

hive环境搭建
注: 本次搭建是基于已经搭建好的hadoop3集群搭建的,故对于hadoop3搭建不做介绍,且本次搭建是以本地模式为例
特别关注:由于hadoop3xy不兼容hive2xy,如使用hive安装会出现各种问题,故使用hive3作为本次环境搭建
1.安装mysql
1.1安装mysql数据库
yum install -y mysql-server
1.2对字符集进行设置: 进入/etc/my.cnf文件中,加入default-character-set=utf8,代码如下:
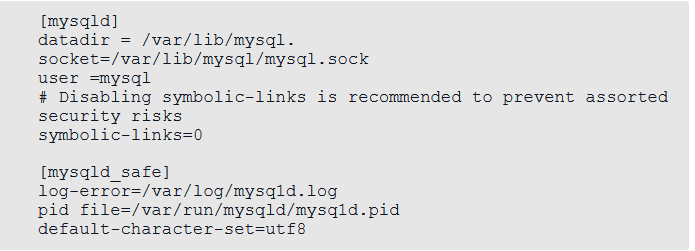
1.3启动mysql服务,代码如下:
service mysqld start #启动mysql服务
service mysqld status #查看mysql是否启动
systemctl enable mysqld #设置myql开机启动1
systemctl daemon-reload #设置myql开机启动2
1.4设置myql的root密码
mysql -uroot -p ,第一次进入时,默认密码为空,输入密码时直接回车可直接进入 set password for 'root'@'localhost' = password('123456'); 设置密码为123456
1.5新建root1用户,并且赋予两个用户远程登陆权限;
create user 'root1'@'%' identified by '123456'; #如果使用root作为连接用户此步可以省略,本次安装使用root用户作为连接用户 grant all on *.* to'root1'@'%'; #如果使用root作为连接用户此步可以省略,本次安装使用root用户作为连接用户
grant all on *.* to'root'@'%';
2.配置hive 环境 (/home/hive/conf):(本次环境搭建使用hive3.1.2版本,下载地址: http://archive.apache.org/dist/)
2.1配置hive-env.sh ,进入conf目录,cp hive-env.sh.template hive-env.sh ,打开 hive-env.sh文件:
export HADOOP_HOME=/app/hadoop-3.2.1 export HIVE_CONF_DIR=/app/hive-3.1.2/conf
2.2配置hive-site.xml,进入conf目录,cp hive-default.xml.template hive-site.xml,打开hive-env.sh文件,对于如下内容有则修改,无则新增:
<property> <name>system:java.io.tmpdir</name> <value>/user/hive/warehouse</value> </property> <property> <name>system:user.name</name> <value>${user.name}</value> </property> <property> <name>hive.metastore.db.type</name> <value>mysql</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>user name for connecting to mysql server</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password for connecting to mysql server</description> </property>
2.3创建目录:
hadoop fs -mkdir -p /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
2.4替换低版本的guava.jar文件,否则初始化时会报错:
错误一:Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
原因:hadoop和hive的两个guava.jar版本不一致 两个位置分别位于下面两个目录: - /usr/local/hive/lib/ - /usr/local/hadoop/share/hadoop/common/lib/
解决办法: 除低版本的那个,将高版本的复制到低版本目录下
2.5删除hive-site.xml中的特殊字符,否则初始化时会报如下错误:
错误二:Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8 at [row,col,system-id]: [3224,96,"file:/app/hive-3.1.2/conf/hive-site.xml"] 原因: hive-site.xml配置文件中,3224行有特殊字符 解决办法: 进入hive-site.xml文件,跳转到对应行,删除里面的特殊字符即可
2.6上次jdbc驱动至hive/lib目录下,否则会报如下错误:
错误三:
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
Underlying cause: java.lang.ClassNotFoundException : com.mysql.jdbc.Driver
原因:缺少jdbc驱动
解决办法:上传jdbc( mysql-connector-java-5.1.36-bin.jar )驱动到 hive的lib下
2.7初始化hive
schematool -dbType mysql -initSchema
2.8启动 metastore服务 (不启用会报:HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient。)
./hive --service metastore &
2.9进入hive
hive
注意如果insert时卡住不能向下执行,查看日志(hive的日志文件在:/tmp/{user.name}下)一直在连接8032端口,则是MR没有启动
在命令行输入:hadoop classpath

将内容,添加至yarn-site.xml中
<property> <name>yarn.application.classpath</name> <value>/app/hadoop-3.2.1/etc/hadoop:/app/hadoop-3.2.1/share/hadoop/common/lib/*:/app/hadoop-3.2.1/share/hadoop/common/*:/app/hadoop-3.2.1/share/hadoop/hdfs:/app/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/app/hadoop-3.2.1/share/hadoop/hdfs/*:/app/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/app/hadoop-3.2.1/share/hadoop/mapreduce/*:/app/hadoop-3.2.1/share/hadoop/yarn:/app/hadoop-3.2.1/share/hadoop/yarn/lib/*:/app/hadoop-3.2.1/share/hadoop/yarn/*</value> </property>
启动 yarn,start-yarn.sh。
3.hive创建表:
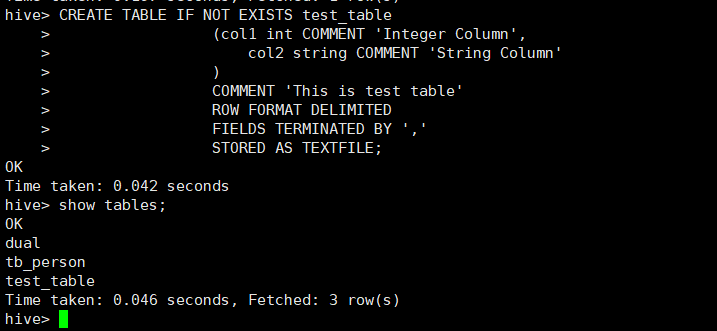
#创建表
hive> CREATE TABLE IF NOT EXISTS test_table
> (col1 int COMMENT 'Integer Column',
> col2 string COMMENT 'String Column'
> )
> COMMENT 'This is test table'
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> STORED AS TEXTFILE;
OK
Time taken: 0.042 seconds
hive> show tables;
OK
dual
tb_person
test_table
Time taken: 0.046 seconds, Fetched: 3 row(s)
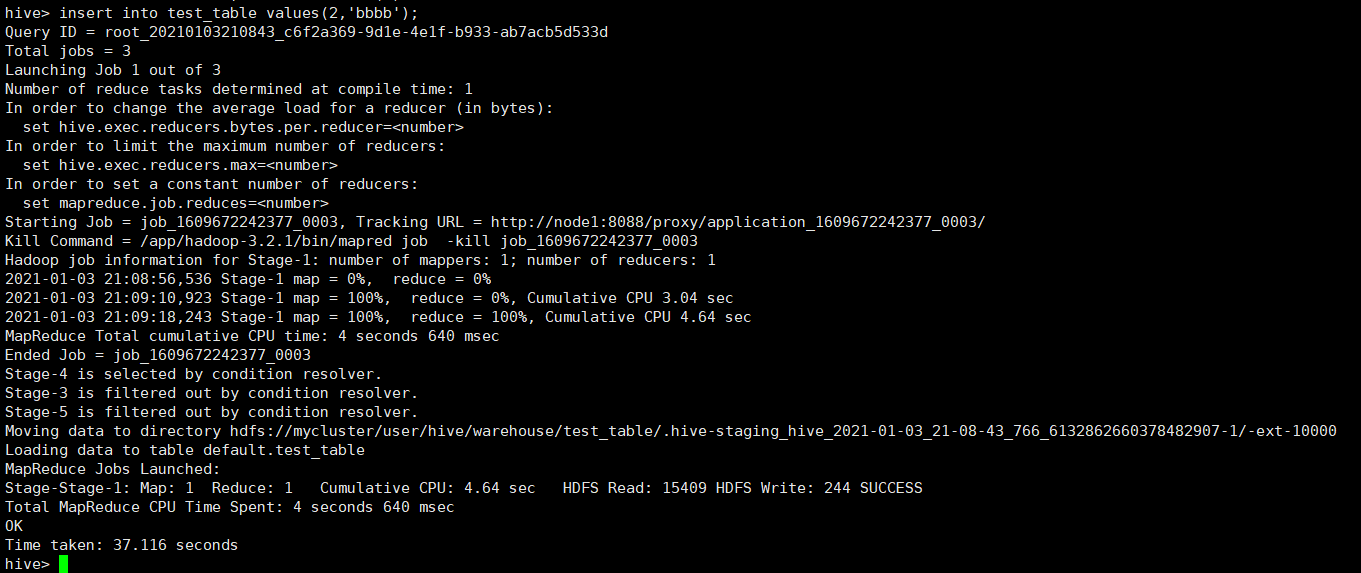
#写入
hive> insert into test_table values(2,'bbbb');
Query ID = root_20210103210843_c6f2a369-9d1e-4e1f-b933-ab7acb5d533d
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1609672242377_0003, Tracking URL = http://node1:8088/proxy/application_1609672242377_0003/
Kill Command = /app/hadoop-3.2.1/bin/mapred job -kill job_1609672242377_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-01-03 21:08:56,536 Stage-1 map = 0%, reduce = 0%
2021-01-03 21:09:10,923 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.04 sec
2021-01-03 21:09:18,243 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.64 sec
MapReduce Total cumulative CPU time: 4 seconds 640 msec
Ended Job = job_1609672242377_0003
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://mycluster/user/hive/warehouse/test_table/.hive-staging_hive_2021-01-03_21-08-43_766_6132862660378482907-1/-ext-10000
Loading data to table default.test_table
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.64 sec HDFS Read: 15409 HDFS Write: 244 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 640 msec
OK
Time taken: 37.116 seconds
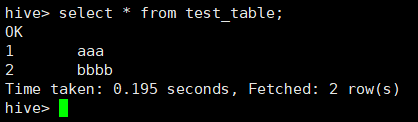
#查询
hive> select * from test_table;
OK
1 aaa
2 bbbb
Time taken: 0.195 seconds, Fetched: 2 row(s)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号