
hive初始
什么是Hive
Hive本身是数据仓库。
数据仓库是为了协助分析报告,支持决策,为需要业务智能的企业提供业务流程的改进和指导,从而节省时间和成本,提高质量。它与数据库系统的区别是,数据库系统可以很好地解决事务处理,实现对数据的“增、删、改、查”操作,而数据仓库则是用来做查询分析的数据库,通常不会用来做单条数据的插入、修改和删除。
Hive作为一个数据仓库工具,非常适合数据的统计分析,它可以将数据文件组成表格并具有完整的类SQL查询功能,还可将类SQL语句自动转换成MapReduce任务来运行。因此,如果使用Hive,可以大幅提高开发效率。
和传统的数据仓库一样,Hive主要用来访问和管理数据。与传统数据仓库较大的区别是,Hive可以处理超大规模的数据,可扩展性和容错性非常强。由于Hive有类SQL的查询语言,所以学习成本相对比较低。
Hive和数据库的异同
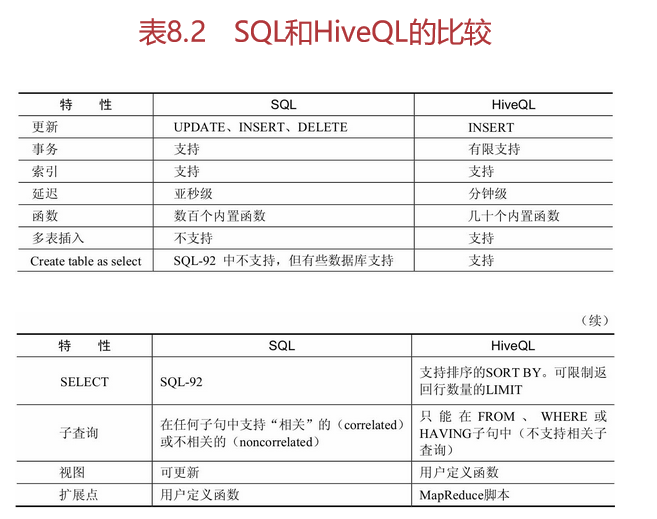
Hive采用了类SQL的查询语言HQL(Hive Query Language),其实,HQL的引入仅仅是为了降低学习成本,底层还是MapReduce。Hive本身是数据仓库,并不是数据库系统
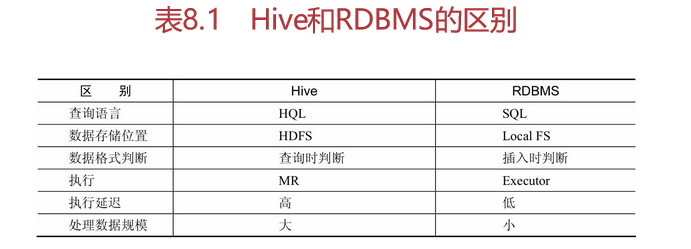
Hive和数据库的主要区别在查询语言、存储位置、数据格式、数据更新、索引、执行、执行延迟、可扩展性和数据规模几方面,详见表8.1所示。
1.数据存储位置
在数据存储位置方面来说,数据库是将数据存储在块设备或本地文件系统中。而Hive是将所有数据存储在HDFS中,并建立在Hadoop之上。
2.数据格式
在Hive中,并没有定义特有的数据格式,数据格式是由用户指定,用户在定义数据格式时需要指定3个属性,分别是列分隔符,比如通常为空格、\t、\x001,行分隔符,如“\n”,以及读取文件数据的方法。因为在加载数据的过程中,不需要从用户数据格式到Hive本身定义的数据格式中进行转换,所以,在Hive加载的过程当中不会对数据本身做任何调整,而只是将数据内容本身复制到了相应的HDFS目录中。而在传统的数据库中,由于不同的数据库有不同的存储引擎,各自定义了自己的数据格式,全部的数据都会按照一定的组织结构进行存储,因此数据库在加载数据的过程中会比较耗时。
3.数据更新
前面提到,Hive本身是针对数据仓库而设计的,同时,由于数据仓库的内容往往是读多写少。所以Hive中不支持对数据的修改和增加,所有的数据都是在加载的过程中完成的。而数据库中的数据往往需要经常进行修改、查询、增加等操作。
4.索引
在索引方面,Hive在加载数据的过程中不会对数据做任何处理,也不会对数据进行扫描处理,所以也没有对数据中的某些键值创建索引。在Hive访问数据中满足条件的数据值时,需要扫描全部数据,由此造成的访问延迟较高。由于HQL最终会转化成MapReduce,因此Hive可以并行访问数据,即使在没有索引的情况下,对于大批量数据的访问,Hive仍可以表现出优势。在数据库中,通常会针对某一列或者某几列创建索引,所以对于少批量的满足特定条件的数据访问,数据库具有很高的效率,以及较低的延迟。因此,Hive数据访问的延迟较高,不适合在线查询数据。
5.执行
关于执行,前面提到Hive中大多数查询的执行最终是通过MapReduce来实现的。而数据库则具有自己的执行引擎。
6.执行延迟
由于Hive在查询数据的时候并没有索引,需要扫描整个表,由此造成的延迟较高,同时,由于MapReduce自身具有较高的延迟,也会导致查询延迟。相比较来说,在数据量规模小的情况下数据库的执行延迟较低。只有当数据规模大到超过数据库的处理能力的时候,Hive的并行计算优势才能体现出来。
7.可扩展性
Hive与Hadoop的可扩展性是一致的,原因是Hive本身是建立在Hadoop之上的。而数据库由于ACID语义的严格限制,扩展行非常有限。
8.处理数据规模
由于Hive建立在集群上,同时可以基于MapReduce进行并行计算,所以可以支撑大规模的数据,而数据库可以支撑的数据规模相对较小。
Hive设计的目的与应用
前面已经提到,Hive的设计目的是让那些熟悉SQL但编程技能相对比较薄弱的分析师可以对存放在HDFS中的大规模数据集进行查询。目前,Hive已经是一个非常成功的Apache项目,很多组织把它用作一个通用的、可伸缩的数据处理平台。
Hive主要应用于传统的数据仓库任务ETL(Extract‐Transformation‐Loading)和报表生成。其中,报表生成中可以完成大规模数据分析和批处理的任务,进行海量数据离线分析和低成本进行数据分析,可以应用于日志分析,如统计网站一个时间段内的PV、UV,以及多维度数据分析等。大部分互联网公司使用Hive进行日志分析,包括百度、淘宝等。
Hive的运行架构
Hive的用户接口主要有3个,分别是CLI(Command Line)、Client和WUI。其中CLI是最常用的。
在CLI启动时,一个Hive的副本也会随之启动。Client,顾名思义是Hive的客户端,用户会连接至Hive Server,在启动Client模式时,需要指出Hive Server在哪个节点上,同时在该节点启动Hive Server。WUI则是通过浏览器来访问Hive。
HiveServer是Hive的一种实现方式,客户端可以对Hive中的数据进行相应操作,而不启动CLI,HiveServer和CLI两者都允许远程客户端使用Java、Python等多种编程语言向Hive提交请求,并取回结果。
下面我们根据Hive的运行架构图解释一下Hive的体系结构,如图8.1所示。
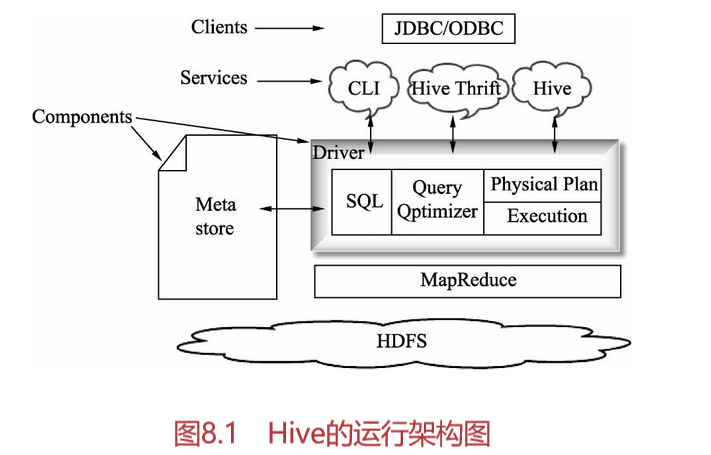
在图8.1中,Metastore主要用来存储元数据,Hive是将元数据存储在数据库中,如MySQL、derby。在Hive中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等。
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化到查询计划的生成。生成的查询计划存储在HDFS中,并在随后用MapReduce调用执行。
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成。
Hive的执行流程
在Hive上执行查询时,整体流程大致步骤如下:
(1)用户提交查询任务到Driver。
(2)编译器Compiler获得用户的任务计划。
(3)编译器Compiler根据用户任务从Metastore中得到所需的Hive元数据信息。
(4)编译器Compiler对任务进行编译,首先将HQL转换为抽象语法树,接着把抽象语法树转换成查询语句块,并将查询语句块转化为逻辑的查询计划。
(5)把最终的计划提交到Driver。
(6)Driver将计划提交到Execution Engine,获得元数据信息,接着提交到JobTracker或者Source Manager运行该任务,该任务会直接从HDFS中读取文件并进行相应的操作。
(7)取得并返回执行结果。
Hive服务
Hive的Shell环境仅仅是Hive命令提供的一项服务。我们可以在运行时使用--service选项指明要使用哪种服务。同时,通过输入hive--service help可以获得可用服务列表。下面介绍一些常用服务。
1.CLI(Common Line Interface)服务
前面我们说过,CLI是Hive的命令行接口,也就是Shell环境。CLI启动的时候会同时启动一个Hive的副本,这也是默认的服务。我们可以通过bin/hive或bin/hive--service cli命令来指出Hive Server所在的节点,并且在该节点启动Hive Server。
2.HiveServer2服务
通过Thrift提供的服务(默认端口是10000),客户端就可以在不启动CLI的情况下对Hive中的数据进行操作了,并且允许用不同语言如Java、Python语言编写的客户端进行访问。使用Thrift、JDBC和ODBC连接器的客户端需要运行Hive服务器来和Hive进行通信。
3.HWI(Hive Web Interface)服务
HWI是通过浏览器访问Hive的方式,它是Hive的Web接口,默认端口是9999。在没有安装任何客户端软件的情况下,这个简单的Web接口可以代替CLI。另外,HWI是一个功能更全面的Hadoop Web接口,其中包括运行Hive查询和浏览Hivemestore的应用程序。命令为bin/hive--service hwi。
4.MetaStore服务
负责元数据服务Metastore和Hive服务运行在同一个进程中。使用这个服务,可以让Metastore作为一个单独的进程来运行。通过设置METASTORE_PORT环境变量可以指定服务器监听的端口号。
元数据存储Metastore
Metastore是Hive集中存放元数据的地方。Metastore包括两部分:服务和后台数据的存储。Hive有3种Metastore的配置方式,分别是内嵌模式、本地模式和远程模式。
内嵌模式使用的是内嵌的Derby数据库来存储数据,配置简单,但是一次只能与一个客户端连接,适用于做单元测试,不适用于生产环境。
本地模式和远程模式都采用外部数据库来存储数据,目前支持的数据库有MySQL、Oracle、SQL Server等,在这里我们使用MySQL数据库。本地元存储和远程元存储的区别是本地元数据不需要单独启动Metastore服务,因为本地元存储用的是和本地Hive在同一个进程里的Metastore服务。
在默认的情况下,Metastore服务和Hive服务运行在同一个虚拟机中,它包含一个内嵌的以本地磁盘作为存储的Derby数据库实例,被称之为“内嵌Metastore配置”。
下面分别介绍内嵌模式、本地模式和远程模式,如图8.2所示。
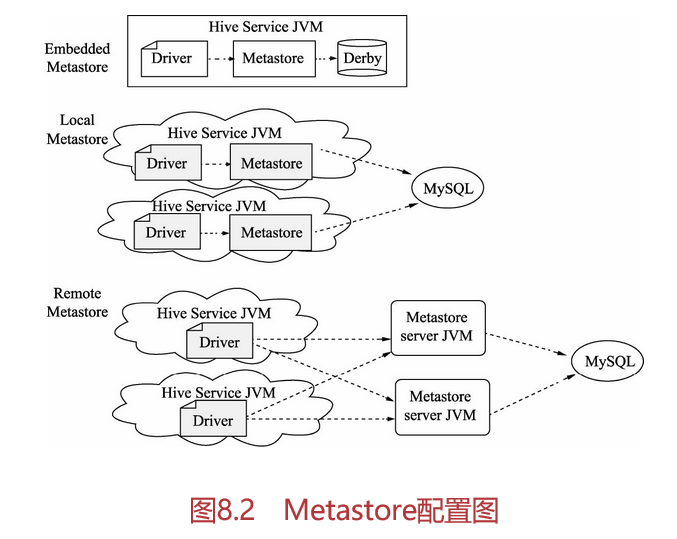
Embedded模式
Embedded模式连接到一个In-memory的数据库Derby,一般用于单元测试,如图8.3和表8.3所示。
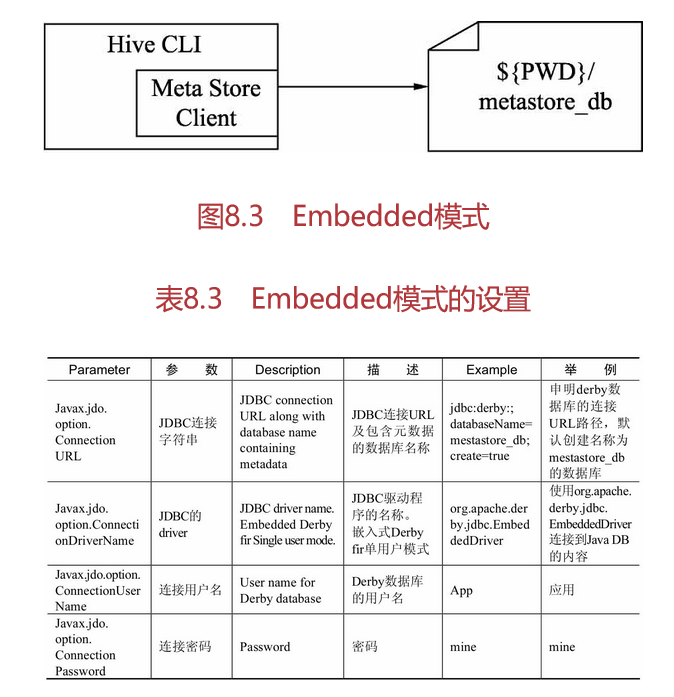
Local模式
Local模式通过网络连接到一个数据库中,是经常使用的模式,如图8.4所示。

Remote模式
Remote模式用于非Java客户端访问元数据库,在服务器端会启动MetaStoreServer,客户端通过Thrift协议及MetaStoreServer来访问元数据库,如图8.5和表8.5所示。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号