并发编程
并发编程
一:理论知识扫盲
1.操作系统:负责管理协调硬件,提供系统调用接口给应用程序。
2.操作系统工作在内核态,应用程序工作在用户态,应用程序无法直接操作硬件,通过os简介调用硬件。
总结:os隐藏了硬件接口,方便程序员开发;将硬件资源的调度变得有序化.
#一 操作系统的作用: 1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口 2:管理、调度进程,并且将多个进程对硬件的竞争变得有序 #二 多道技术: 1.产生背景:针对单核,实现并发 ps: 现在的主机一般是多核,那么每个核都会利用多道技术,但是核与核之间没有使用多道技术切换这么一说; 有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个cpu中的任意一个,具体由操作系统调度算法决定。
2.空间上的复用:把程序在内存上物理级别上的隔离开。作为一旦调度单元进出cpu 3.时间上的复用(复用一个cpu的时间片)+空间上的复用(如内存中同时有多道程序)
3.同步:
发出功能调用后,没有得到结果之前,该调用就不会返回。之前的函数都是同步的,但是一般说的同异步是多个部件协调时的协作状态,不针对一个组件而言。
同步说的是逻辑上面的,一般线程不会挂起
4.异步:
异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立刻得到结果,继续向下执行。
当该异步功能完成后,通过状态、通知或回调来通知调用者。
如果异步功能用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低
有些初学多线程编程的人,总喜欢用一个循环去检查某个变量的值,这其实是一 种很严重的错误。
如果是使用通知的方式,效率则很高,因为异步功能几乎不需要做额外的操作。
至于回调函数,其实和通知没太多区别。
5.阻塞:
指调用结果返回之前,当前线程会被挂起(如遇到io操作)。函数只有在得到结果之后才会将阻塞的线程激活。
有人也许会把阻塞调用和同步调用等同起来,实际上是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。
6.非阻塞:
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程。
7.进程
无论哪一种,新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的:
1. 在UNIX中该系统调用是:fork,fork会创建一个与父进程一模一样的副本,二者有相同的存储映像、同样的环境字符串和同样的打开文件(在shell解释器进程中,执行一个命令就会创建一个子进程)
2. 在windows中该系统调用是:CreateProcess,CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
二:进程
需要掌握
- 开启进程的方法
- 父进程子进程,每个进程都有PID进程号来作为标识
- 父进程等待所有子进程结束后结束,为了回收资源
- 进程的开启过程中,win和linux的区别join方法,是把进程结束的事件封装成了一个方法,那么父进程在子进程结束的时候响应此事件继续向下执行.
只要不想被子进程执行的代码,就写在if __name__=="__main__"下,因windows平台下,子进程需要的数据是通过import父进程的py文件来拷贝数据的,否则就会循环导入.
linux下就不需要这样了
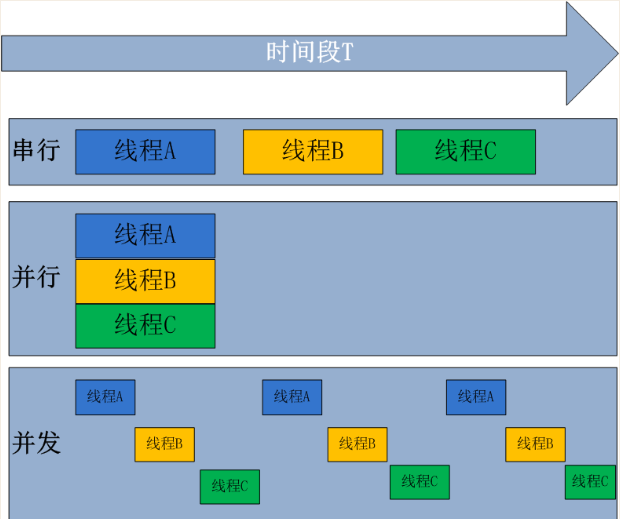
串行:一个挨着一个执行,之前写的代码都是串行.
并行:程序数=cpu数,一个程序占一个,几乎没有这样的.
并发:程序数>>>>>cpu数,看起来在同时执行,cpu在多个程序中切换.
同步阻塞:A函数调用B函数,而B函数需要去远程连接数据库等IO,A函数要拿到数据库的连接才能继续运行只能同步等待,A同步阻塞.
同步非阻塞:A函数调用B函数,A函数继续向下执行需要B函数的结果,但A函数没有IO操作,A是同步非阻塞
异步阻塞:A函数调用B函数,不等待B函数的执行,依旧向下执行,但是A函数里面有IO操作,A异步阻塞.
异步非阻塞:A函数调用B函数,不等待B函数的执行结果,且没有IO操作.A异步非阻塞.
这四种组合是程序不同时间段的不同状态,状态不会一直保持,而是时刻变化.
总结:阻塞非阻塞和同步异步没有直接关系,都是相对而言的.不能单独说一个函数就是某一种状态,而是某一时刻的状态.
二:守护进程
主进程代码结束,并不意味着主进程结束,因为主进程要等待子进程的结束之后才会结束.
只要主进程代码执行结束,守护进程立马结束,不会跟着主进程等待子进程结束之后才结束
和其他子进程唯一的区别就是,start()之前将p.daemon=True即可.
import time from multiprocessing import Process def fnc(): while True: time.sleep(0.2) print("i am alive") if __name__ == "__main__": p = Process(target=fnc) p.daemon = True # 将p进程设置为守护进程 #此时主进程不会等守护进程,主进程结束,守护进程立马结束,不再工作 #开进程的目的是为了并发执行任务,守护进程执行的任务在主进程执行结束立马就结束没有存在的必要 #当一个进程伴随主进程的结束他就没有意义的时候就应该设置为守护进程 p.start() i = 0 while i < 3: print(i) time.sleep(1) i += 1
三:multiprocessing
Process类详解
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
1参数介绍
1 group参数未使用,值始终为None 2 3 target表示调用对象,即子进程要执行的任务 4 5 args表示调用对象的位置参数元组,args=(1,2,'egon',) 6 7 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18} 8 9 name为子进程的名称
2常用方法
1 p.start():启动进程,并调用该子进程中的p.run() 2 p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法 3 4 p.terminate():异步非阻塞交给操作系统去强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。 如果p还保存了一个锁那么也将不会被释放,进而导致死锁 5 p.is_alive():如果p仍然运行,返回True 6 7 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间, 需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
3属性
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可
四:不同操作系统下子进程
win系统下,子进程靠import父进程文件来拿到数据和代码,如果没有if __name__="__main__"就会循环import
linux是拷贝父进程存在的变量,不是靠执行代码获取变量,直接拷贝父进程中存在的变量
五:进程之间的通信
基于文件或者基于网络
同一台电脑多进程通信基于文件
多台电脑之间通信基于网络
IPC,Queue,Manager底层都是socket,基于的文件,基本用不到,计算密集型不适合python,直接转go
存在一定有意义,但不一定合理,会有更优的方案.
六:join
阻塞直到子进程结束,谁调用的join方法就等谁,常用在主进程里面等待子进程的结束信号.
子进程结束之后才会继续执行主进程的代码
join()是同步阻塞了.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号