Hadoop综合大作业总评
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
1、把python爬取的数据传到linux
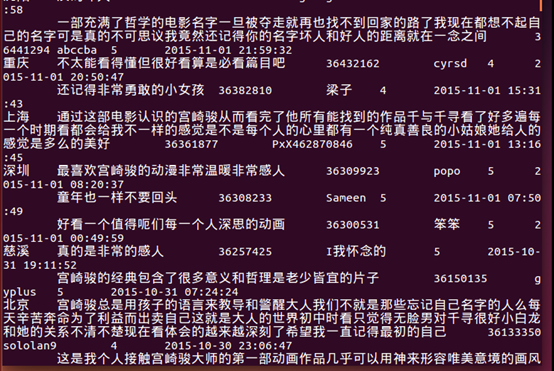
2、把数据的逗号代替为 \t转义字符
3、启动hadoop集群

4、启动hive

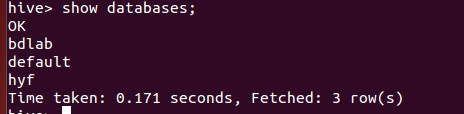
5、创建数据库

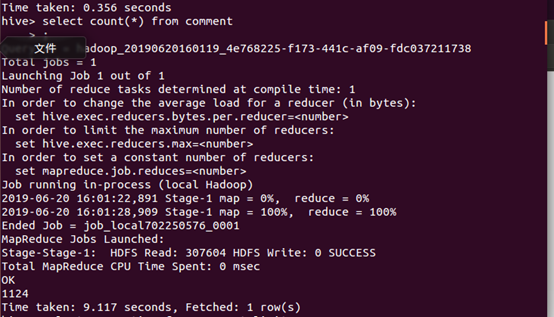
6、创建表并把hdfs的数据导入表中

7、统计数据一共有1124条
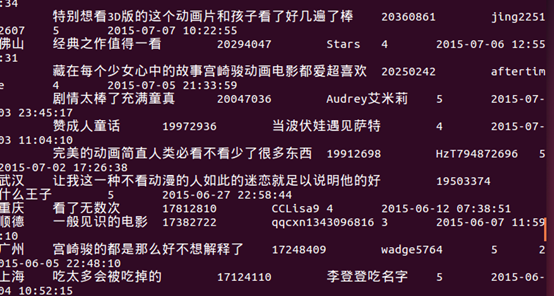
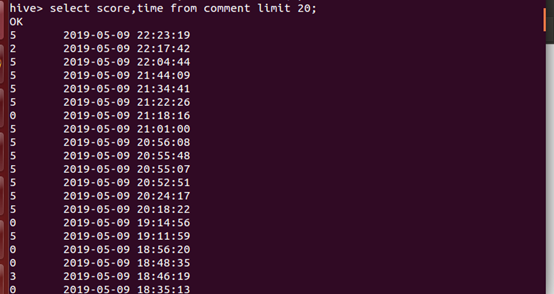
8、列出前20名观众分数和时间
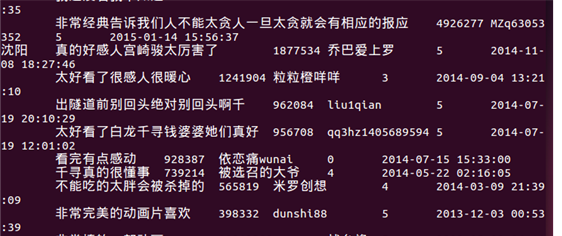
9、列出前20名观众的评论
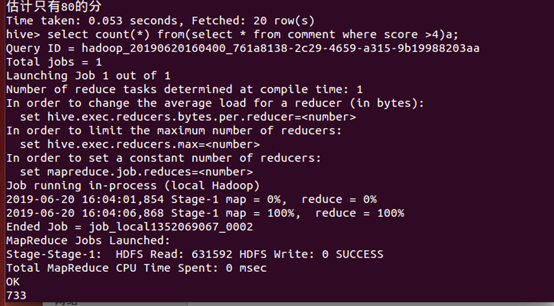
10、统计评论分数大于4分(总5分)的评论条数,大部分是大于4分,说明
《千与千寻》的好评率很高。
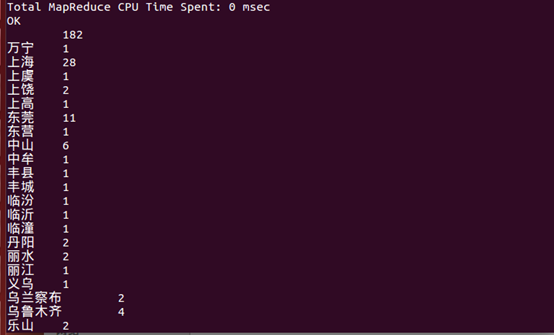
11、列出各城市的评论数
12、统计北京的评论数
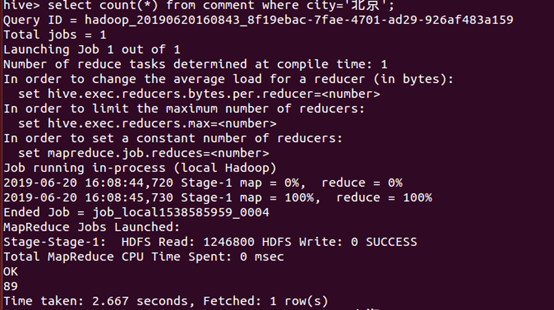
13、统计上海的评论数
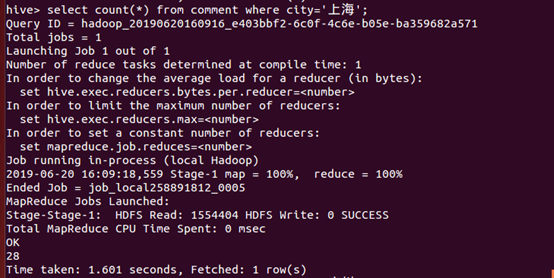
14、统计广州的评论数
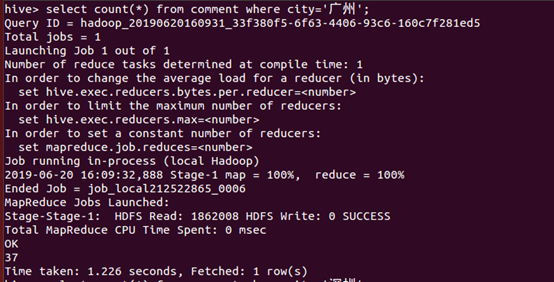
15、统计深圳的评论数
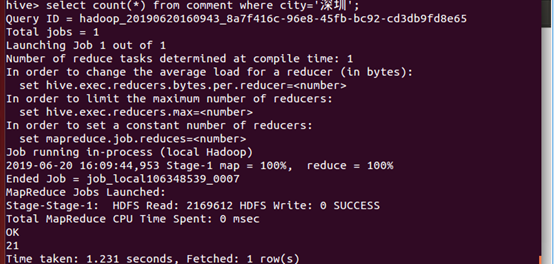
、、、、、
本作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3310
利用Shell命令与HDFS进行交
1.目录操作:
(1)、在HDFS中为hadoop用户创建一个用户目录(hadoop用户):

(2)、在用户目录下创建一个input目录

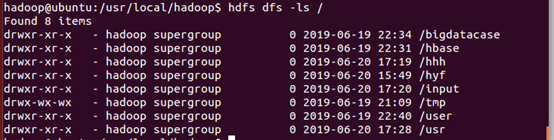
(3)、在HDFS的根目录下创建一个名称为input的目录
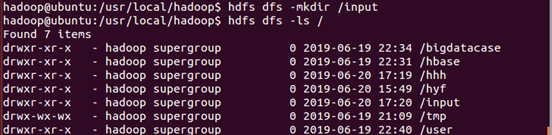
(4)、删除HDFS根目录中的“input”目录:

2.文件操作:
posted on 2019-06-20 17:10 hyf751190951 阅读(216) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号