

idea搭建flink环境
1.打开idea,选择new project,跳转至如下界面:
2.单击next 下一步,输入项目名称,单击finish完成
3.在项目main项目下新建scala目录,并新建文件,文件名称为 hello.scala
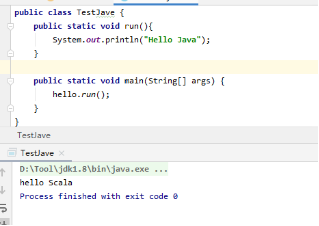
4.新建文件之后,进入helllo.scala文件,会弹出添加sdk,添加自己版本的scala就可以。完成之后可以新建添加如下代码,测试Java和scala之间的互相调用。
5. 在maven项目下引入如下配置:
<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.11.12</scala.version> <scala.binary.version>2.11</scala.binary.version> <flink.version>1.6.1</flink.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> </dependencies>
6.新建一个flink测试:
package it.bigdata.flink.study import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ //流处理 word count object SteamWordCount { def main(args: Array[String]): Unit = { //创建流处理的执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(8) //接受一个socket文本流 val inputDataStream: DataStream[String] = env.socketTextStream("10.18.35.155", 777) // 进行转换处理统计 inputDataStream .flatMap(_.split(" ")) .filter(_.nonEmpty) .map((_,1)) .keyBy(0) .sum(1) .print() env.execute("word count") } }
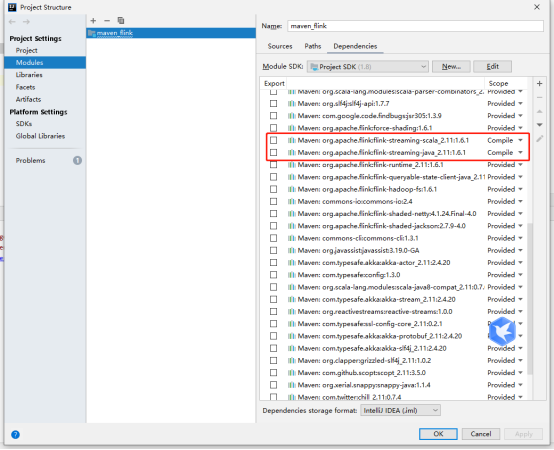
6.1问题一
若出现 StreamExecutionEnvironment 类没有发现时,将此处,改为compile
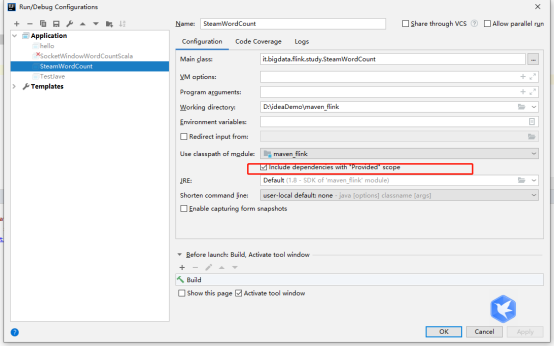
6.2问题二
若还报错,java.lang.ClassNotFoundException: org.apache.flink.runtime.state.StateBackend
打开edit configuration ,在此处勾选即可
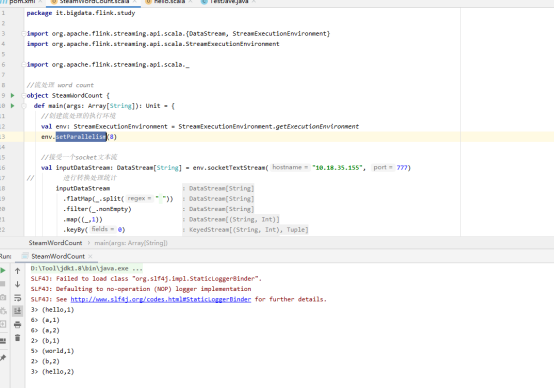
7. 提前进入服务器,使用nc -lk 777,然后运行第一个flink,运行效果如下
author@nohert

 浙公网安备 33010602011771号
浙公网安备 33010602011771号