【第二次个人作业】结对作业Core第一组:四则运算生成PB16061082+PB16120517
【整体概况】
1.描述最终的代码的实现思路以及关键代码。
2.结对作业两个人配合的过程和两个人分工。
3.API接口文档和两个组的对接。
4.效能分析,优化分析和心得体会。
【代码实现】
一. 实现功能:
像《构建之法》的人物阿超那样,写一个能自动生成小学四则运算题目并给出答案的命令行 “软件”, 如果我们要把这个功能放到不同的环境中去(例如,命令行,Windows 图形界面程序,网页程序,手机App),就会碰到困难,因为目前代码的普遍问题是代码都散落在main ( )函数或者其他子函数中,我们很难把这些功能完整地剥离出来,作为一个独立的模块满足不同的需求。
二. 实现思路
首先,题目对于计算数来说,有整数,小数,分数三种区分,所以我们分别考虑它们的数据结构:
整数的话就用int型,用自带的加减乘除来进行运算。然后通过一个函数来把算出来的整数转化为字符串。
1 string translate(int num) 2 { 3 int j = 1; 4 string str = ""; 5 if (num eq 0) 6 { 7 str = str + '0'; 8 return str; 9 } 10 char tem; 11 while (num / j != 0) 12 { 13 j *= 10; 14 } 15 j /= 10; 16 while (j != 1) 17 { 18 tem = '0' + num / j; 19 str = str + tem; 20 num = num % j; 21 j /= 10; 22 } 23 tem = '0' + num; 24 str = str + tem; 25 return str; 26 }
小数的话用浮点数来进行运算。然后结果可以分别对整数位和小数位用上面的translate来转化为字符串。
分数的话就比较复杂,我们设计了一个结构体来存储分数,在内部我们全部用真分数进行运算,并且定义了它的一系列运算。在计算过程中,每计算一次分数,就要调用分数的化简来化简这个分数,再参与下一次运算,最后显示的时候,我们分别对真分数,假分数和整数进行显示。
typedef struct fenshu { int fenzi; int fenmu; }fenshu;
运算:
1 fenshu Add(fenshu a1, fenshu a2) 2 { 3 fenshu a3; 4 a3.fenmu = a1.fenmu*a2.fenmu; 5 a3.fenzi = a1.fenzi*a2.fenmu + a1.fenmu*a2.fenzi; 6 return a3; 7 } 8 9 fenshu Sub(fenshu a1, fenshu a2) 10 { 11 fenshu a3; 12 a3.fenmu = a1.fenmu*a2.fenmu; 13 a3.fenzi = a1.fenzi*a2.fenmu - a1.fenmu*a2.fenzi; 14 return a3; 15 } 16 17 fenshu chen(fenshu a1, fenshu a2) 18 { 19 fenshu a3; 20 a3.fenmu = a1.fenmu*a2.fenmu; 21 a3.fenzi = a1.fenzi*a2.fenzi; 22 return a3; 23 } 24 25 fenshu chu(fenshu a1, fenshu a2) 26 { 27 fenshu a3; 28 a3.fenmu = a1.fenmu*a2.fenzi; 29 a3.fenzi = a1.fenzi*a2.fenmu; 30 return a3; 31 }
1 int GreatCommon(int fenzi, int fenmu) 2 { 3 int n; 4 do 5 { 6 n = fenzi % fenmu; 7 fenzi = fenmu; 8 fenmu = n; 9 10 } while (n != 0); 11 return fenzi; 12 } 13 14 void Simplify(fenshu &sample) 15 { 16 int max; 17 max = GreatCommon(sample.fenzi, sample.fenmu); 18 sample.fenmu /= max; 19 sample.fenzi /= max; 20 }
1 string translate_fenshu(fenshu sample) 2 { 3 string str = ""; 4 if (sample.fenzi eq 0) 5 { 6 str = "0"; 7 return str; 8 } 9 if (sample.fenmu == 1) 10 { 11 str = translate(sample.fenzi); 12 return str; 13 } 14 else 15 { 16 if (sample.fenzi > sample.fenmu) 17 { 18 int k = sample.fenzi / sample.fenmu; 19 int j = sample.fenzi % sample.fenmu; 20 str += translate(k) + '`' + translate(j) + '/' + translate(sample.fenmu); 21 } 22 else 23 { 24 str += translate(sample.fenzi) + '/' + translate(sample.fenmu); 25 } 26 } 27 //str += ''; 28 return str; 29 }
好,接下来数据结构就介绍好了,接下来介绍算法实现:
算法实现呢,我们从
“即任何两道题目不能通过有限次交换+和×左右的算术表达式变换为同一道题目。例如,23 + 45 = 和45 + 23 = 是重复的题目,6 × 8 = 和8 × 6 = 也是重复的题目。3+(2+1)和1+2+3这两个题目是重复的,由于+是左结合的,1+2+3等价于(1+2)+3,也就是3+(1+2),也就是3+(2+1)。但是1+2+3和3+2+1是不重复的两道题,因为1+2+3等价于(1+2)+3,而3+2+1等价于(3+2)+1,它们之间不能通过有限次交换变成同一个题目。”
得到了启发,因为他的意思是所有的运算步骤只要有不一样的就不是一个表达式,如果运算过程都一样(如果是加法乘法的话,两边操作数交换一下如果一样也是同一种运算过程)的话就是同一个表达式,而生成的不能是同一个表达式。这样的话,就比较注重运算的过程,我就自然而然地想到了从生成后缀表达式入手,这样的话有两个好处:
①相比于表达式树方案,他的速度更快,因为表达式树每生成一颗就要跟前面的几百棵树进行比较,而且遇到加法乘法还得树的两个子树交换比较,这样的话效率就很低,然后我们的思路是生成后缀表达式,后缀表达式就可以很好地把运算过程来展现出来, 比较的时候只需要一系列条件判断,判断两个字符串就可以解决两个表达式相不相同的问题。
②我们可以边生成边计算出表达式的值,而不用翻来覆去地计算,这样的话效率会大大地提升。
所以我们的思路是先随机生成一个合理的后缀表达式,然后生成的过程中就把结果计算出来,然后比较一下新生成的跟之前的是否一样,如果一样的话就再生成一个新表达式,表达式生成之后,就可以把后缀表达式再转化为中缀表达式来输出。
这里只展示一下整数表达式的生成,因为其他的运算都定义了,最后只需要加几个条件判断,把其他的运算加进去。


1 int Generate_int() 2 { 3 srand((unsigned)time(NULL)); 4 map<string, int>::iterator iter; 5 string op = ""; 6 string str1 = "", str2 = ""; 7 char sign; 8 int i = 1, j = 0, temp, num1, num2, flag, result; 9 stack<int> num; 10 for (j = 0; j < num_ques; j++) { 11 op = ""; 12 for (i = 1; i < num_op; i++) 13 { 14 sign = randsign(); 15 num1 = (int)scalemin_op + rand() % (scalemax_op + scalemin_op - 1); 16 num2 = (int)scalemin_op + rand() % (scalemax_op + scalemin_op - 1); 17 if (i != 1) 18 { 19 num1 = num.top(); 20 num.pop(); 21 } 22 23 flag = Operate(sign, num1, num2); 24 while (flag eq - 1 || flag eq - 2 || flag eq - 3 || flag eq - 4) 25 { 26 num2 = (int)scalemin_op + rand() % (scalemax_op + scalemin_op - 1); 27 flag = Operate(sign, num1, num2); 28 } 29 num.push(flag); 30 31 if (i eq 1) 32 { 33 str1 = translate(num1); 34 str2 = translate(num2); 35 op = op + str1 + " " + str2 + " " + sign; 36 } 37 else 38 { 39 str2 = translate(num2); 40 op = op + " " + str2 + " " + sign; 41 } 42 } 43 result = num.top(); 44 op = op + ' '; 45 if (result > result_max || result < result_min) 46 { 47 j--; 48 continue; 49 } 50 51 iter = mapException.find(op); 52 if (iter != mapException.end()) 53 { 54 j--; 55 } 56 else 57 { 58 mapException.insert(pair<string, int>(op, result)); 59 } 60 num.pop(); 61 string result_str; 62 result_str = translate(result); 63 ExpTranslate(op, result_str); 64 } 65 return 0; 66 }
二.dll封装:
①先创建了一个.dll的空项目。
②加入一个头文件"package.h",里面放入我们所有include的头文件和定义的结构体,并且用这个语句来把我们需要对外提供的接口都extern。
extern "C++" _declspec(dllexport) int Setting(canshu sample); extern "C++" _declspec(dllexport) int jiexi(string can);
③加入一个”fun.cpp"文件,首先include“package.h”,然后把我们写的所有函数都复制进来。
④加一个“MAIN.cpp”文件,里面加入如下语句:
#include"windows.h" BOOL APIENTRY Main(HANDLE HMODULE, DWORD ul_reason_for_call, LPVOID lpReserved) { switch (ul_reason_for_call) { case DLL_PROCESS_ATTACH: break; case DLL_THREAD_ATTACH: break; case DLL_THREAD_DETACH: break; case DLL_PROCESS_DETACH:break; default: break; } return TRUE; }
这样在调试就可以看到.dll,.lib文件了。
三.API接口与自己的VS测试程序对接口的调用:(以其中的输入为string结构体,写文件方式来说明)
我们的四则运算生成算法怎么用:
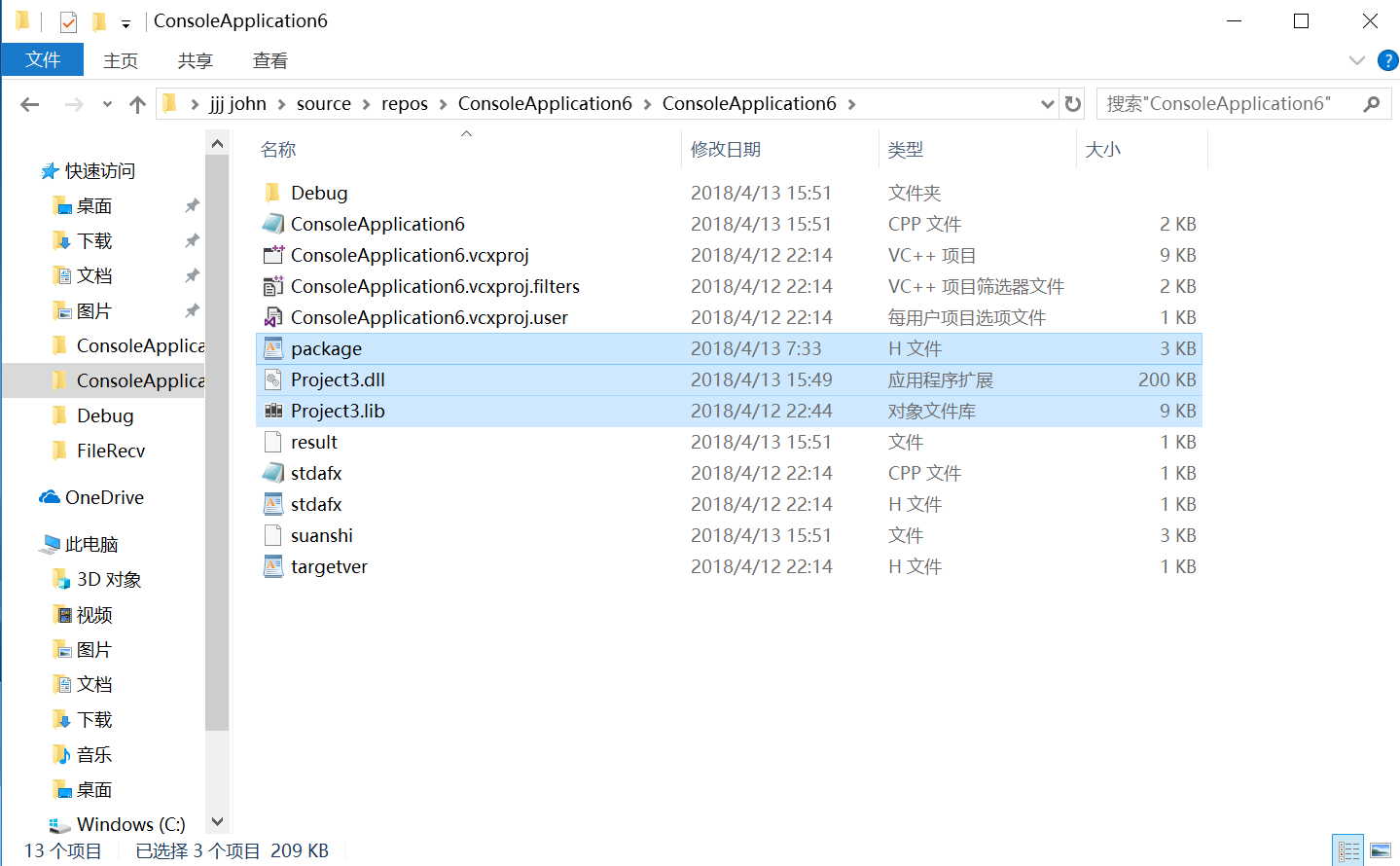
把我们提供的有黑色的三个文件:project3.dll,project3.lib,package.h,放到你们的项目中去。

接下来分别一一介绍他们的功能和注意事项:
首先include好我们的头文件: #include "package.h"
然后,连接一下对象文件库: #pragma comment(lib,"Project3.lib")
然后,建立一个叫canshu的结构体,结构体定义如下:
typedef struct canshu {
string num_ques;
string scalemax_op;
string num_op;
string num_float;
string is_real;
string is_decimal;
string is_power;
string is_add;
string is_sub;
string is_mul;
string is_div;
string result_max;
}canshu;
它们都要被赋好值,不赋值的话按照默认的标准值来进行。接下来一一介绍它们传参的注意事项,接口检查我们已经帮你们做好了。
首先:他们都是string的类型,并且内容只能为数字字符,不能有其他字符,不然会返回错误信息。
canshu sample;//初始化一个结构体,结构体定义见上面
sample.is_add = "1";
sample.is_sub = "1";
sample.is_mul = "1";
sample.is_div = "1";
sample.is_power = "1";
//五种运算符的支持与否,他们之间没有任何制约,能够支持任意N种运算结合。
它们的输入参数只能为字符串"1"或者"0",否则是非法输入,返回错误信息。
sample.is_real = "1";
sample.is_decimal = "0";
//3种模式的支持与否:
is_real = "1",is_decimal = "1"; 支持小数运算。
is_real = "1",is_decimal = "0"; 支持分数运算。
is_real = "0",is_decimal = "1"; 支持小数运算。
is_real = "0",is_decimal = "0"; 支持整数运算。
它们的输入参数只能为字符串"1"或者"0",否则是非法输入,返回错误信息。
sample.num_float = "3";
// 浮点数的小数位数 在5以内,否则报错。必须是数字字符串。
sample.num_op = "5";
// 操作符的数量,也就是算式长度 小于等于10,否则为非法输入,报错。
sample.scalemax_op = "10";
//操作数最大范围 支持乘方(乘法)的时候只能20以内,没有的话500,否则为非法输入。
sample.result_max = "1000";
//结果的最大值
sample.num_ques = "100";
//问题的数量:10000以内
好,这样就可以用我们的核心函数了。
Setting(sample);
这样就在项目目录里面生成了两个文件,一个叫result,记录他的结果,另一个叫suanshi,记录他的算式。
可以展示一下:
输入:

支持加减乘除乘方,分数运算。
输出:


但是如果输入为这样:
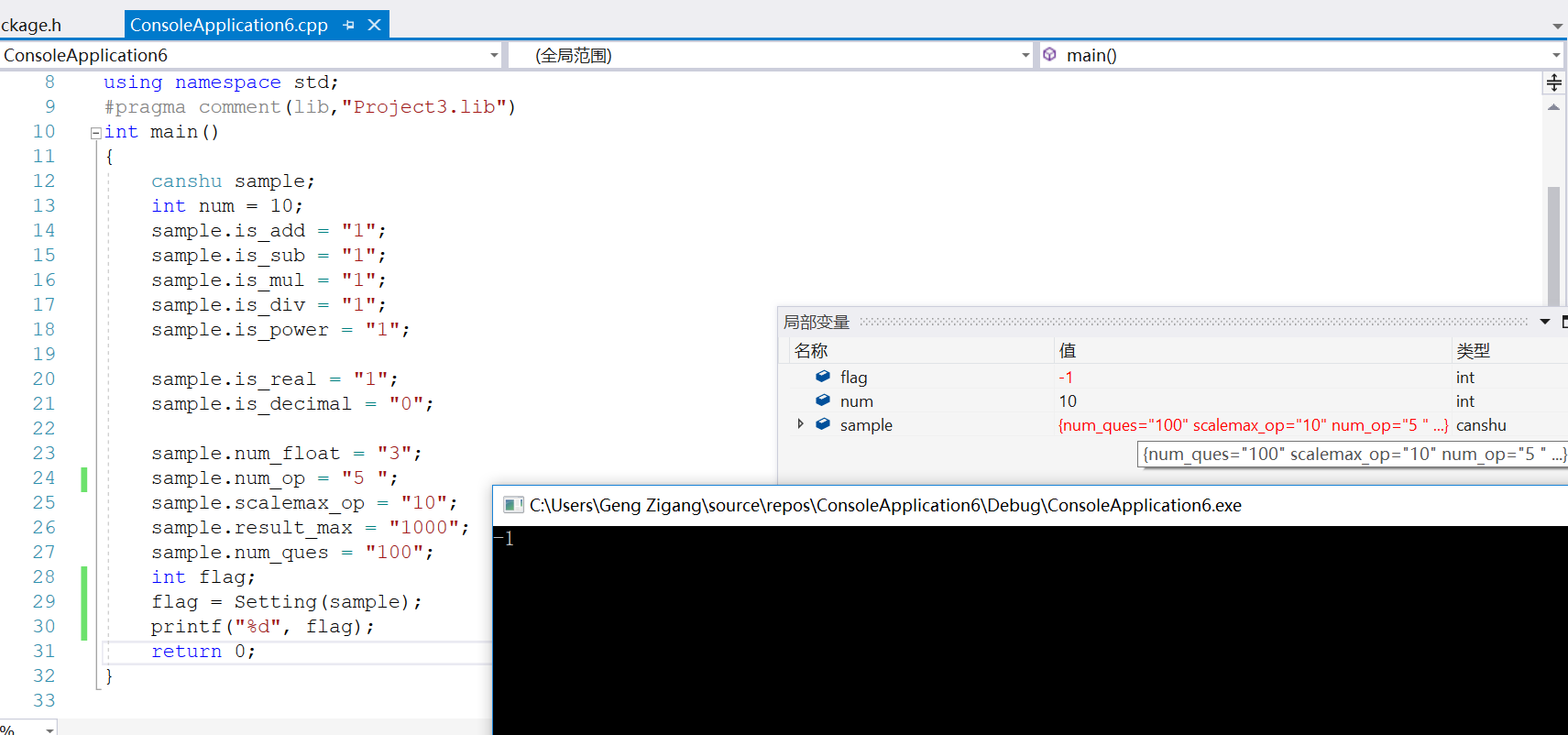
注意这里,为非法输入,因为num_op中的5后面出现空格,他不是纯数字,他还有其他空格。
所以setting的返回值就是-1,这就是非法输入的错误信息。
如果一切正常,flag应为0。
四.结对编程中遇到的BUG:
①将随机数产生封装进函数时的BUG

如图所示,开始时打算把生成随机数与生成运算符放在同一个函数里,通过生成的随机数随机生成运算符。但是发现在调用这个函数时,每次返回的运算符都是一样的。我们一起讨论,想了想,觉得可能是每次调用函数时,会经过系统工作栈产生与释放的过程,因此srand函数定格的点都一样,生成的随机数也一样。
解决方法:
将srand函数不放进辅助功能调用函数中,而是直接放进生成算式的主功能函数中,使得随机数能够从生成算式函数调用开始便开始固定一个点,一直到生成式子完毕,期间不作改变这个点,进而使得生成的随机数能够在生成运算式的整个过程中都在变化。
分析:
碰到这个BUG主要是因为不清楚srand函数的具体底层机制,不懂的情况下很难避免,调试方法主要是使用编译器自带的Debug功能。
②string类型变量使用过程中遇到的BUG
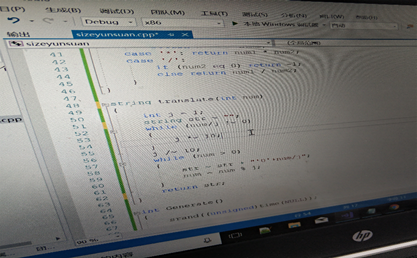
如图所示,在编写将int型数值转化为string数值的函数时,误写成了str=str+ ” ’0’+num/j”,想保存的是‘0’+num/j 后的字符,但实际上保存的是“’0’+num/j”字符串,因此,这就出错了。这属于知识型失误。
解决办法:增加一个char型字符变量,记为temp,令temp=’0’+num/j; ,然后令str=str+temp;
③运算结果溢出问题
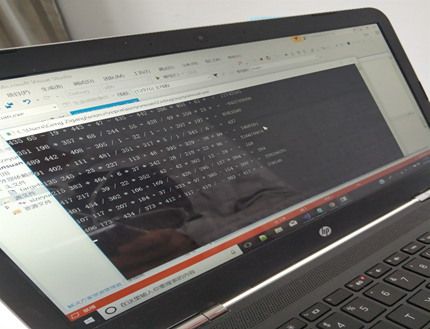
如图,刚开始设置时,没考虑自己的操作数的数字大小以及式子的长度,且答案储存的变量形式为int,很容易导致溢出。同时,后面如果加上了乘方之后,就更容易发生溢出了。
解决方法:我们的处理方法是控制操作数的数字大小以及式子的长度,使得理论上可能出现的最大的运算结果在int类型变量可以表示的范围内。减少允许选择的乘方的的次数。
分析:遇上这个BUG,主要是没有考虑到乘法容易导致运算结果变得非常大。这个BUG的避免方法在于在设置构架时,在考虑数值运算的过程中,就应该考虑是否会发生溢出问题,进而选择合适的范围。调试BUG的方法,也是通过编译器中的Debug功能,逐步观察变量变化。
③分式运算过程溢出问题
在产生分数的式子中,经常会出现一些奇奇怪怪的东西,如‘,’ ‘、’这些根根本就不应该在分式计算式子中出现的东西,而且在随机生成分式算是时,程序还会随机崩溃。很玄学。
分析:既然打印输出时出了问题,我们先是认为,可能是我们在将分式转化为可以打印的字符串时出现了问题,于是就开始用编译器自带的Debug功能观察将分式转化为字符串的函数。结果,居然发现,传入函数的参数发生了溢出,从而导致打印出了一些奇奇怪怪的东西。之后,我们就纳闷是哪里发生了问题,因为我们的操作数大小和数目经过产生整数运算式子结果溢出的教训后,已经进行修改了,但是还是发生了溢出。我们开始时以为是结果又奇怪的发生溢出了,既然发生溢出,我们便尝试在式子结果处添加了结果范围约束条件,但是程序还是照样存在溢出问题。这时,我们就觉得不对劲,应该是运算过程的中间阶段发生了溢出,在将分数运算的运算符操作一一排查后,终于发现了问题,原来在进行分数运算的过程中,由于有时候分母十分大,进行同分操作时,有可能使得分子发生溢出,进而导致我们转化分数为字符串的过程中,发生错误,将溢出的数字转化为一些奇怪的如‘,’‘、’ 符号。这个BUG,也是属于溢出问题,是由我们在进行架构时,未妥善考虑可能发生溢出的位置导致的。
解决方法:对运行的每一步结果进行控制,若过大则重新生成表达式。
④浮点数计算精度问题
这个问题比较恶心,调试了很久,应该是涉及到计算机底层储存浮点数问题。我们出现的问题是,在进行浮点数运算时,结果通常与实际结果相差一点,而且相差的值多少取决于参与运算的数值的大小,若数值大,则误差大,数值小,则误差小,就像系统误差一样,总是会按一定比例差一点。
分析:
这个解决过程比较曲折。刚开始时,是觉得浮点数运算机制出错了,然后对浮点数运行机制逐一排查,但发现并没有问题。这个时候,我们只能转向去排查浮点数显示转化为字符串的问题。
我们的浮点数转化的主要思路是,根据用户设置的精度,对浮点数进行四舍五入取整。所以浮点数转化为字符串函数,就是将传入的浮点数,先根据精度需要加上(0.5/精度)并截取一定长度,并将由此所得的浮点数转化为字符串进行输出。如图所示

而这,便使得在输出中显示的浮点数与实际产于运算的浮点数变量,在数值上有一定的差距,这就使得实际结果与显示应得结果产生了误差。终于找到了错误,我们便开开心心的开始进行修改,我们的方案是,添加一个修改精度的函数,用来判断显示时的浮点数与实际参与运算的浮点数是否相同,如果相同,则不做修改,如果不同,则把产于运算的浮点数修改为显示时的浮点数。正当我们满心欢喜的把修改后的程序再次跑一遍时,发现问题并没有解决,结果还是与我们用计算器按出来的结果具有一点细小的误差。
于是,我们又把眼光重新转向了转化浮点数为字符串的函数中。这次,为了显示浮点数在函数内部究竟发生了什么转换,我们特地把显示的位数增加了,然后,就发现了浮点数有一个很诡异的现象。那就是,浮点数的实际数值并不是与它本应该是的数值一样的。
举个例子,比如用浮点数表示的float=3+0.80,结果将它显示出来后,就可能有两种情况,一种如3.799999,一种为3.800000,而且更让人摸不着头脑的是,它们好像还是随机出现的,即我们是无法控制的。因此,截取该浮点数一定的精度时,同一值的浮点数,就可能会出现两种情况,一种是3.79,一种是3.80,而这,会影响参与运算的每一浮点数以及结果的精度,从而导致了我们计算结果产生的误差。
解决方法:
这个底层问题,确实让我们苦恼了很久,因为浮点数表示这个产生问题完全是由计算机本有的机制控制的,我们无法修改。最后,我们终于想到了一种方法,那就是既然浮点数有这种奇怪的地方,那我们为何不把浮点数先转化为一个整数,由于整数的储存与显示一定是固定的,不会出现浮点数那样不确定,与需要表达的数值有一定差错的情况,所以对该整数进行操作,转化为字符串显示时,就不会出现运算过程与运算结果有误差的情况。
修改后,果然,结果都对了。如下图所示

总结:这种BUG属于不清楚float存储的底层机制,算是因为知识缺陷所遇到的。避无可避,栽一次学一次吧。
【结对编程中两个人配合的体验】
以下是我的PSP表格。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 1140 | 1910 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 60 |
| · Design Spec | · 生成设计文档 | 120 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 10 |
| · Design | · 具体设计 | 240 | 180 |
| · Coding | · 具体编码 | 480 | 480 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 1080 |
| Reporting | 报告 | 180 | 150 |
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 60 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 1350 | 2000 |
在实际的结对编程中,计划以及架构方面,我们是一起进行交流,探讨的,估计花费多少时间,做到哪里,什么时候进度要到哪里,以及包括如何设置控制参数,如何记录算式,如何判别算式是否为重复的等等。
分析完毕后,接下来,便到了具体码代码阶段。为了降低耦合度。便于两人两种不同代码风格理念的高效率融合,我们将主要功能分为了两部分,一则是生成后缀表达式,即核心为生成部分,而第二部分则包括将后缀表达式转化为中缀表达式,将各种数字,如小数,分数,整数,进行化简,并转化为字符串形式进行输出,将core进行ddl封装,即核心为传递输出部分。且在互为领航员的过程中,不对对方的算法想法进行强行的修改,只对一些小编写过程中的小疏漏进行指出,体现了开发的单一性原则。
首先,耿子刚先为驾驶员,欧阳炳濠为领航员,负责指出开发编码过程出现的一些小疏漏。因为算式生成这一功能都相似,应该具有自己独立的体系,耿子刚完成了整数型,分数型,浮点数型算式等一系列的后缀表达式的生成。
然后,欧阳炳濠为驾驶员,耿子刚为领航员,负责指出开发编码过程出现的一些小疏漏。进行了将后缀表达式转化为中缀表达式,将各种数字化简,并转化为字符串形式进行输出部分代码的书写。
最后,到了完善细节的时候,则是两人一起努力,对程序最后产生的将两人所能想到的各种情况进行补充,如入口参数检查,极端情况怎么处理,如何提高代码的效率等。除此之外,还一起思考订正最终程序运行过程中所出现的奇奇怪怪的问题。
体验总结:结对编程过程中,1+1的效率绝对是大于2!在整个开发过程中,同伴起的作用都非常巨大。首先,体现再软件架构上面,因为有同伴进行讨论,因此能让两个人的思维都得以充分运转,在激烈的争论中,两个人互为补充,往往能对所遇到的问题或将遇到的问题认识得更透彻,能很快抓住要点,迅速掌握本质,进而还提高了软件架构的可靠性。其次,还体现在编码过程中,在具体编码的过程中,我们两个人都经常会错写变量名,或者粗心大意,错误使用了一些符号,而这个时候,编译器没有报错,全靠同伴机灵的发现了不对劲的地方,进而得以改正。还有一点,结对过程中,面对面与他人进行交流,一起工作,其实是一种非常愉快的体验,大大提高了工作的积极性。
【结对编程中两个组对接的体验】
首先,我们对接的是第8组的ui,对接的比较顺利,当遇到接口不一样时,我们互相退让了一步,互相改了一下参数,我把输入从int的结构体改为了string的结构体,于是就顺利对接。然后对接的过程中出现了一个非常严重的bug,是他在Qstring赋好值了,一旦传进我的函数里面,字符串就变成了空串,然后我就报错,后来一直不明白这个bug怎么出来的,换了一种思路,把结构体设置成了全局变量,问题得到了解决,最后特别感谢第八组给我们发现的两个bug,第一个是加减乘除乘方都设置成0的时候,我们程序没有处理错误,而是进入了死循环。这是我们以前真的没有考虑到的,第二个bug是浮点数运算的时候,有的精度不太够,这也是我们上面提到的一个bug。
后来,我们对接了第2组的ui,对接的比较顺利,体验非常好,几乎没用什么时间就完美对接成功,然后合作也比较愉快。
然后在群里面看到了第十组是想要文件输出的组,我们想我们这个有两个版本,一个是字符串输出,一个是文件输出,刚好可以满足他们的要求,所以我们赶紧联系了他们,让他们试一试我们的程序,对接过程也比较成功,合作非常愉快。在试的过程中,他们要求我们把输出文件形式改成了.txt文件,然后我们把输入为int结构体的版本找出来给了他们,对接的过程还算比较顺利,就是出现了一个bug就是,总是一进入我的函数就报错,后来我们都没有办法了,突然想到了是不是文件操作有问题,后来把他们程序中的文件操作都注释掉,果然就好了,应该是文件指针重复定义。还有就是我们的一个锅,本来应该把不做入口检测的版本发给他们,发成了做严格的入口检测的版本,后来花费了一段时间去困惑为啥程序这么容易返回输入错误信息。不过总体来说也是对接比较成功,比较顺利的。在原先没有统一规范的情况下做到这样已经很不错了。
我们又试了一下第四组的ui,对接也非常顺利,就是半小时搞定的,出了一个小bug是他们在调用的时候有的参数没有赋值,然后默认为0,造成返回了输入错误信息。后来咨询了一下我们,顺利解决了。
最后,第十二组的UI主动来找我们,我们给他们发布了x64版本的,没过多久,我也没去参加调试bug,他们就把对接好的发了过来,我觉得特别棒。
总的来说,对接的过程是比较顺利的,然后合作也是比较愉快的。(虽然没有人制定统一的接口,但是我们做了5套啊,已经比较满意hhhhhh。输出有两种,写文件,字符串,输入有三种,直接传参,int结构体传参,string结构体传参)这样的话大多数ui组的需要都可以轻松满足。
【课程总结】
学软工也有一段时间了,也有很多想说的话。
首先呢,非常感谢老师跟助教,对我们严要求,然后我们也尽可能去满足这些要求,从中get了一些新的实用的技能。也掌握了一些和别人合作的技巧和方法。但是嘞,还是有一些意见想要提出来,只为了让这门课变得更好,我有一些想法和建议:
第一,除了编程作业,课后作业以及读书笔记,那些东西确实认真做的话很有意思,收获也很大,但是现在编程作业,专业课任务负担已经很重了,我周围没人会认认真真地再去完成那么多的文字作业。然后这些作业就流于形式,从中不能获得一点好处但是要花费一些不长不短的时间。
第二,我觉得那些构建之法,人月神话之类的书,纸上得来终觉浅,应该有了一定的工作经验,实践经验回头再去品味,像我这种只学了数据结构,没有任何实践经验的同学,根本无法理解其中的深意,看了也没有体会。我觉得现阶段最重要的是熟练运用一门语言,而不是抛开编程经历去大谈方法论。
第三,我们学习新东西,都只能自己去google,只知道按照教程一步一步按部就班地做,这么短的时间也无法理解这么做是为什么,所以过程中出了错,只能在那里干着急,只能重新按照教程做一遍,问同学也没有一个懂得,因为他们按照教程一步一步做就做对了。这样的学习我不知道是不是好的。
最后谢谢老师,希望我们可以一起把这门课变得让人更加有收获一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号