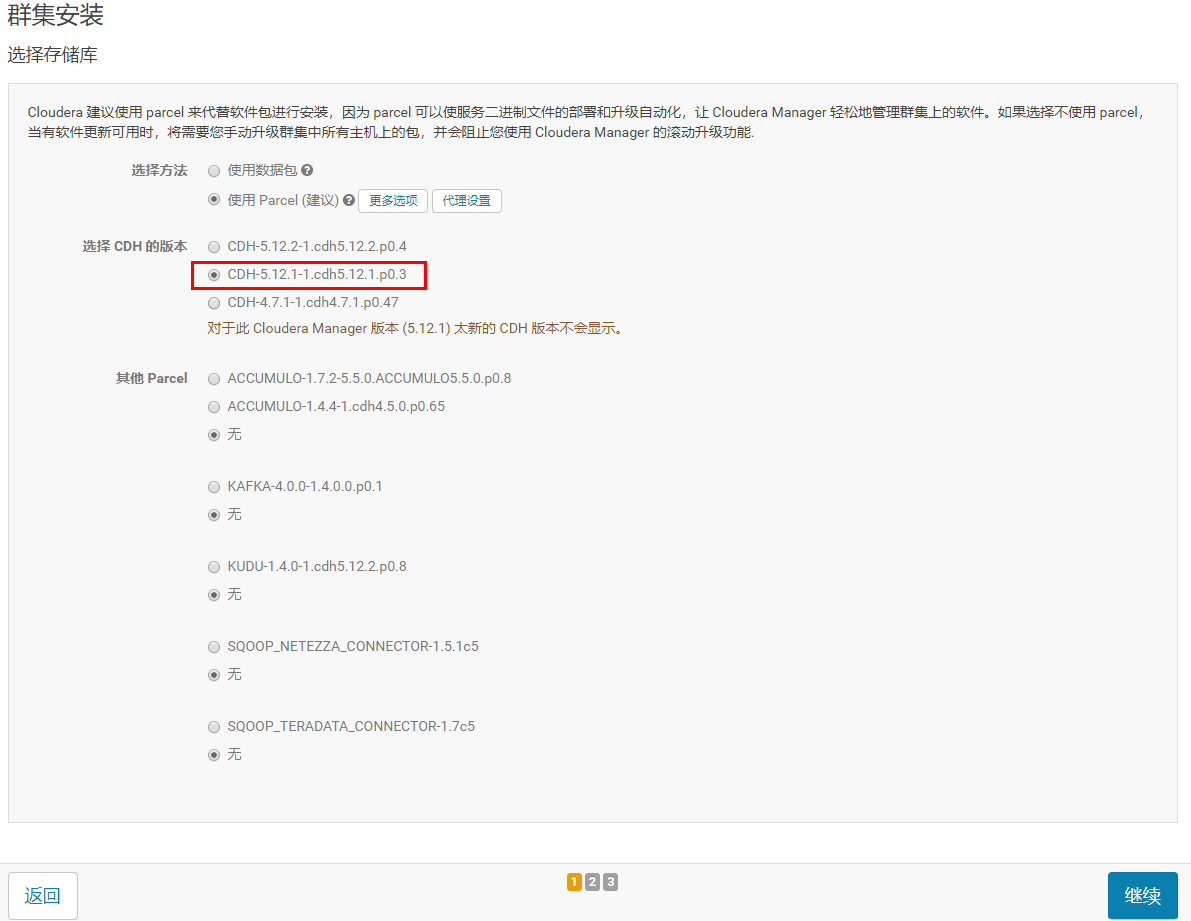
6.等待下载安装,其实就是安装我们执行的parcel(详见前面“部署离线Parcel源(主节点)”)。
7.出现检查主机正确性,验证下面都✔
- HDFS、YARN、Zookeeper安装
1.选择自定义安装
![]()
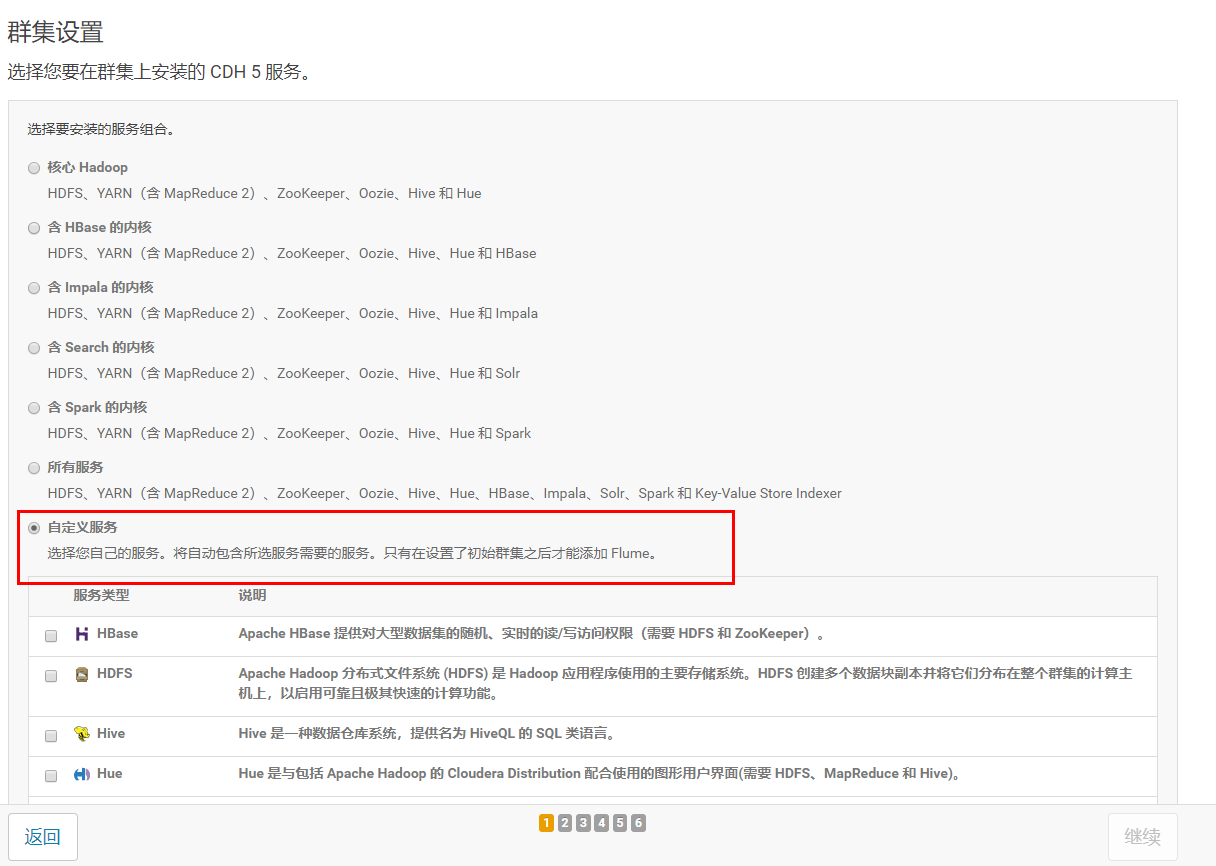
2.选择安装服务

3.分配节点
HDFS:调整SecondaryNameNode安装服务器(节点),不要跟NameNode在同一个服务器上,可以放到worker01或者worker02上。数据节点DataNode三个服务器都选。
Cloudera Management Service:默认都放在了主节点上,建议不修改。
YARN:避免主节点master服务压力过大,可以把ResourceManager节点调整到其他节点
ZooKeeper:三个节点都选
4.集权设置全部选默认,点击继续
5.自动启动进程,点击继续
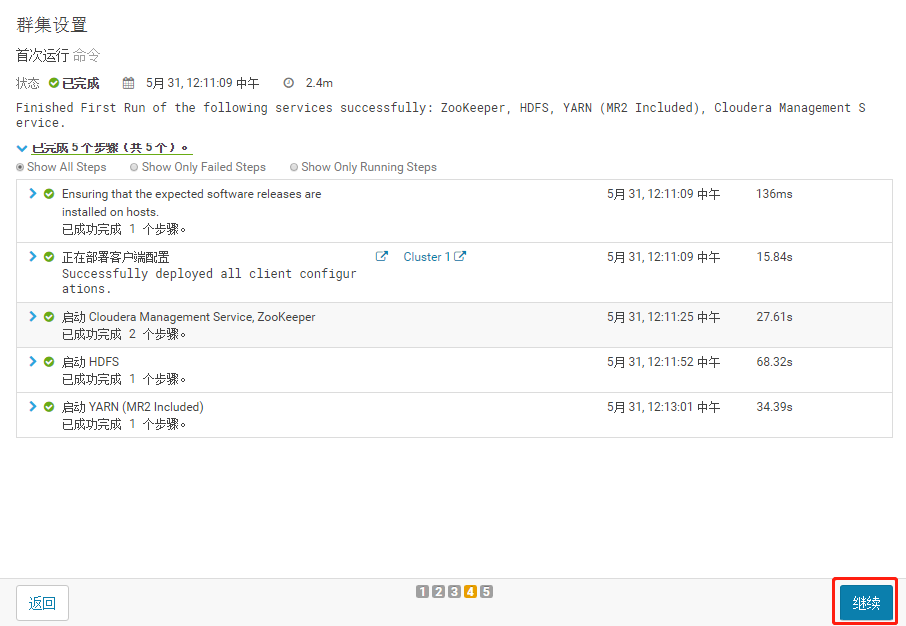
-
其他服务安装,走添加服务模式(略)
在进行Hive安装的时候,需要配置hive元数据:数据库名称、用户名、密码。(翻看前面MySQL那边,可以得知,数据库名称hive、用户名root、密码root),输入完成后,可以点击测试连接,连接成功继续。 -
Spark2 安装(主节点)
前提:关闭CM集群,可以通过界面关闭
回到Linux命令行输入界面
#在主节点创建文件夹
#创建上传包文件目录
mkdir -p /opt/package/spark2.3/csd
#安装包文件目录
mkdir -p /opt/cloudera-manager/cloudera/csd
上传SPARK2_ON_YARN-2.3.0.cloudera2.jar (此jar由于集成cloudera manager需要)到/opt/package/spark2.3/csd
利用上传工具上传,比如sftp
SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101-el7.parcel 、 SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101-el7.parcel.sha 、manifest_spark.json
到/opt/package/spark2.3/
#把包拷贝到安装目录
cp /opt/package/spark2.3/csd/SPARK2_ON_YARN-2.3.0.cloudera2.jar /opt/cloudera-manager/cloudera/csd/
#指定用户和用户组
chown cloudera-scm:cloudera-scm /opt/cloudera-manager/cloudera/csd/SPARK2_ON_YARN-2.3.0.cloudera2.jar
#分配644权限
chmod 644 /opt/cloudera-manager/cloudera/csd/SPARK2_ON_YARN-2.3.0.cloudera2.jar
#将原有的配置文件备份,后面spark2配置文件需要在同一个目录下命名为manifest.json:
mv /opt/cloudera/parcel-repo/manifest.json /opt/cloudera/parcel-repo/manifest.json.bak
#将spark2 对应的parcel都复制到安装目录
cp /opt/package/spark2.3/SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101-el7.parcel /opt/cloudera/parcel-repo/
cp /opt/package/spark2.3/SPARK2-2.3.0.cloudera2-1.cdh5.13.3.p0.316101-el7.parcel.sha /opt/cloudera/parcel-repo/
cp /opt/package/spark2.3/manifest_spark.json /opt/cloudera/parcel-repo/
#spark2 配置文件改名复制,与前面的备份配置文件呼应,CM安装程序只认程序只认manifest.json,不认manifest_spark.json
mv /opt/cloudera/parcel-repo/manifest_spark.json /opt/cloudera/parcel-repo/manifest.json
#启动CM集群
/opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-agent start
/opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-server start
在CM中更改cds的路径并重启CM集群
路径更改为/opt/cloudera-manager/cloudera/csd
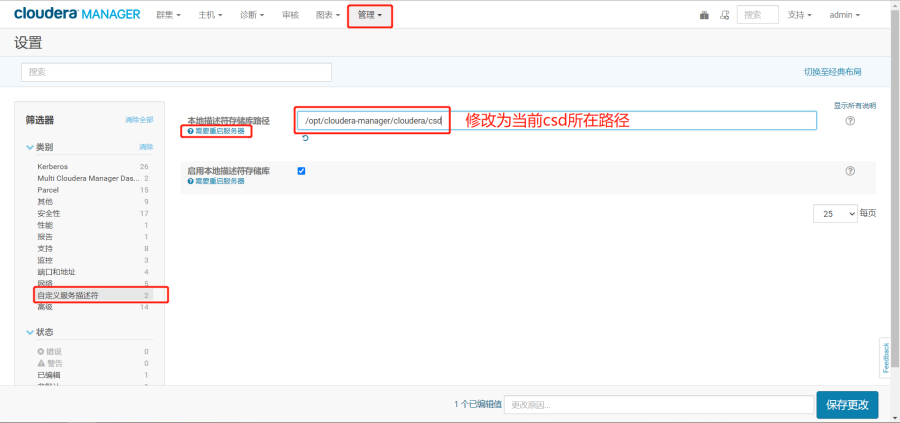
上面操作重启完成后,按照下图操作先分配再激活
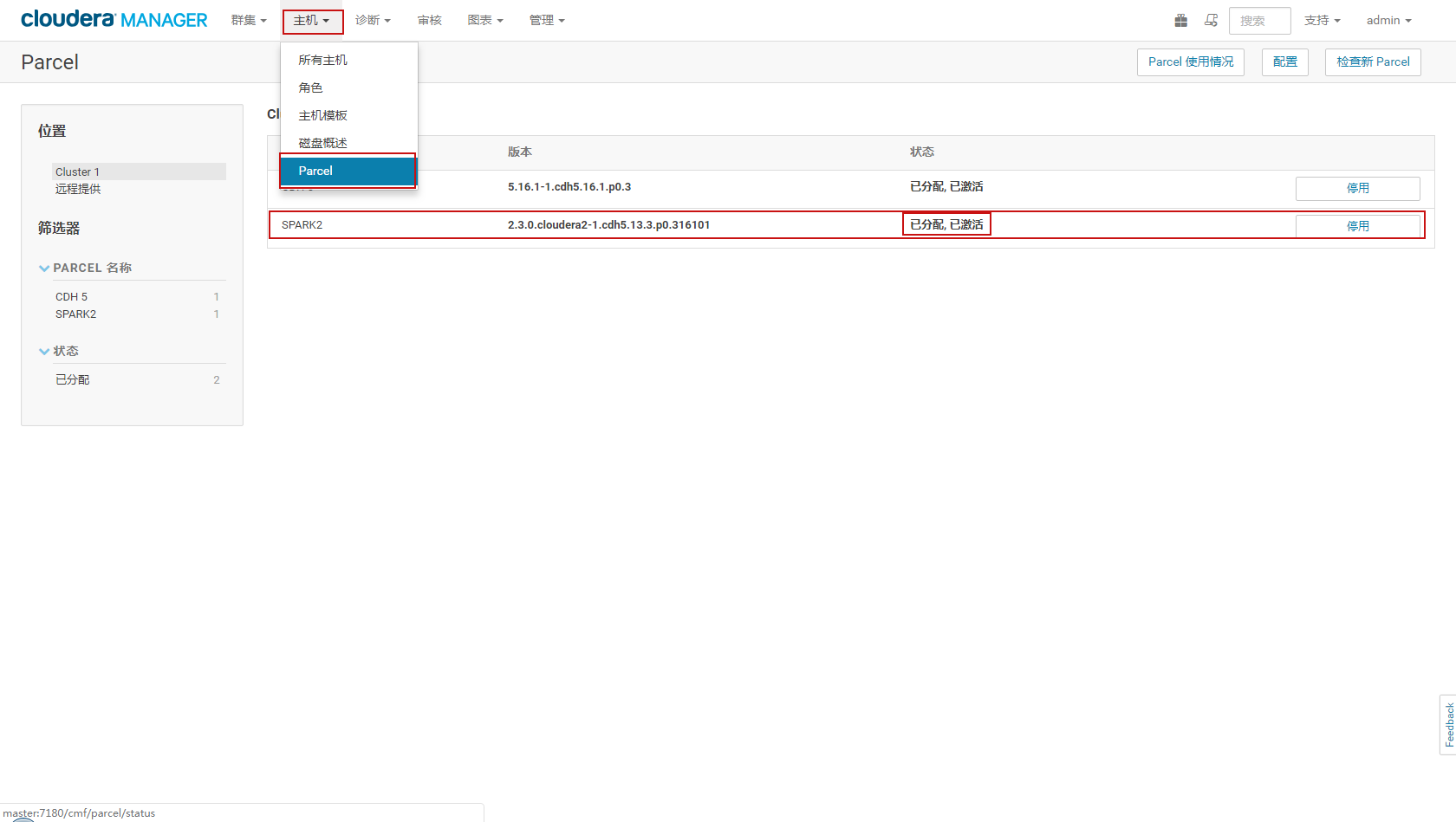
接下来就可以添加Spark2服务了。
posted on 2022-03-17 09:41 betterLearing 阅读(426) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号