


【量化课堂】多因子策略入门
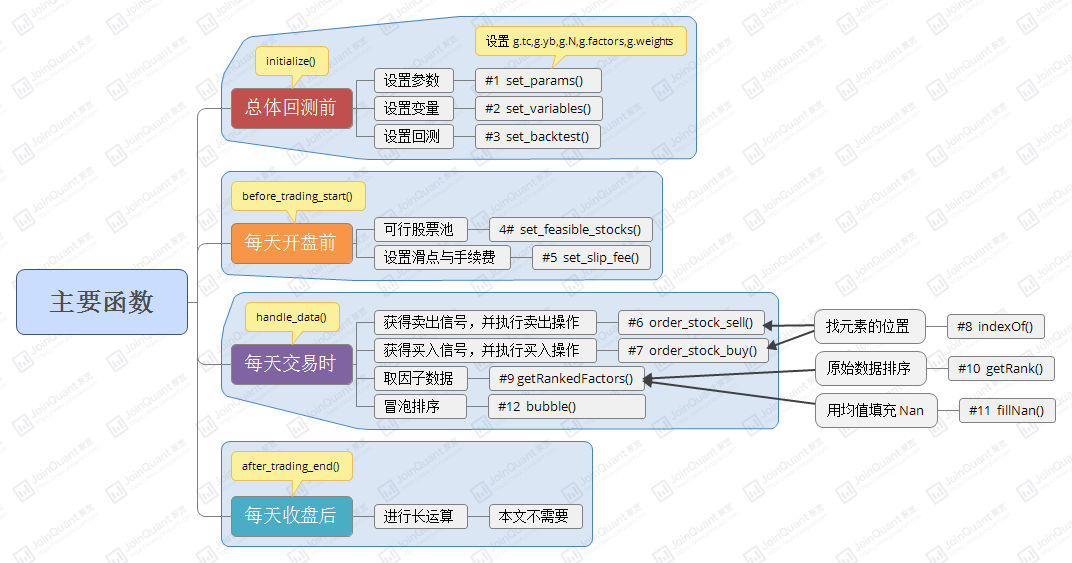
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 | #多因子策略入门# 2015-01-01 到 2016-03-08, ¥2000000, 每天'''================================================================================总体回测前================================================================================'''#总体回测前要做的事情def initialize(context): set_params() #1设置策参数 set_variables() #2设置中间变量 set_backtest() #3设置回测条件#1#设置策参数def set_params(): g.tc=15 # 调仓频率 g.yb=63 # 样本长度 g.N=20 # 持仓数目 g.factors=["market_cap","roe"] # 用户选出来的因子 # 因子等权重里1表示因子值越小越好,-1表示因子值越大越好 g.weights=[[1],[-1]] #2#设置中间变量def set_variables(): g.t=0 #记录回测运行的天数 g.if_trade=False #当天是否交易 #3#设置回测条件def set_backtest(): set_option('use_real_price', True)#用真实价格交易 log.set_level('order', 'error')'''================================================================================每天开盘前================================================================================'''#每天开盘前要做的事情def before_trading_start(context): if g.t%g.tc==0: #每g.tc天,交易一次行 g.if_trade=True # 设置手续费与手续费 set_slip_fee(context) # 设置可行股票池:获得当前开盘的沪深300股票池并剔除当前或者计算样本期间停牌的股票 g.all_stocks = set_feasible_stocks(get_index_stocks('000300.XSHG'),g.yb,context) # 查询所有财务因子 g.q = query(valuation,balance,cash_flow,income,indicator).filter(valuation.code.in_(g.all_stocks)) g.t+=1 #4# 设置可行股票池# 过滤掉当日停牌的股票,且筛选出前days天未停牌股票# 输入:stock_list为list类型,样本天数days为int类型,context(见API)# 输出:listdef set_feasible_stocks(stock_list,days,context): # 得到是否停牌信息的dataframe,停牌的1,未停牌得0 suspened_info_df = get_price(list(stock_list), start_date=context.current_dt, end_date=context.current_dt, frequency='daily', fields='paused')['paused'].T # 过滤停牌股票 返回dataframe unsuspened_index = suspened_info_df.iloc[:,0]<1 # 得到当日未停牌股票的代码list: unsuspened_stocks = suspened_info_df[unsuspened_index].index # 进一步,筛选出前days天未曾停牌的股票list: feasible_stocks=[] current_data=get_current_data() for stock in unsuspened_stocks: if sum(attribute_history(stock, days, unit='1d',fields=('paused'),skip_paused=False))[0]==0: feasible_stocks.append(stock) return feasible_stocks #5# 根据不同的时间段设置滑点与手续费def set_slip_fee(context): # 将滑点设置为0 set_slippage(FixedSlippage(0)) # 根据不同的时间段设置手续费 dt=context.current_dt log.info(type(context.current_dt)) if dt>datetime.datetime(2013,1, 1): set_commission(PerTrade(buy_cost=0.0003, sell_cost=0.0013, min_cost=5)) elif dt>datetime.datetime(2011,1, 1): set_commission(PerTrade(buy_cost=0.001, sell_cost=0.002, min_cost=5)) elif dt>datetime.datetime(2009,1, 1): set_commission(PerTrade(buy_cost=0.002, sell_cost=0.003, min_cost=5)) else: set_commission(PerTrade(buy_cost=0.003, sell_cost=0.004, min_cost=5))'''================================================================================每天交易时================================================================================'''def handle_data(context, data): if g.if_trade==True: # 计算现在的总资产,以分配资金,这里是等额权重分配 g.everyStock=context.portfolio.portfolio_value/g.N # 获得今天日期的字符串 todayStr=str(context.current_dt)[0:10] # 获得因子排序 a,b=getRankedFactors(g.factors,todayStr) # 计算每个股票的得分 points=np.dot(a,g.weights) # 复制股票代码 stock_sort=b[:] # 对股票的得分进行排名 points,stock_sort=bubble(points,stock_sort) # 取前N名的股票 toBuy=stock_sort[0:g.N].values # 对于不需要持仓的股票,全仓卖出 order_stock_sell(context,data,toBuy) # 对于不需要持仓的股票,按分配到的份额买入 order_stock_buy(context,data,toBuy) g.if_trade=False #6#获得卖出信号,并执行卖出操作#输入:context, data,toBuy-list#输出:nonedef order_stock_sell(context,data,toBuy): #如果现有持仓股票不在股票池,清空 list_position=context.portfolio.positions.keys() for stock in list_position: if stock not in toBuy: order_target(stock, 0)#7#获得买入信号,并执行买入操作#输入:context, data,toBuy-list#输出:nonedef order_stock_buy(context,data,toBuy): # 对于不需要持仓的股票,按分配到的份额买入 for i in range(0,len(g.all_stocks)): if indexOf(g.all_stocks[i],toBuy)>-1: order_target_value(g.all_stocks[i], g.everyStock)#8#查找一个元素在数组里面的位置,如果不存在,则返回-1#输入:元素,对应数组#输出:-1def indexOf(e,a): for i in range(0,len(a)): if e==a[i]: return i return -1#9#取因子数据#输入:f-全局通用的查询,d-str#输出:因子数据,股票的代码-dataframedef getRankedFactors(f,d): # 获得股票的基本面数据,这个API里面有,g.q是一个全局通用的查询 df = get_fundamentals(g.q,d) # 为了防止Python里面的浅复制现象,采用循环来定义二维数组 res = [([0] * len(f)) for i in range(len(df))] # 把数据填充到刚才定义的数组里面 for i in range(0,len(df)): for j in range(0,len(f)): res[i][j]=df[f[j]][i] # 用均值填充NaN值 fillNan(res) # 将数据变成排名 getRank(res) # 返回因子数据和股票的代码(这个是因为沪深300指数成分股一直在变,如果用未来的沪深300指数成分股在之前可能有一些股票还没上市) return res,df['code']#10#把每列原始数据变成排序的数据#输入:r-list#输出:r-listdef getRank(r): # 定义一个临时数组记住一开始的顺序 indexes=list(range(0,len(r))) # 对每一列进行冒泡排序 for k in range(len(r[0])): for i in range(len(r)): for j in range(i): if r[j][k] < r[i][k]: # 交换所有的列以及用于记录一开始的顺序的数组 indexes[j], indexes[i] = indexes[i], indexes[j] for l in range(len(r[0])): r[j][l], r[i][l] = r[i][l], r[j][l] # 将排序好的因子顺序变成排名 for i in range(len(r)): r[i][k]=i+1 # 再进行一次冒泡排序恢复一开始的股票顺序 for i in range(len(r)): for j in range(i): if indexes[j] > indexes[i]: indexes[j], indexes[i] = indexes[i], indexes[j] for k in range(len(r[0])): r[j][k], r[i][k] = r[i][k], r[j][k] # 因为Python是引用传递,所以其实这个可以不用返回值也行,当然如果你想用另外一个变量来存储排序结果的话可以考虑返回值的方法 return r#11#用均值填充Nan#输入:m-list#输出:m-listdef fillNan(m): # 计算出因子数据有多少行(行是不同的股票) rows=len(m) # 计算出因子数据有多少列(列是不同的因子) columns=len(m[0]) # 这个循环是对每一列进行操作 for j in range(0,columns): # 定义一个临时变量,用来存储每列加总的值 sum=0.0 # 定义一个临时变量,用来计算非NaN值的个数 count=0.0 # 计算非NaN值的总和和个数 for i in range(0,rows): if not(isnan(m[i][j])): sum+=m[i][j] count+=1 # 计算平均值,为了防止全是NaN,如果当整列都是NaN的时候认为平均值是0 avg=sum/max(count,1) for i in range(0,rows): # 这个for循环是用来把NaN值填充为刚才计算出来的平均值的 if isnan(m[i][j]): m[i][j]=avg return m#12#定义一个冒泡排序的函数#输入:numbers是股票的综合得分-list#输出:indexes是股票列表-listdef bubble(numbers,indexes): for i in range(len(numbers)): for j in range(i): if numbers[j][0] < numbers[i][0]: # 在进行交换的时候同时交换得分以记录哪些股票得分比较高 numbers[j][0], numbers[i][0] = numbers[i][0], numbers[j][0] indexes[j], indexes[i] = indexes[i], indexes[j] return numbers,indexes'''================================================================================每天收盘后================================================================================'''# 每日收盘后要做的事情(本策略中不需要)def after_trading_end(context): return |
来源聚宽文章:https://www.joinquant.com/post/1399
# 标题:【量化课堂】多因子策略入门
# 作者:JoinQuant量化课堂


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
2022-03-10 值表达式和方法表达式
2022-03-10 flowable查询
2022-03-10 flowable异常策略分类
2022-03-10 vue跨界域名报错,后台解决方法(未实测,仅供参考)
2020-03-10 微信小程序,下拉,可选择手动输入