

Python量化交易学习笔记(十三)——按规则选股
下载数数据深沪6000多家公司、扩展因子、测试选股规则后,按照规则进行选股的过程。
选股规则
本文就选股规则所测试规则相同,即:
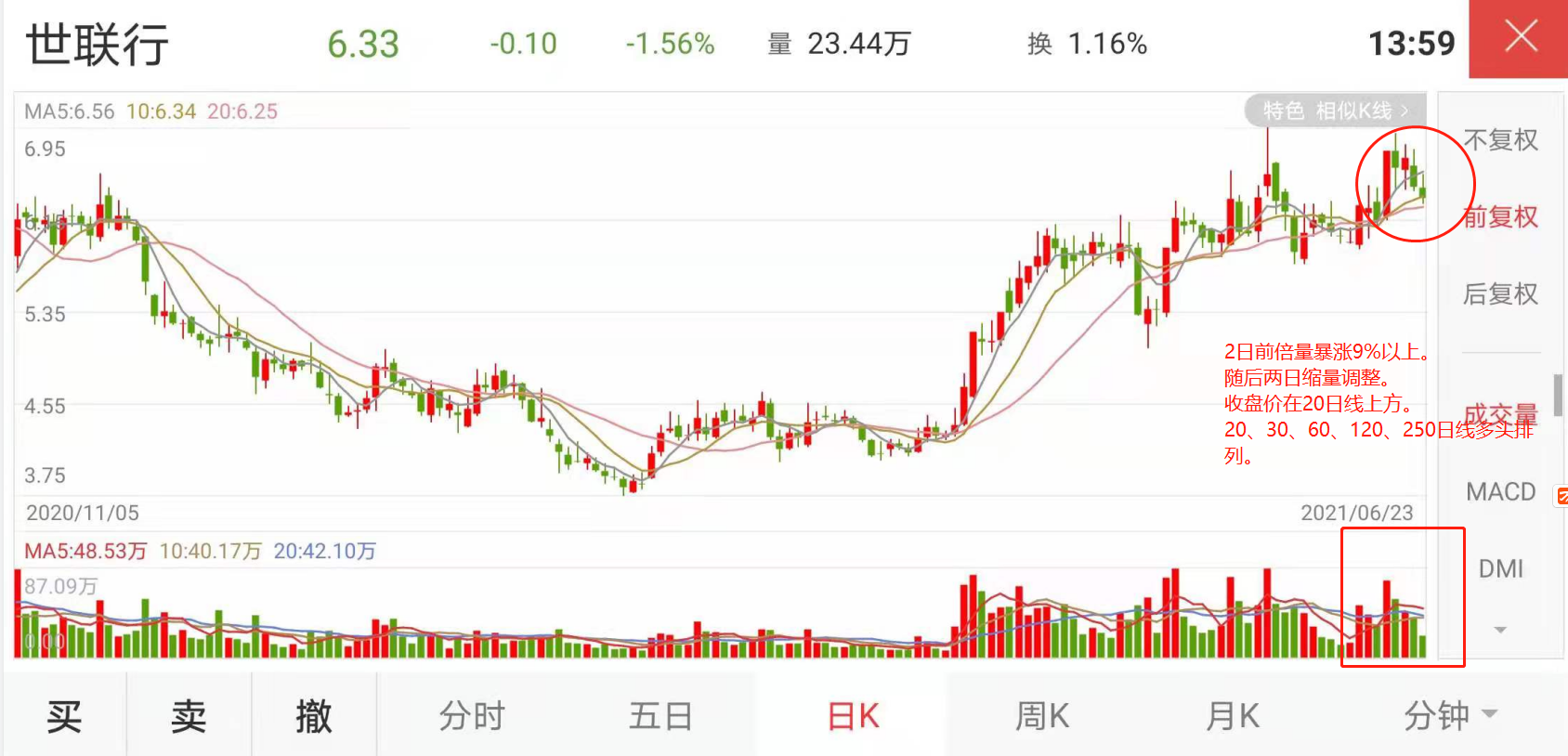
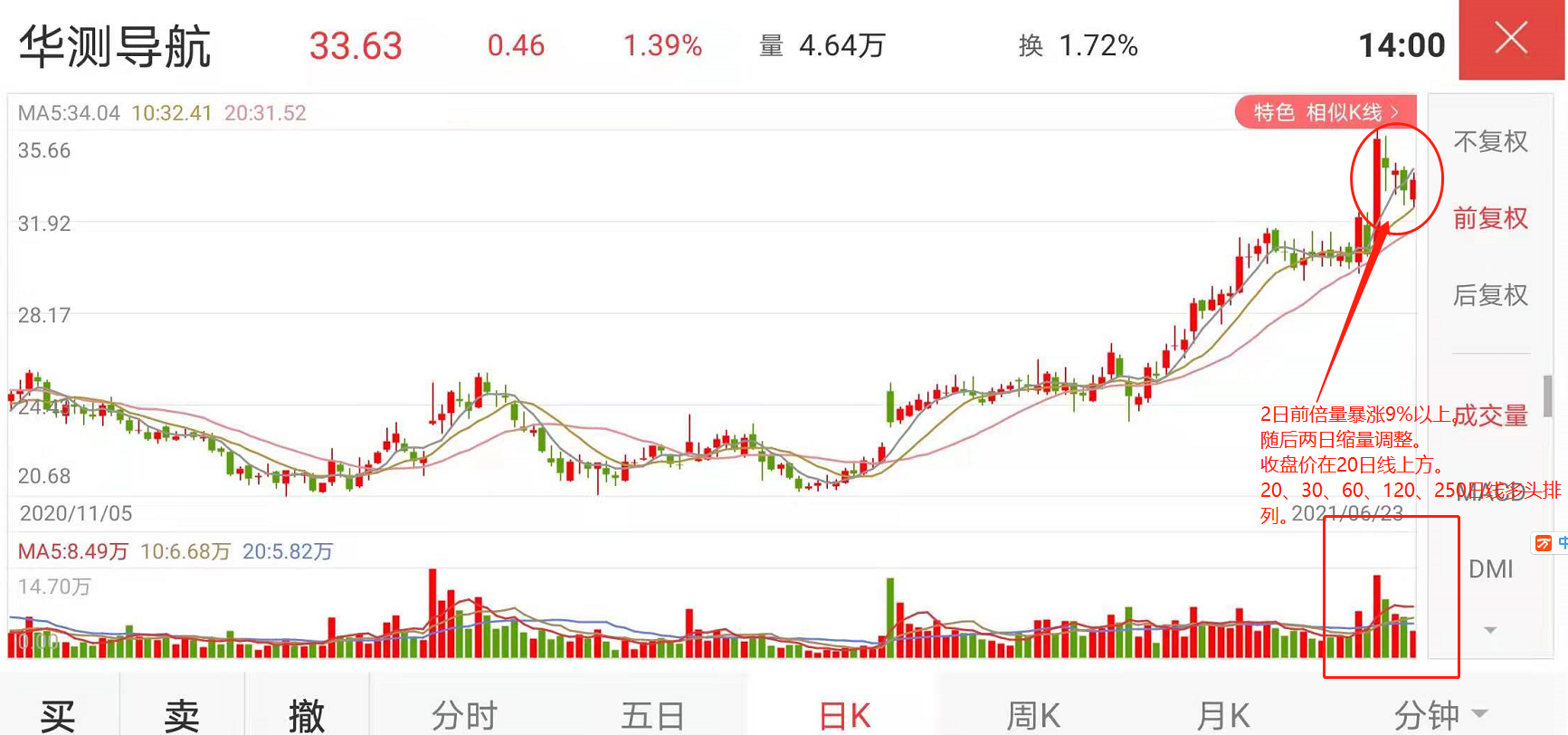
- 2日前倍量暴涨9%以上。
- 随后两日缩量调整。
- 收盘价在20日线上方。
- 20、30、60、120、250日线多头排列。
- 选股规则代码如下:
-
12345678
condition=df['value_boom_2a'].iloc[-1]and\df['volume_2a'].iloc[-1] >=2*df['volume_3a'].iloc[-1]and\df['volume_2a'].iloc[-1] > df['volume_1a'].iloc[-1]and\df['volume_2a'].iloc[-1] > df['volume'].iloc[-1]and\df['close'].iloc[-1] < df['close_2a'].iloc[-1]and\df['close_1a'].iloc[-1] < df['close_2a'].iloc[-1]and\df['close'].iloc[-1] > df['ma_20'].iloc[-1]anddf['ma_30'].iloc[-1] > df['ma_60'].iloc[-1] \> df['ma_120'].iloc[-1] > df['ma_250'].iloc[-1]结果分析
选出的所有满足选股规则的股票,都会保存在csv文件中。
本文发布日期为2021年6月23日,当日只选出2只符合条件的股票,耗时880秒,csv文件截图如下。 -
1234
C:\Python38\python.exe F:/test/src/com/gzh/demo49.pysz002285sz300627程序所耗时间:880.6239831447601 -
通了基于历史数据的规则验证以及选股流程。这样就可以先找到靠谱的规则,然后在每日盘后自动选出满足规则的股票,再做交易。有历史数据分析做支撑,至少不会成为韭菜里最高的那一波。
-
 1234567891011121314151617181920212223242526272829303132333435
1234567891011121314151617181920212223242526272829303132333435importdatetimeimporttimeimportsysimportosimportpandas as pd# 获取当前目录proj_path=os.path.dirname(os.path.abspath(sys.argv[0]))+'/../'if__name__=='__main__':# 程序开始时的时间time_start=time.time()# 读入股票代码stk_code_file=proj_path+'data/tdx/all_codes.csv'codes=pd.read_csv(stk_code_file, encoding='unicode_escape')['code']code_list=[]forcodeincodes:input_file=proj_path+'data/extension/d/hard_rules/'+code+'.csv'df=pd.read_csv(input_file, index_col=0)condition=df['value_boom_2a'].iloc[-1]and\df['volume_2a'].iloc[-1] >=2*df['volume_3a'].iloc[-1]and\df['volume_2a'].iloc[-1] > df['volume_1a'].iloc[-1]and\df['volume_2a'].iloc[-1] > df['volume'].iloc[-1]and\df['close'].iloc[-1] < df['close_2a'].iloc[-1]and\df['close_1a'].iloc[-1] < df['close_2a'].iloc[-1]and\df['close'].iloc[-1] > df['ma_20'].iloc[-1]anddf['ma_30'].iloc[-1] > df['ma_60'].iloc[-1] \> df['ma_120'].iloc[-1] > df['ma_250'].iloc[-1]ifcondition:code_list.append(code)print(code)pd.DataFrame(data=code_list, columns=['code']).to_csv(proj_path+'data/temp/'+datetime.datetime.strftime(datetime.datetime.now(),'%Y-%m-%d-%H-%M-%S')+'.csv', index=False)# 程序结束时系统时间time_end=time.time()print('程序所耗时间:', time_end-time_start)为了便于相互交流学习,新建了微信群,感兴趣的读者请加微信。

分类:
Apython量化交易


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~